




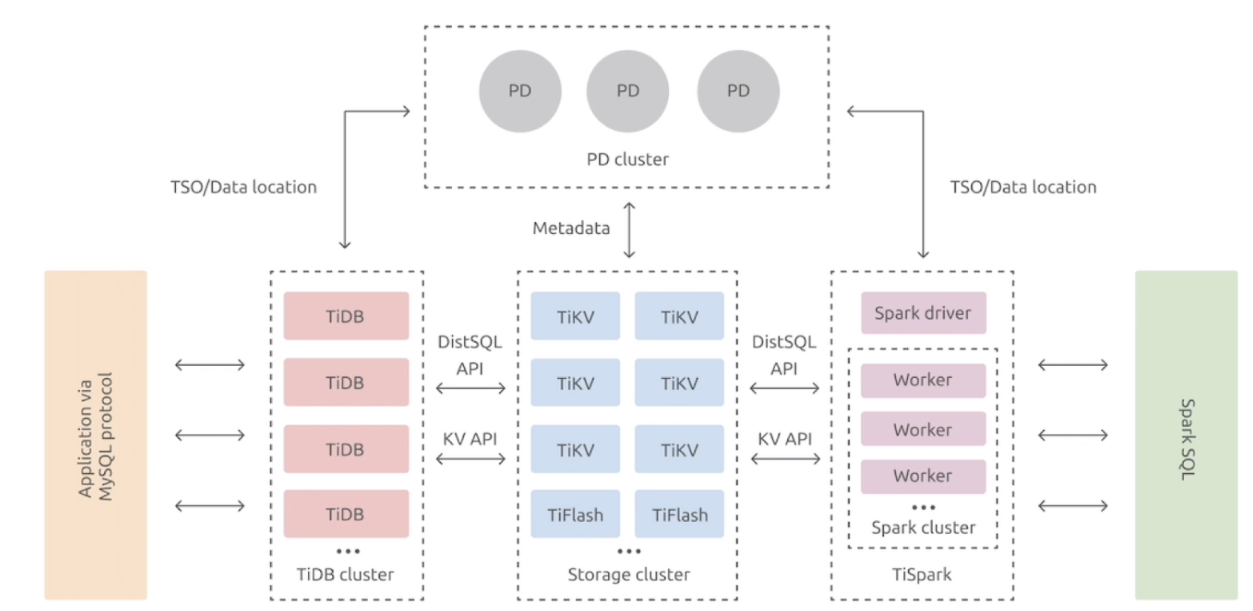
TiDB 数据库的整体架构
TiKV 的主要功能与架构


RocksDB
RocksDB 针对 Flash 存储进行优化,延迟极小,使用 LSM 存储引擎。
- 高性能的 Key-Value 数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储 TB 级别数据到本地 FLASH 或者 RAM 的应用服务器设计
- 针对存储在高速设备的中小键值进行优化–可以存储在 FLASH 或者直接存储在内存
- 性能随 CPU 数量线性提升,对多核系统友好
RocksDB - 写入
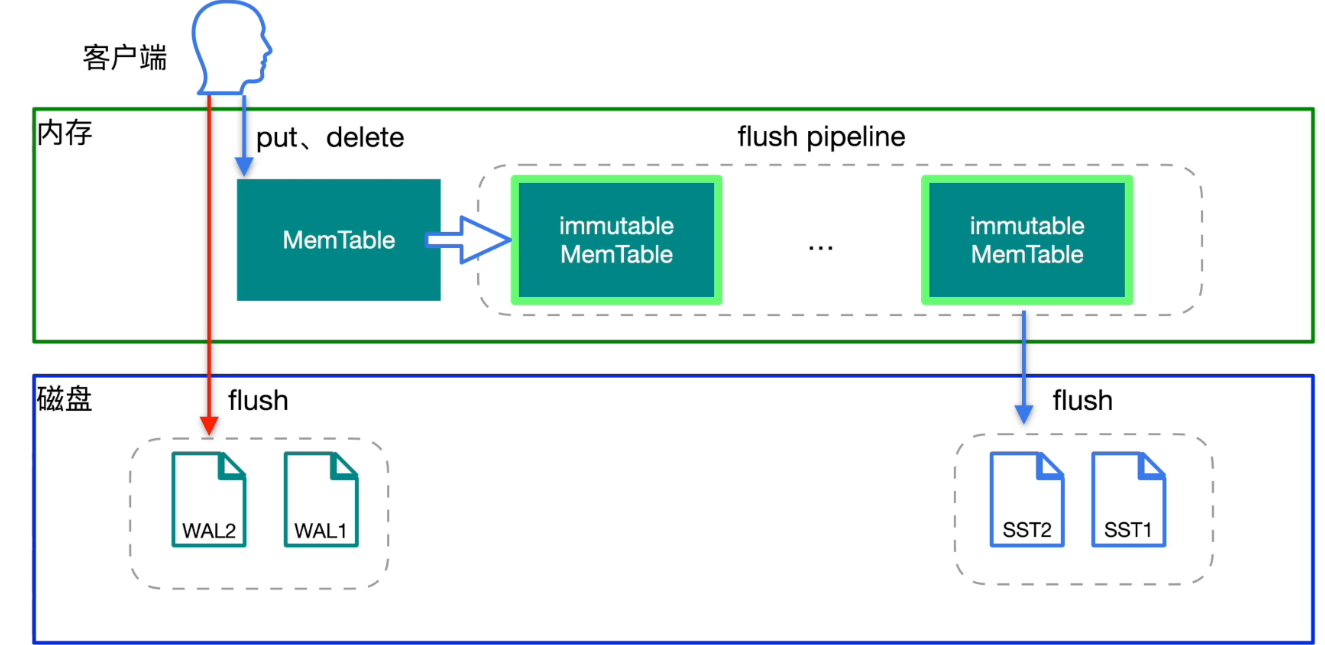
- sync_log = true ,数据直接写入到 WAL 日志中,而不经过操作系统缓存,防止掉电数据丢失
- write_buffer_size ,当 MemTable 的存储大小达到这个参数值,就会将 MemTable 转存到 immutable MemTable
- immutable MemTable 默认达到5个,就会触发流控 write stall,限制写入 MemTable 的速度,同时会在日志中记录 write stall,客户端会感应到写入速度变慢

- Level 0 存储的就是 immutable MemTable,当 Level 0 存储了4个 immutable MemTable 以后会向 Level 1 做 compaction,就是这个4个 immutable MemTable 合并成一个 SST 文件,合并的同时会做压缩和对 Key 的排序。
- 当 Level 1 的大小达到 256M 以后继续向 Level 2 做合并,以此类推。
RocksDB - 查询

- Block Cache:将最近最常读的数据缓存到 Block Cache 中。
- 每个 SST 文件都有最大和最小Key,而且是已经排好序的,所以查询的时候就可以通过 Key 的最大和最小值定位文件,当定位到一个文件后使用二分查找法来查询具体数据
- 为了加速查询,每个 SST 文件还引入了布隆过滤器,如果布隆过滤器返回查找的元素在这个文件中,那么这个元素有可能不在这个文件中,布隆过滤器是有误识别率,但是布隆过滤器返回查找的元素不在这个文件中,那么这个元素就肯定不在这个文件中。
RocksDB - Column Families (列簇)

- RocksDB 的数据分片,不同的 Column Families 可以存储不同的表,每个 Column Families 存储同一类列数据。
- Column Families 共用 WAL 日志文件。
分布式事务
事务的流程

- begin:会向 PD 组件中获取一个时间戳,作为事务的开始时间 start_ts
- 将需要修改的数据读取到 TiDB Server 的内存中,在 TiDB Server 的内存中先进行修改
- 修改完成后,一旦事务遇到 commit 操作时,就需要将这个事务执行持久化,那么这个持久化过程就进入了两阶段的提交。
- 两阶段的第一个阶段是 prewrite 阶段,这个阶段是将内存中修改的数据和锁信息分别写入到 TiKV 节点的 Default 列簇中和 Lock 列簇中。
- 两阶段的第二个阶段会向 PD 组件中获取一个时间戳,作为事务的提交时间 commit_ts,在 TiKV 节点中的 Write 列簇中写入提交信息,在 Lock 列簇中删除锁信息,删除锁信息并不是清空锁的记录,而是写入一个删除锁的信息。
- 如果其他session想要读取这条被修改的记录,会先到 Write 列簇中查找这个记录最近的提交时间110,开始时间是100,然后使用3和100到 Default 列簇中找具体的数据值,如果在 Write 列簇中没有找到最近的提交信息,而在 Lock 列簇中找到了这个记录的锁,那么就会处于等待状态,说明其他会话正在修改这个值。
事务与列簇

- Write列: 当用户写入了一行数据时,如果该行数据长度小于255字节,那么会被存储 Write 列中,否则的话该行数
据会被存入到 Default 列中。 - Default列: 用于存储超过255字节长度的数据。
分布式事务

- Lock 中的@1代表 TiVK Node 2 这个锁不是主锁,主锁是 TiVK Node 1 上的,@1只是一个锁的指向。
- 在一个事务中,不管修改几行数据,只会在第一行上加主锁,其他行加的都是加的锁的指向,指向第一行的主锁。
- 在 Default 中写入数据时只写入新值,当其他session读取这条数据时,发现已经被修改,就只会读取新修改后的数据,不需要再往后读取了。

MVCC

事务一,已提交

事务二,未提交

- 在 Write 中看不到 1 和 4 的信息,在 Lock 中可以看到 1 和 4 的锁信息,1 加了一个 pk 的主锁,4 加了一个指向 1 的锁。
MVCC 的过程

- 读操作,在 Write 中找最近一次提交的记录(1,100),在 Default 中读取数据。
- 写操作,在 Lock 中找 1 是否有锁,如果发现锁就阻塞写入。


Raft 与 Multi Raft

- leader:管理者,处理所有客户端的读写请求
- follower:接收 leader 的日志同步数据
- Region 默认是96M,但不是固定的,当Region增加到144M就会分裂,当Region太小了就会合并
- Raft:一套 Region 是一个 raft group
- Multi Raft:多个 raft group
- 每个 Region 还会向 PD 节点汇报状态信息
Raft - 日志复制


- Propose 过程,收到客户端(例如 TiDB Server)的写入请求,将请求转变成 Raft 日志
- Append 过程,将 Raft 日志写入到本地的专门存 Raft 日志的 RocksDB 中进行持久化


- Replicate 过程,leader 节点将日志发送给 follower 节点,follower 节点将接收的日志写入到本地的专门存 Raft 日志的 RocksDB 中进行持久化并返回给 leader 节点写入成功的信息。

- Committed 过程,当大多数(超过一般以上) follower 节点返回写入成功的信息,leader 节点就认为数据写入成功。


- Apply 过程,将 Raft 日志真正的持久化写入到 RocksDB KV 中
Raft - Leader 选举

- election timeout:raft-election-timeout-ticks * raft-base-tick_interval
- candidate:Leader 候选者
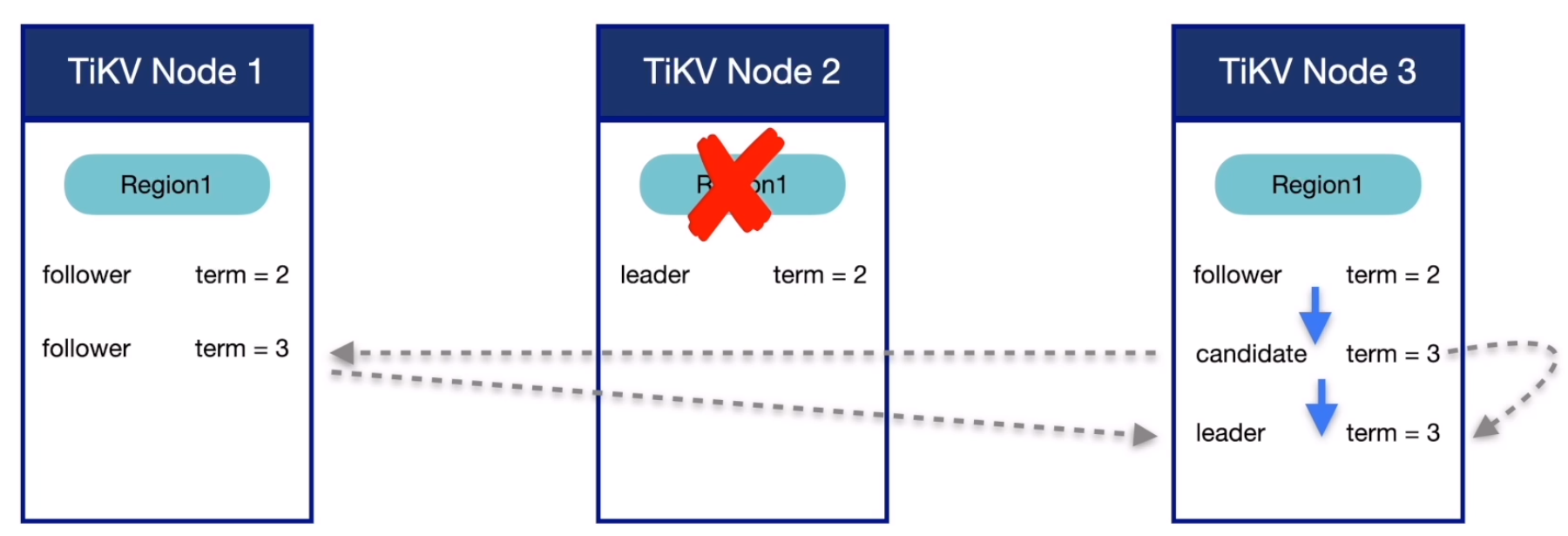
- heartbeat time iterval:raft-heartbeat-ticks * raft-base-tick_interval

数据的写入

数据的读取
ReadIndex Read


Lease Read


Follower Read



Coprocessor 协同处理器




TiKV 关键性能参数与优化
TiKV 数据写入流程

写入瓶颈分析

TiKV 写入参数优化

TiKV 数据读取流程


读取瓶颈分析

TiKV 读取参数优化

常见问题处理
Write Stall
由于 TiKV 中采用2个 RocksDB 作为 raft log 和 kv 数据的存储,所以当 memtalbe 或者 level 0 的数量过多时,RocksDB 就会对于写入进行减速,从而达到自我保护的目的,这个动作就叫做 write stall。

TiKV slow query

TiKV 常用监控指标
资源相关
- Grafana 监控 TiKV-Details --> Cluster - Store Size/Available Size

- Grafana 监控 TiKV-Details --> Cluster - Cluster - CPU/Memory/10 Util

- Grafana 监控 TiKV-Details --> Cluster - MBps/QPS

- Grafana 监控 TiKV-Details --> Cluster - Region/L eader

线程池相关
- Grafana 监控 TiKV-Details --> Thread CPU - gRPC poll CPU

- Grafana 监控 TiKV-Details -> Thread CPU - Unified read pool CPU

- Grafana监控TiKV-Details - > Thread CPU - Scheduler worker CPU

- Grafana 监控 TiKV-Details --> Thread CPU- Raft store CPU

- Grafana 监控 TiKV-Details --> Thread CPU - Async apply CPU

Duration 相关
- Grafana 监控 TiKV-Details --> gRPC - 99% gRPC message duration

- Grafana 监控 TiDB --> KV Request --> KV Request Duration 99 by type

- TiDB 写入流程

- Grafana 监控 TiKV-Details -> Scheduler-commit - Scheduler command duration
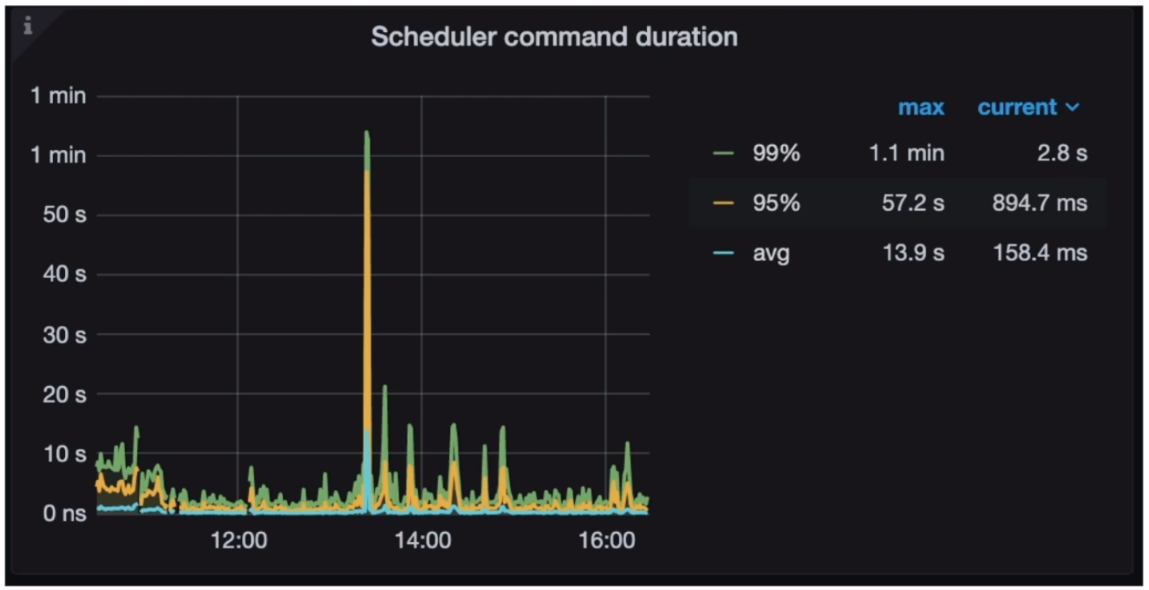
- Grafana 监控 TiKV-Details --> Scheduler-commit- Scheduler latch wait duration

- Grafana 监控 TiKV-Details --> Raft Propose - Propose wait duration

- Grafana 监控 TiKV-Details --> Raft I0 - Append log duration

- Grafana 监控 TiKV-Details --> Raft I0 - Commit log duration

- Grafana 监控 TiKV-Details --> Raft Propose - Apply wait duration

- Grafana 监控 TiKV-Details --> Raft I0 - Apply log duration

Error 相关
- Grafana 监控 TiKV-Details --> Errors - Server is busy

TiKV 的 OOM 问题诊断与处理
TiKV Server OOM 对业务的影响
- TiKV 上的请求失败造成异常退出
- region leader 重新选举
- raft group 开始选举新的 region leader
- 新的 region leader 上报信息给 PD Server
- region cache 频繁更新
- 在访问 TiDB Server 的 Region Cache 时,出现 TiKV rpc 相关报错
- 后台自动进行 Backoff 重试
- PD 将最新的 Region Leader 信息返回给 TiDB Server 的 Region Cache
TiKV Server OOM 的诊断方法
- 日志
- dmesg -T | grep tikv-server 结果中有事故发生附近时间点的 OOM-killer 的日志
- Tikv.log (事故发生后附近时间的 “Welcome to TiKV” 的日志<即 TiKV server 发生重启> )
- Grafana 监控
- TiKV - Details --> Cluster --> Memory

造成 TiKV Server OOM 的原因
- block-cache 配置不当导致 OOM
- Coprocessor 收到大量大查询,返回的数据量太大,gRPC 的发送速度跟不上 Coprocessor 往外输出数据的速度,导致OOM
- 其他进程占用太多内存
查看 block-cache 参数配置
- Grafana 监控 (TiKV-Details --> RocksDB KV --> Block cache size)
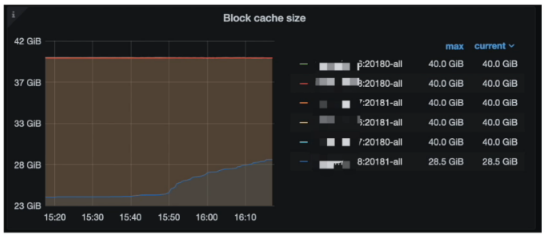
- 检查参数配置 storage.block-cache.capacity ( 45 % ~ 60 % )

调整 block-cache 参数配置
- 在线调整(试验性功能)
set config tikv storage.block-cache.capacity='8155MB';
Query OK, 0 rows affected (0.02 sec)
复制- 确认调整是否生效

gRPC 的发送速度跟不上 Coprocessor 处理
- TiKV-Details --> Coprocessor Overview --> Total Response Size

- Node_exporter --> Network --> Network IN/OUT Traffic

- SQL优化
- 针对集群中的SQL从业务逻辑以及SQL执行计划两个方面来进行优化
- 网卡配置升级
其他原因
- Raftstore数据写入环节内存占用高

- 目标服务器混布了其他组件且内存占用高
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
墨天轮福利君

3年前
评论
 0
0您好,您的文章已入选墨力原创作者计划合格奖,10墨值奖励已经到账请查收!
❤️我们还会实时派发您的流量收益。
3年前
点赞 评论
相关阅读
TiDB 社区第四届专栏征文大赛联合墨天轮火热开启!TiDB 业务场景实战、运维开发攻略两大赛道,重磅礼品等你来挑战!
墨天轮编辑部
446次阅读
2025-04-15 17:01:41
轻松上手:使用 Docker Compose 部署 TiDB 的简易指南
shunwahⓂ️
94次阅读
2025-04-27 16:19:49
APTSell x TiDB AutoFlow:AI 数字员工,助力销售业绩持续增长
PingCAP
60次阅读
2025-04-21 10:35:16
TiDB 社区第四届专栏征文大赛联合墨天轮火热开启,TiDB 业务场景实战、运维开发攻略两大赛道,重磅礼品等你来拿!
SQL数据库运维
56次阅读
2025-04-21 10:12:19
从单一到多活,麦当劳中国的数据库架构迁移实战
PingCAP
44次阅读
2025-04-18 10:01:03
从开源到全球认可:TiDB 在 DB-Engine 排名中的十年跃迁
韩锋频道
40次阅读
2025-04-24 09:53:42
卷疯了!众数据库厂商的征文汇
严少安
40次阅读
2025-04-23 02:19:36
TiDB 社区第四届专栏征文大赛联合墨天轮火热开启,TiDB 业务场景实战、运维开发攻略两大赛道,重磅礼品等你来拿!
小周的数据库进阶之路
39次阅读
2025-04-16 10:33:58
PingCAP“一号员工”唐刘:回顾我与 TiDB 的十年成长之旅
PingCAP
36次阅读
2025-04-22 10:12:18
TiDB 亮相 CHIMA 2025,助力医疗一栈式数据底座打造
PingCAP
31次阅读
2025-05-13 09:39:22



TA的专栏
目录
