




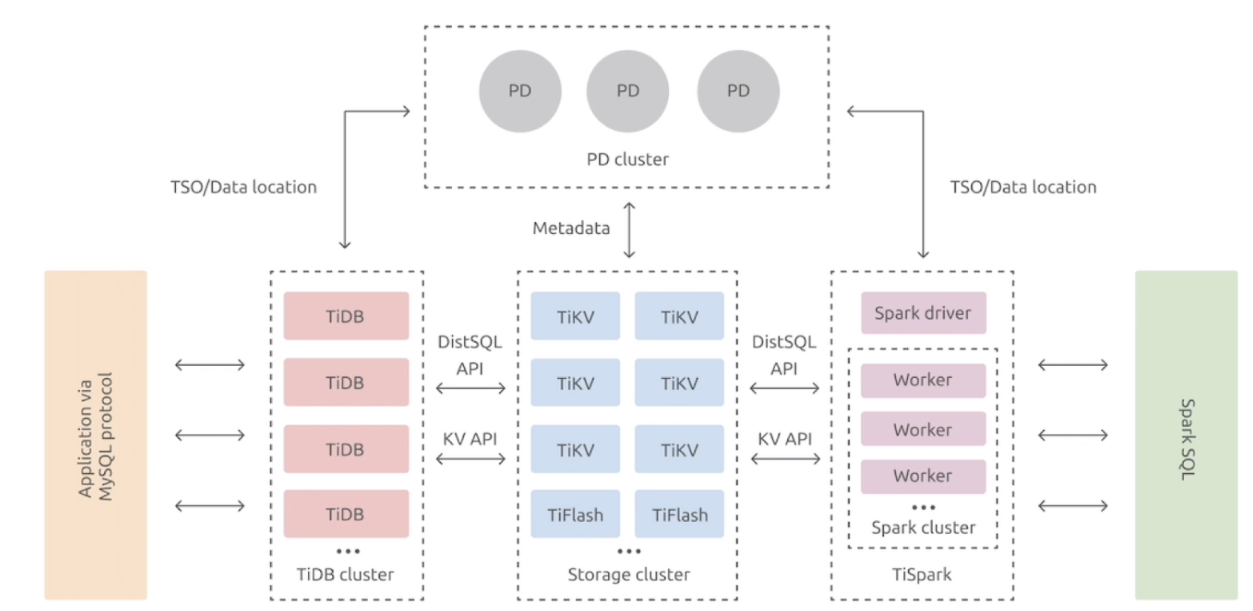
TiDB 数据库的整体架构
PD 的主要功能与架构
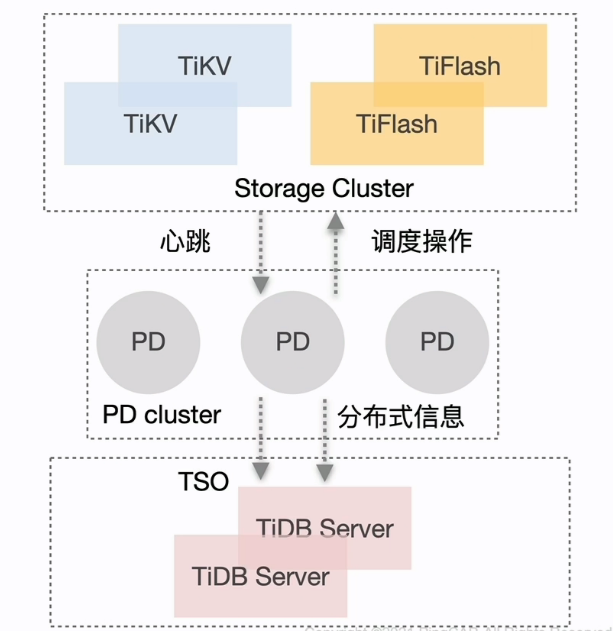
PD 的主要功能
- 整个集群 TiKV 的元数据存储
- 分配全局 ID 和事务 ID
- 生成全局时间戳 TSO
- 收集集群信息进行调度
- 提供 label 功能支持高可用
- 提供 TiDB Dashboard 服务
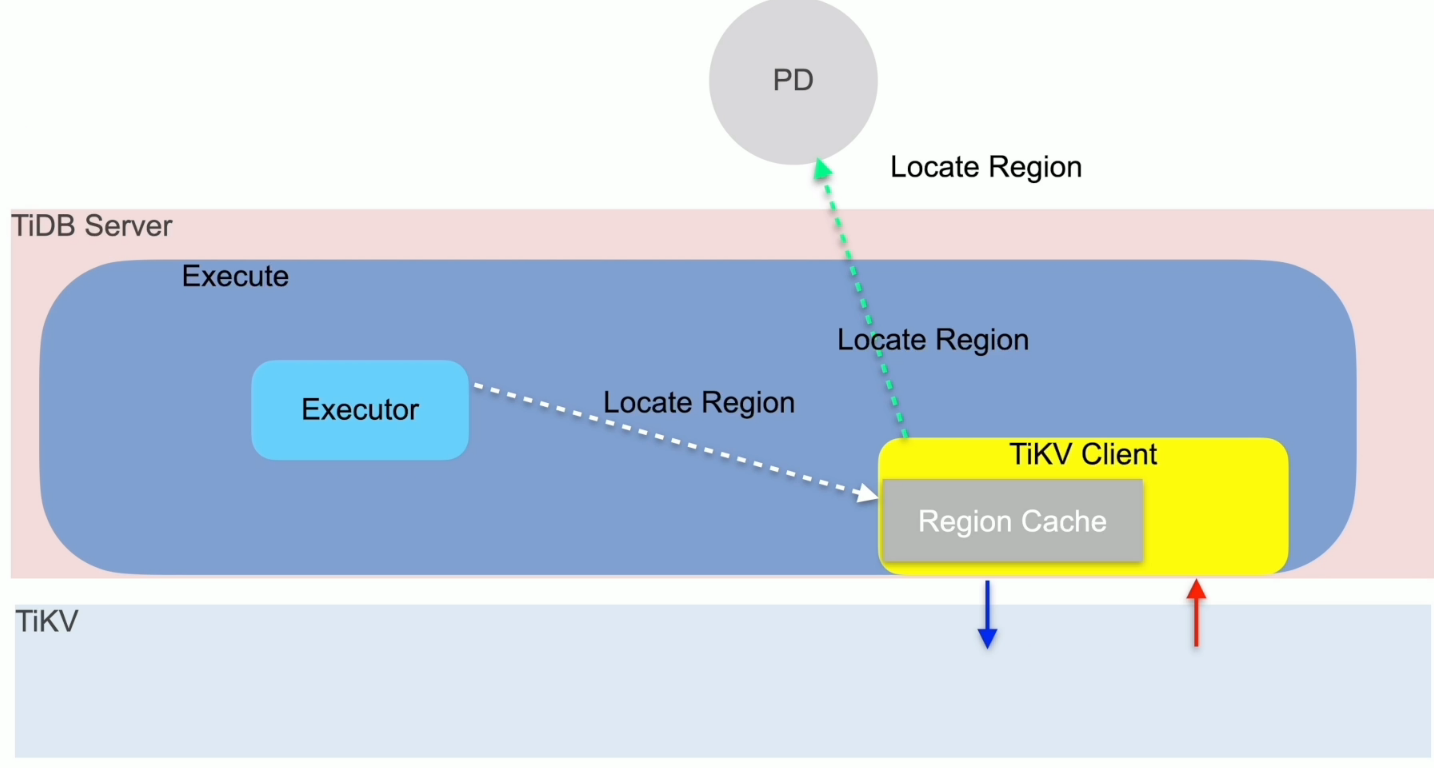
路由功能
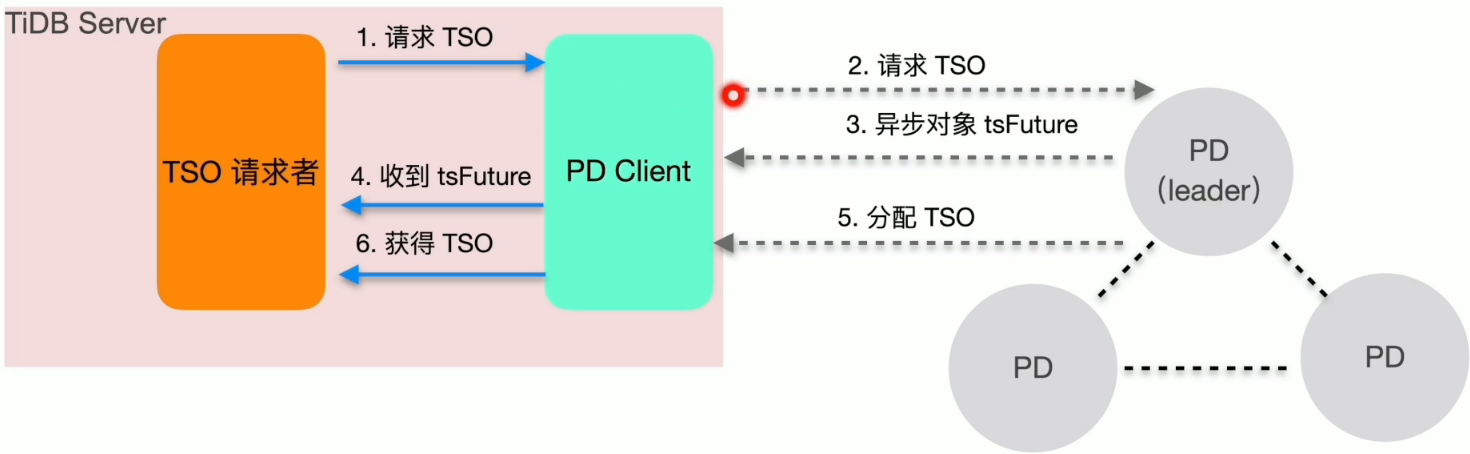
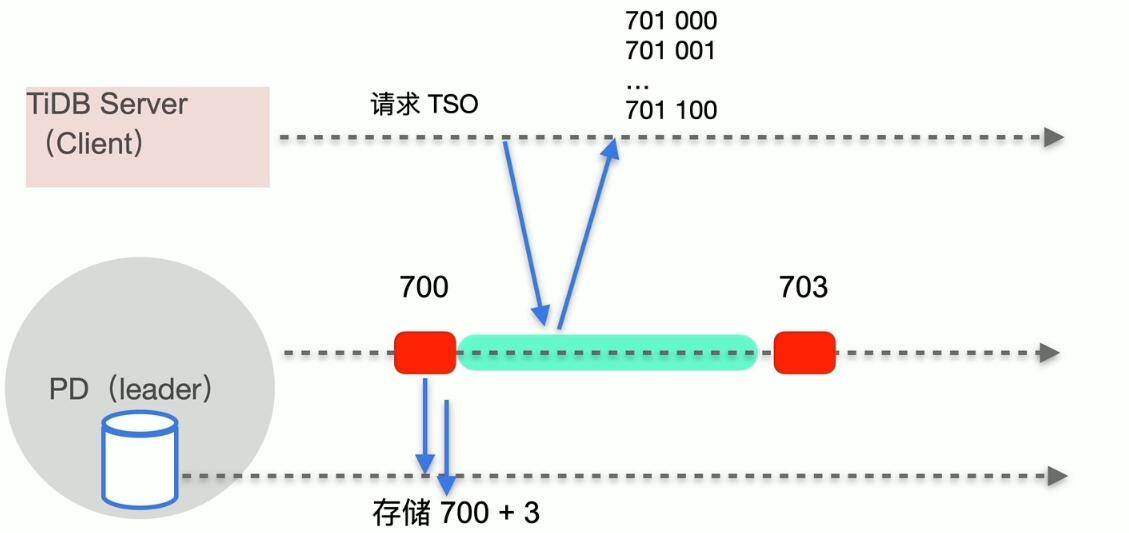
TSO 分配
TSO = physical time + logical time
- 获取流程
- 时间窗口
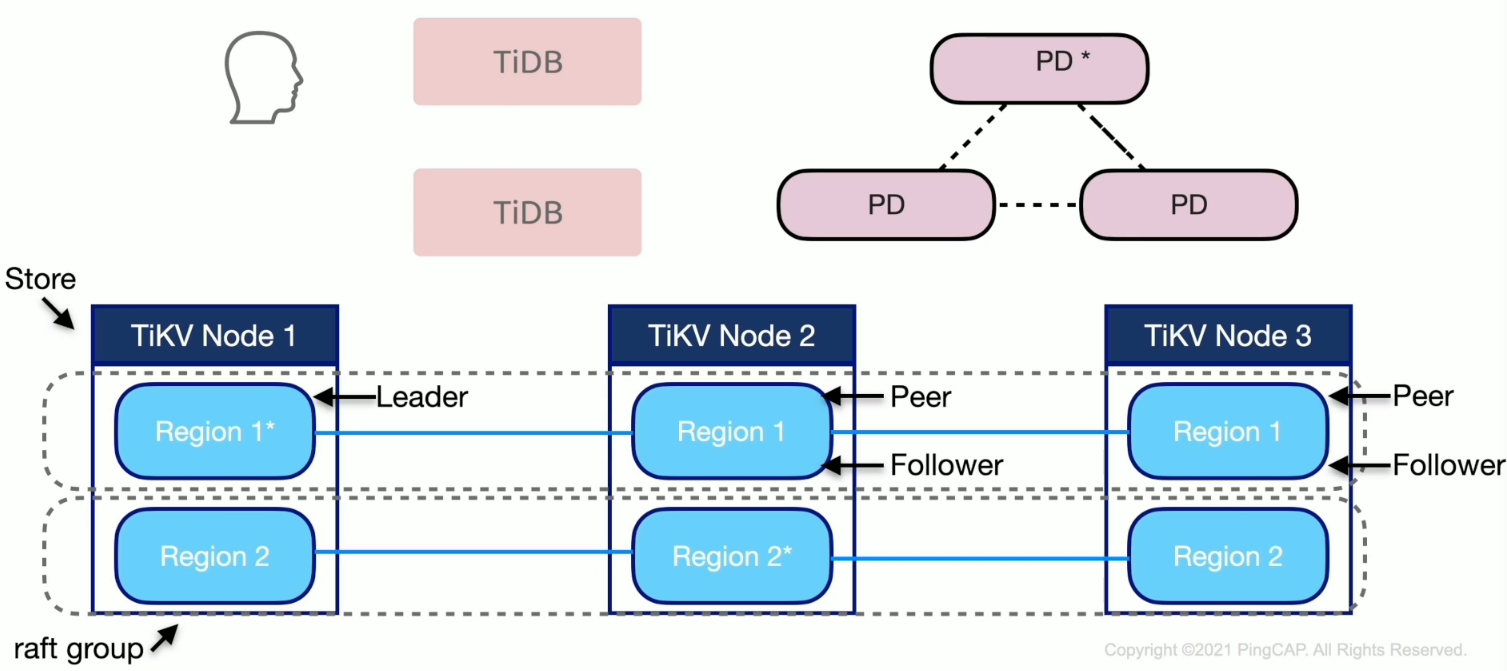
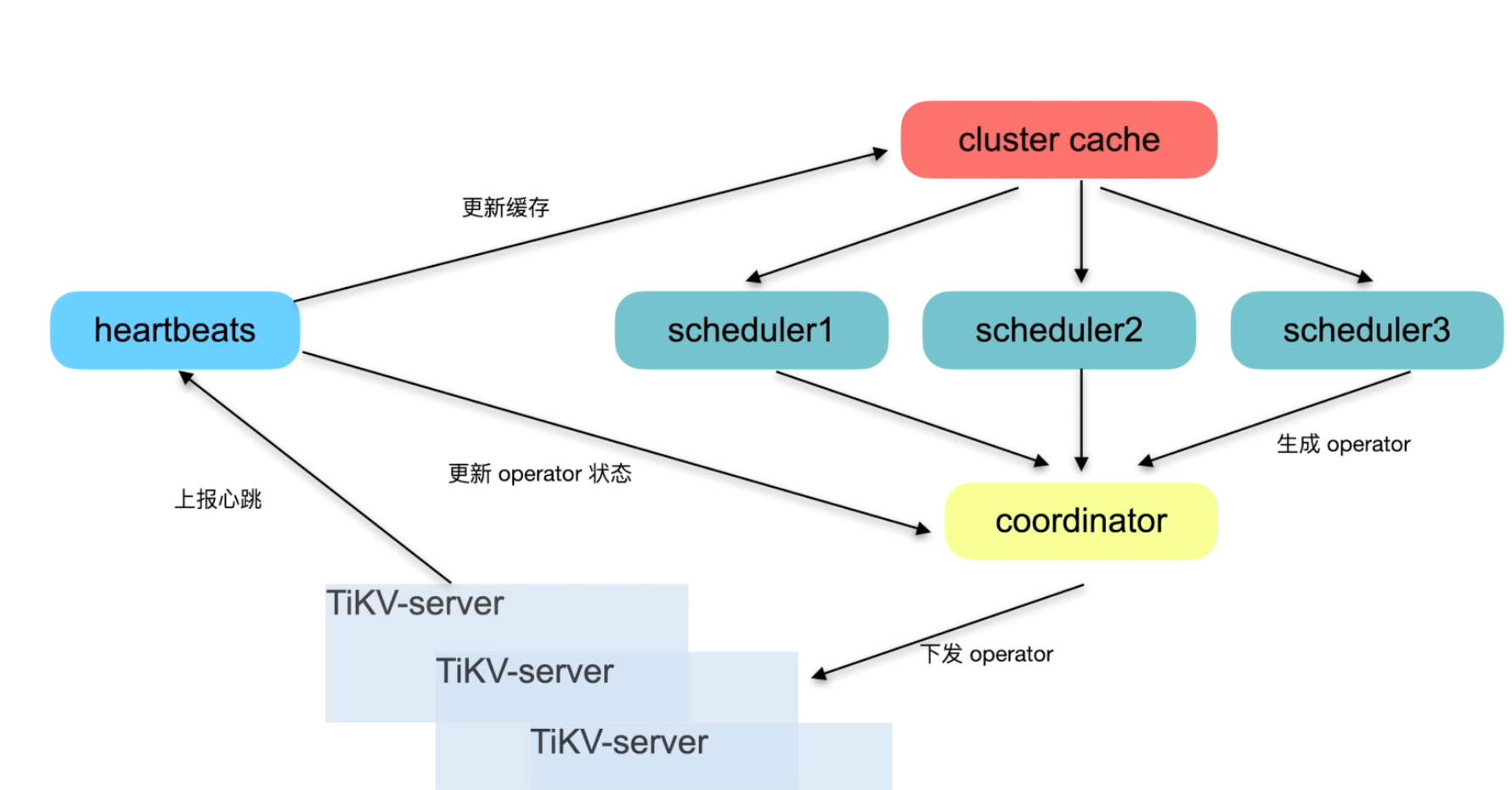
调度
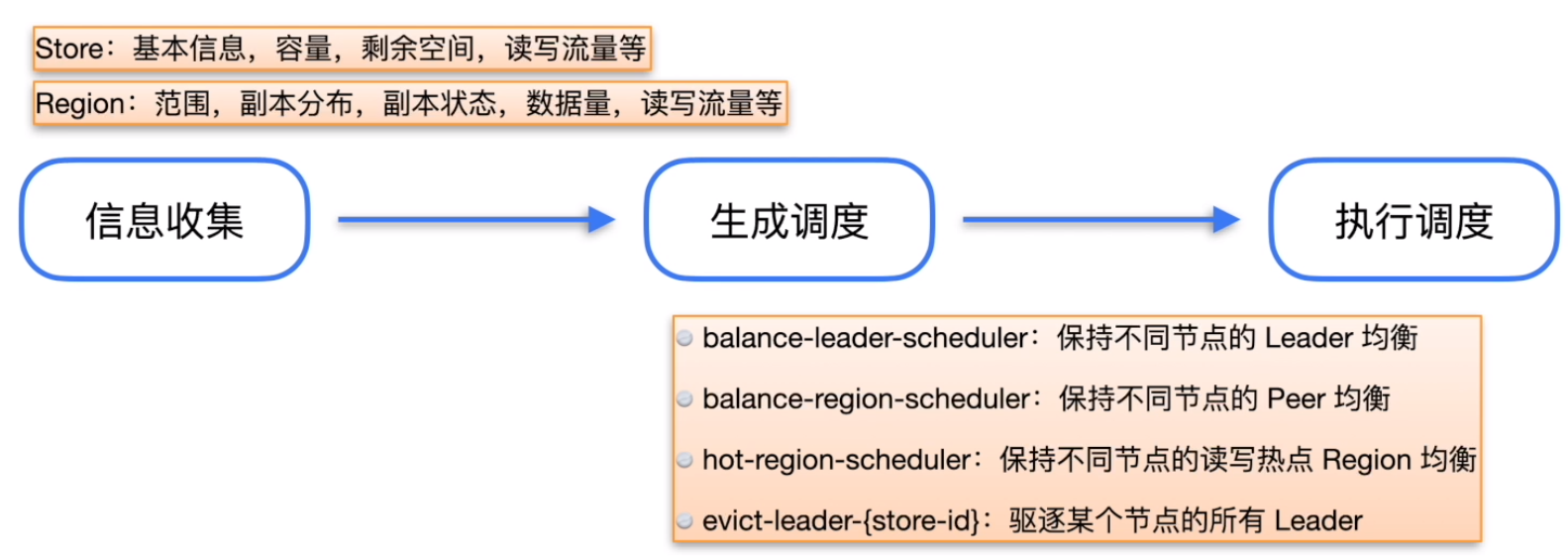
信息收集
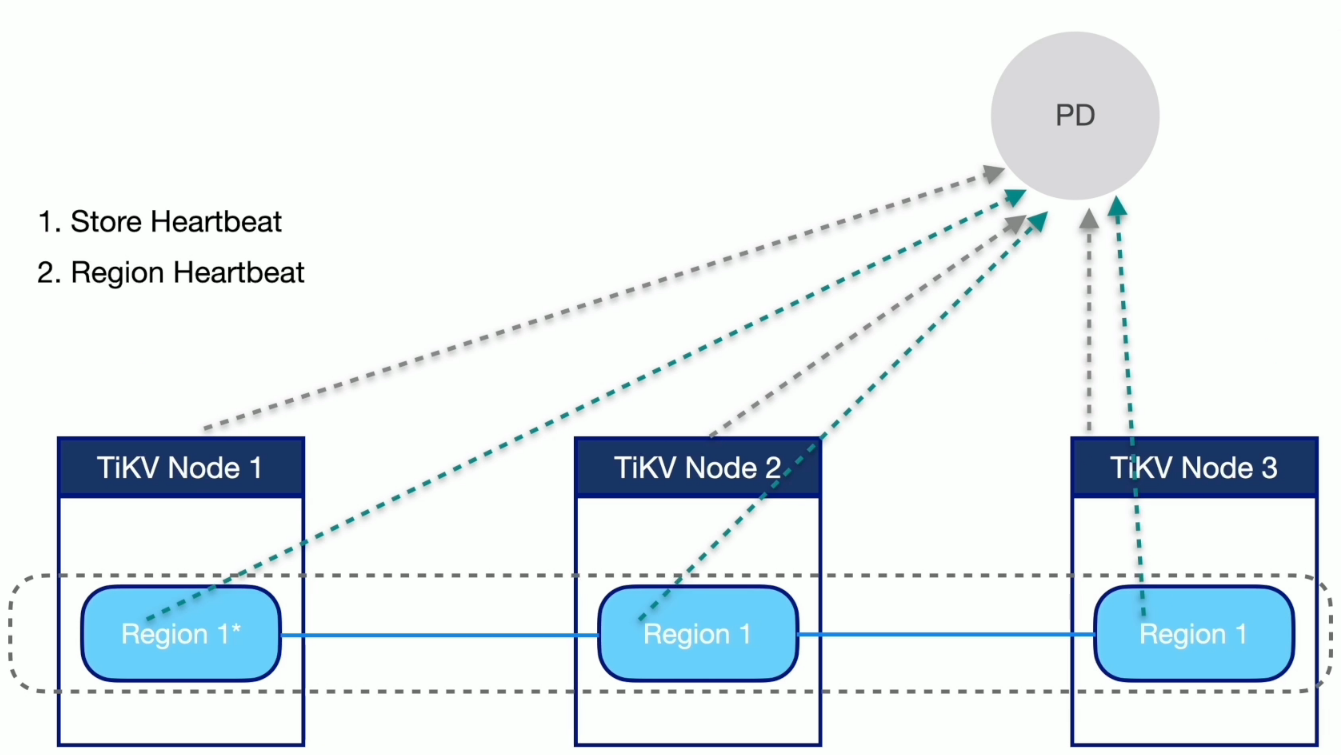
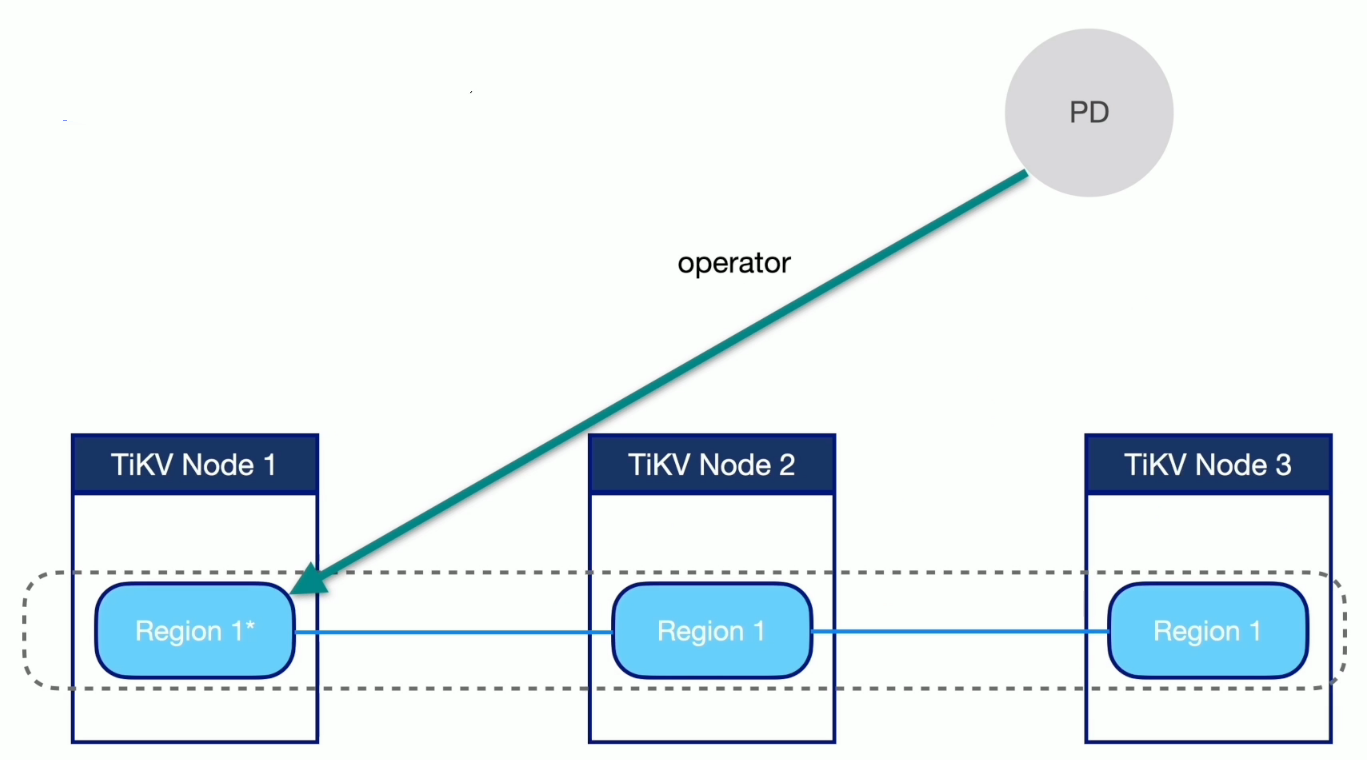
生成调度
- Balance
- leader
- region
- hot region
- 集群拓扑
- 缩容
- 故障恢复
- Region merge
执行调度
label 与高可用
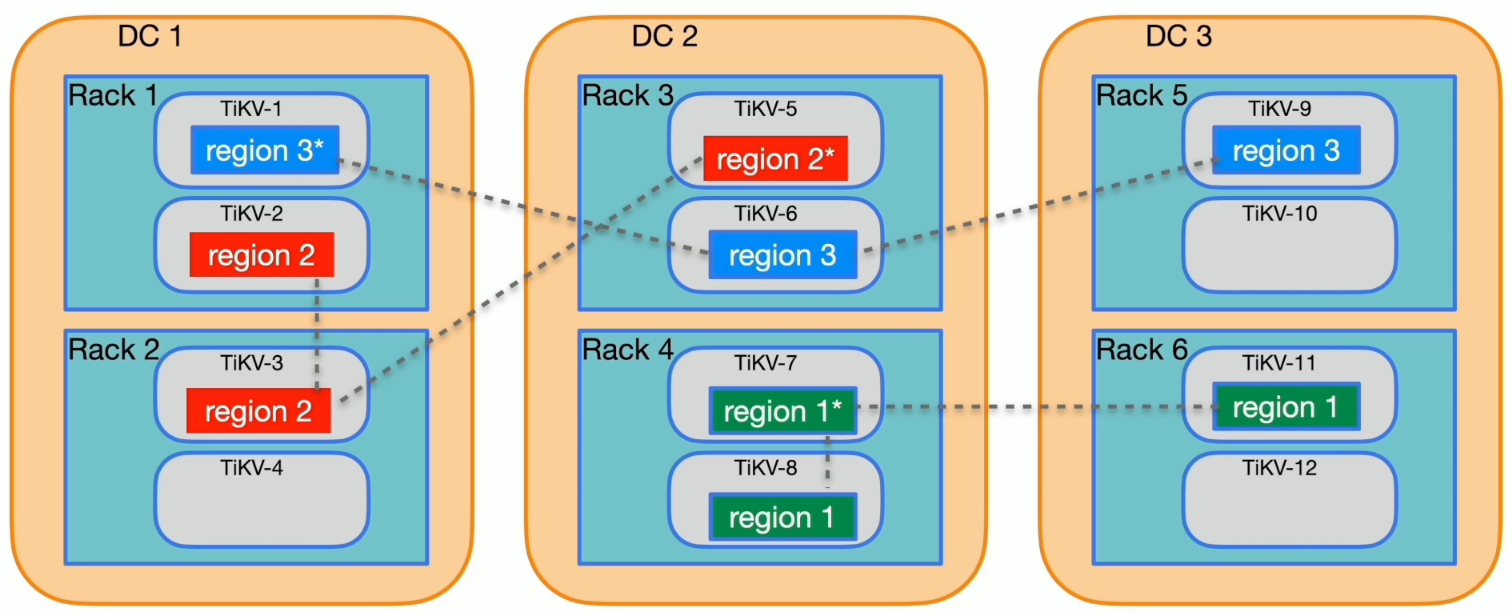
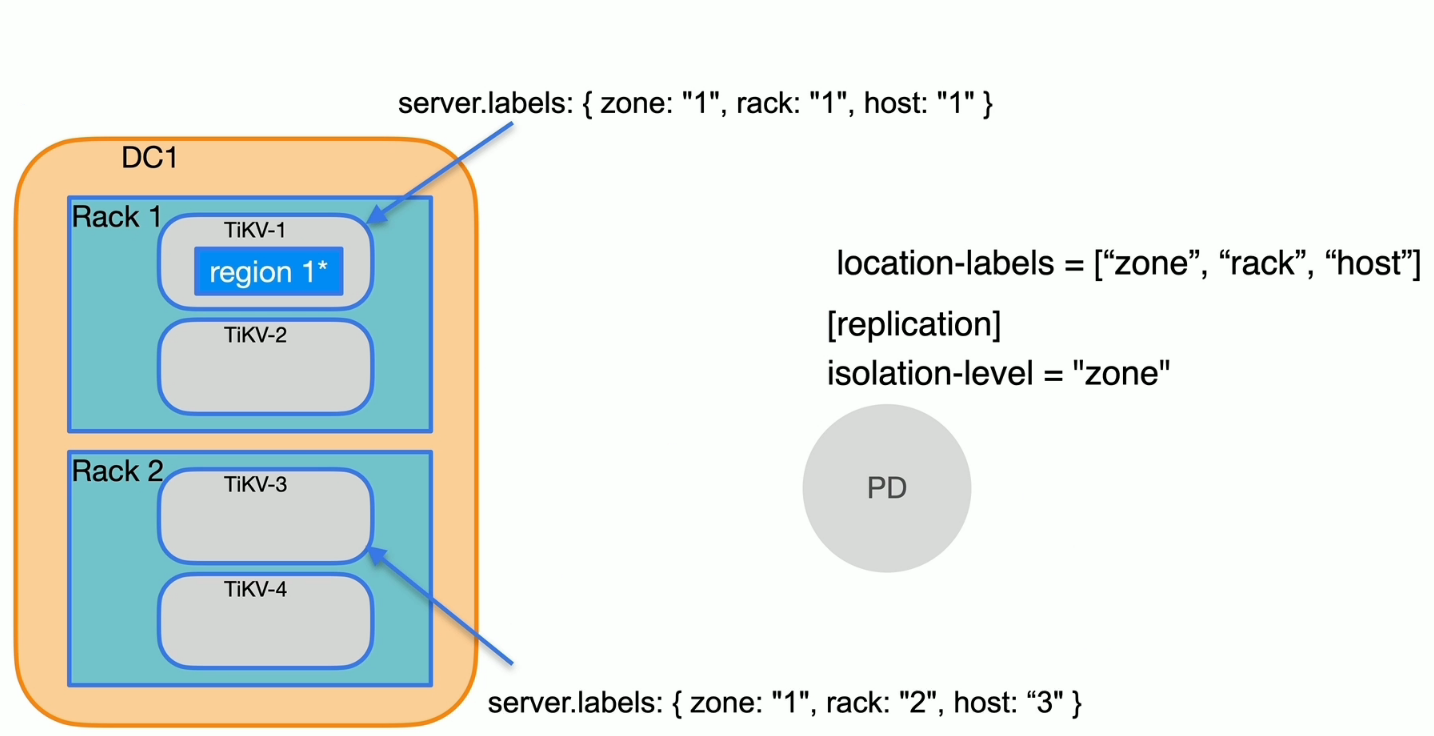
label 的配置
PD (Placement Driver)关键性能参数
PD 调度基本概念
调度流程
调度 limit 参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| region-schedule-limit | 2048 | 同时进行 Region 调度的任务个数 |
| leader-schedule-limit | 4 | 同时进行 leader 调度的任务个数 |
| replica-schedule-limit | 64 | 同时进行replica调度的任务个数 |
| merge-schedule-limit | 8 | 同时进行的 Region Merge 调度的任务,设置为 О 则关闭 Region Merge |
| hot-region-schedule-limit | 4 | 控制同时进行的 hot Region 任务,该配置项独立于 Region 调度 |
消费限速 – store limit
- 定义: 限制单个 store 的消费速度
- 方式: pd-ctl -u ip:port store limit
- 区别: Store Limit 限制的主要是 operator 的消费速度,而其他的 limit 主要是限制 operator 的产生速度。
存储空间阀值参数 high-space-ratio 和 low-space-ratio
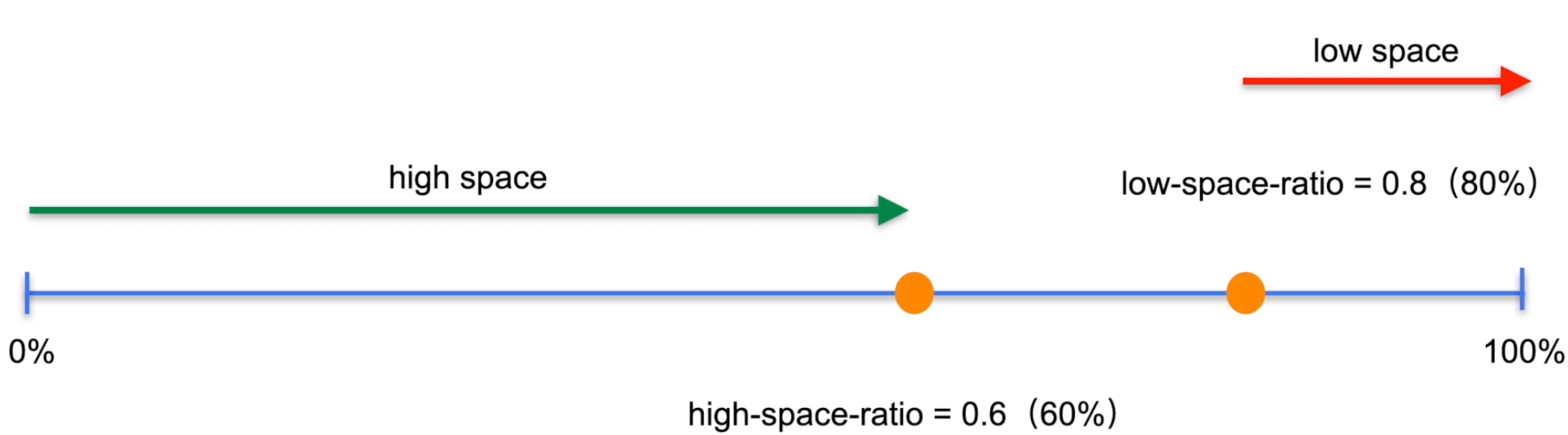
其他参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| patrol-region-interval | 100 ms | 控制扫 region 的间隔,默认100ms,通常不需要调整 |
| tolerant-size-ratio | 0 | 控制 balance region 缓冲区大小,4.0 以后版本默认0,表示自动调整,通常不需要修改。设置过大可能会造成集群数据分布不太均衡。 |
| region_weight 和 leader_weight | 1 | PD 计算 region 和 leader 分数之后,会除以 weight 得到最终的 region 和 leader 分值,weight 参数默认为1,通常不需要修改。 |
pf-ctl 基本操作
查看并修改调度参数
config show --显示当前调度相关参数
config set <key> <value> --修改相关参数
store limit <store_id><value> --限制单个store的调度速度
手动添加 Operator
operator show [adminlleaderlregion] --展示当前全局或者是某类的调度任务
operator add --人工添加一些调度任务实现期望目标,例如
operator add add-peer <region_id><store_id>
operator add remove-peer <region_id><store_id>
operator add transfer-leader <region_id><store_id>
常见问题处理
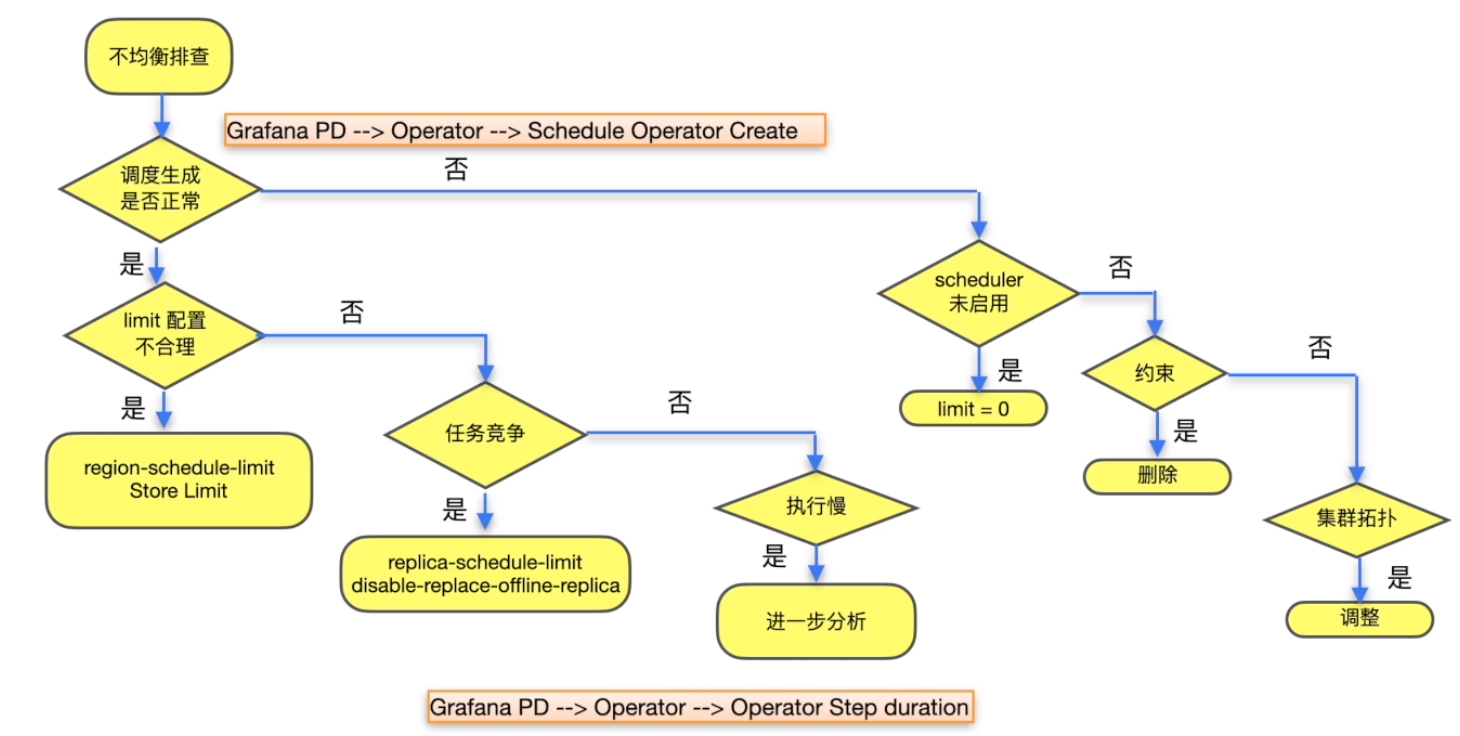
扩容后 balance region 调度速度慢
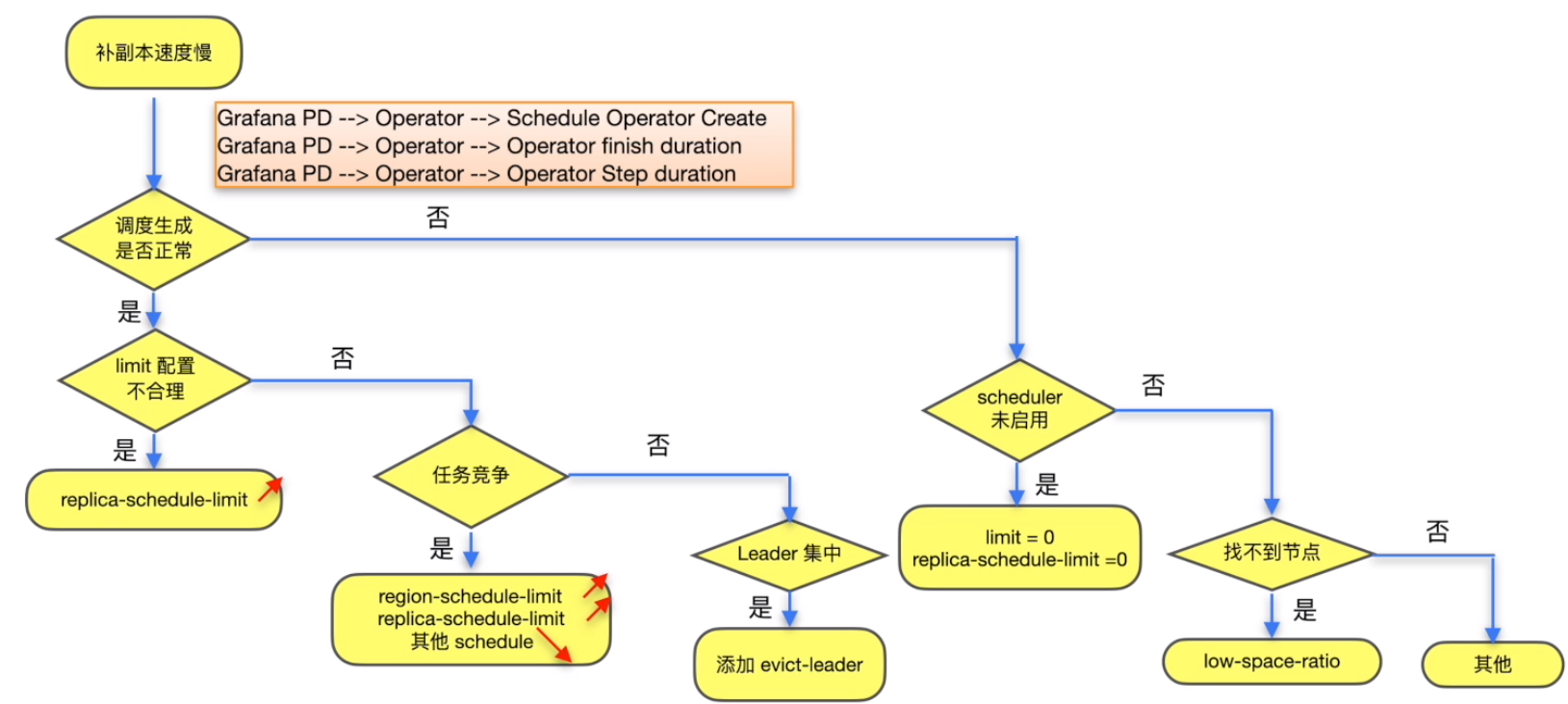
Store节点故障后补副本的速度慢
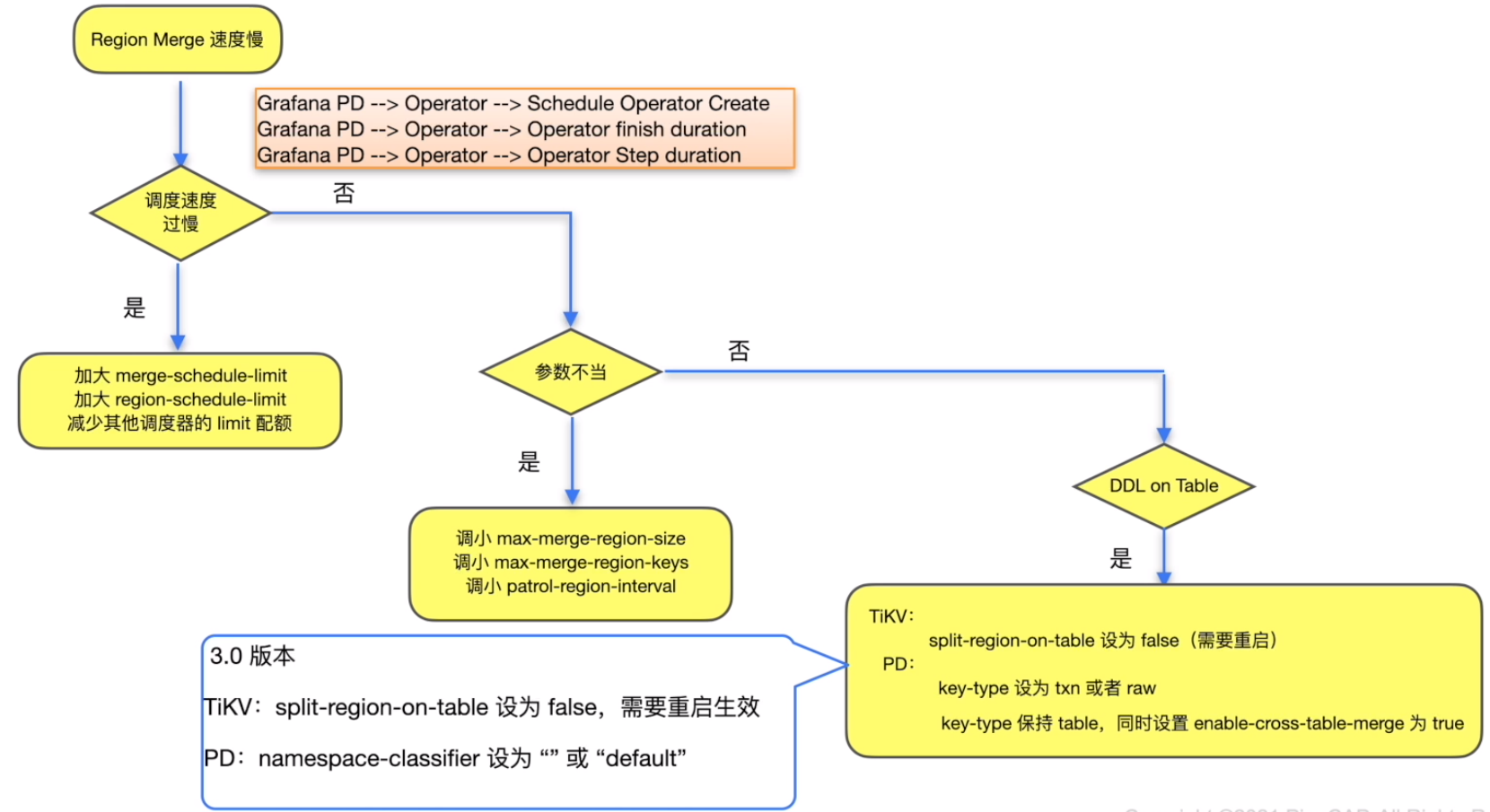
Region merge速度慢
PD 常用监控指标
- Grafana 监控 PD --> PD Dashboard
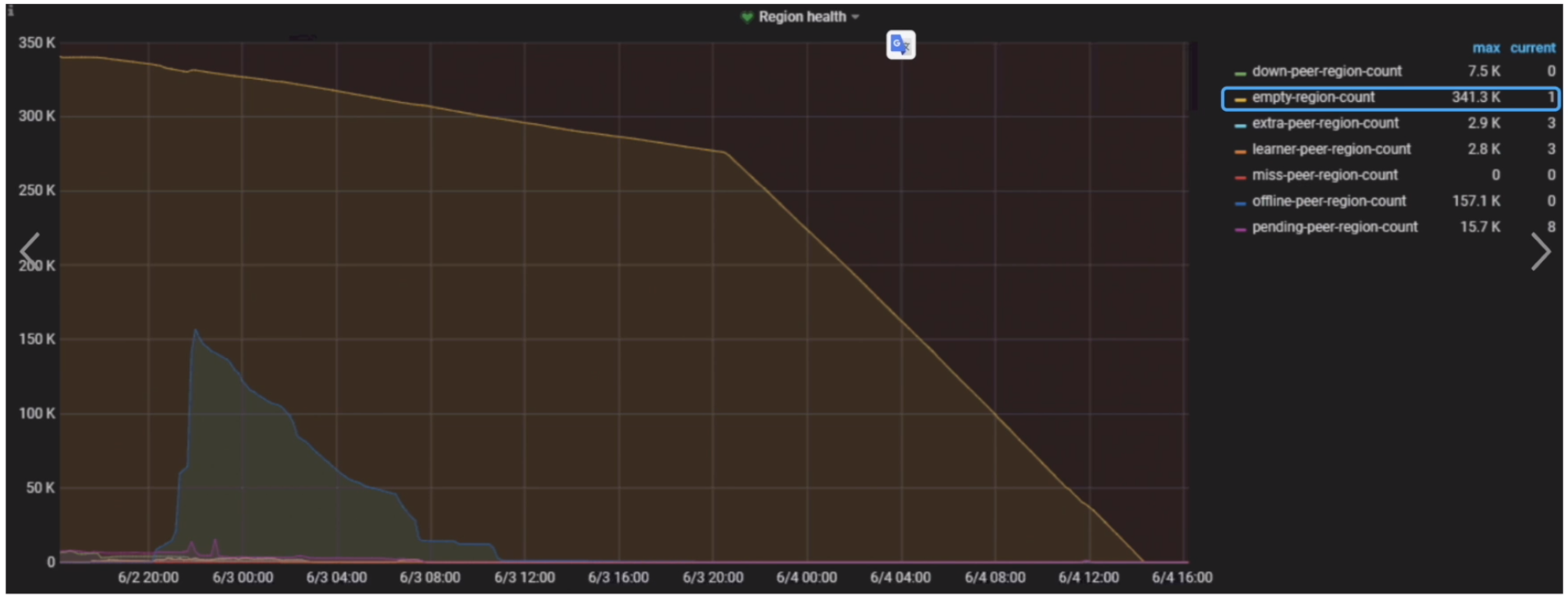
- Grafana 监控 PD --> Region health
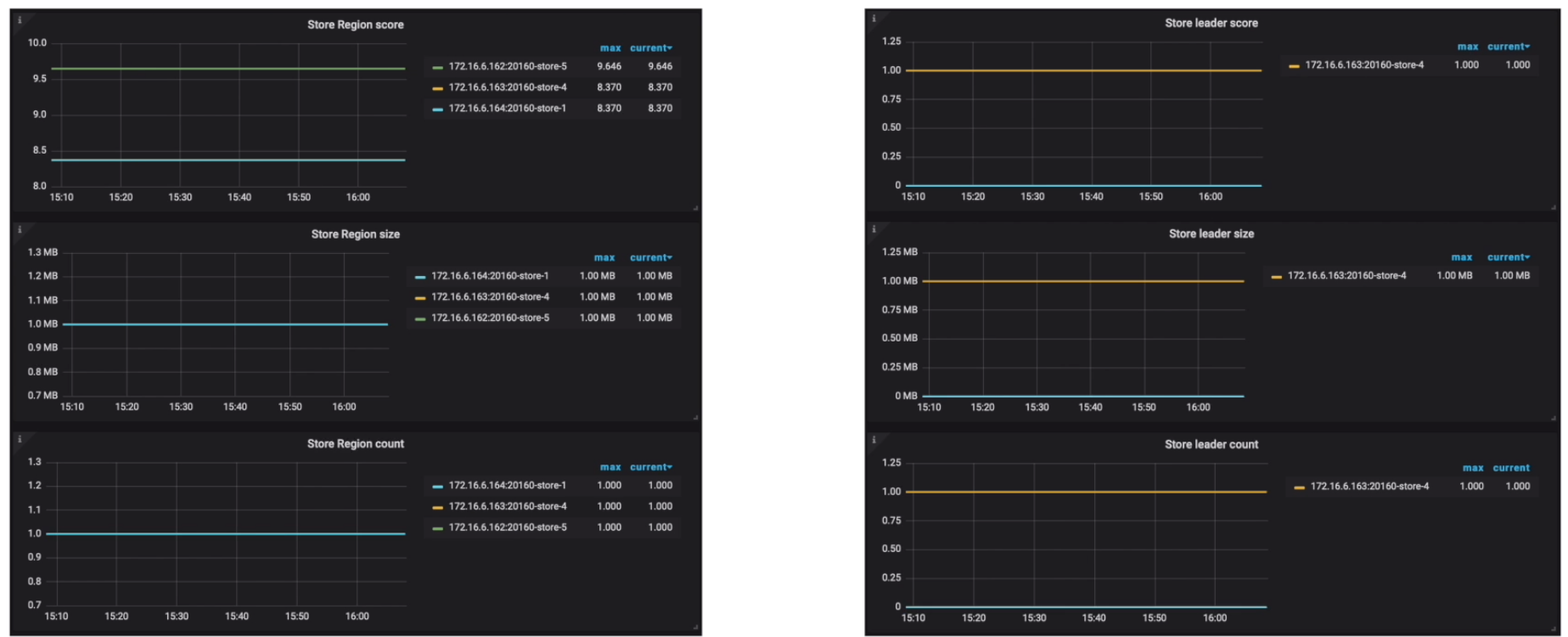
- Grafana 监控 PD --> Statistics - balance
- Grafana 监控 Grafana PD --> Statistics --> Hot write Region’s leader/peer distribution
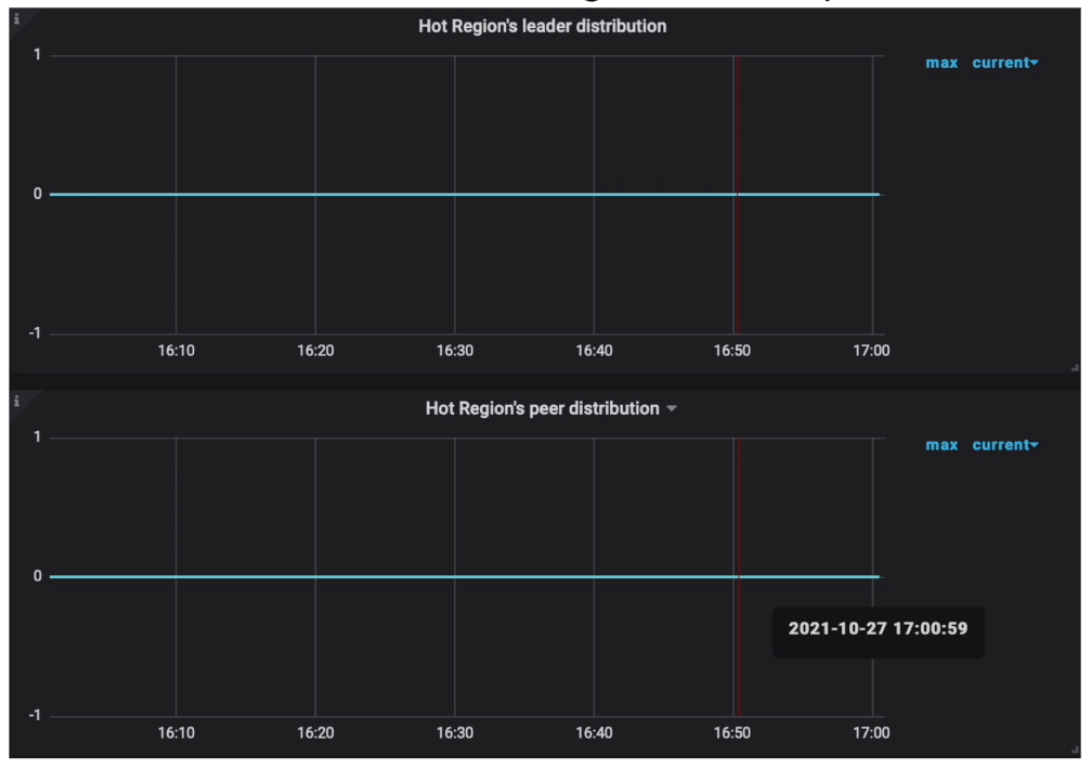
- Grafana 监控 Grafana PD --> Statistics --> Hot read Region’s leader distribution
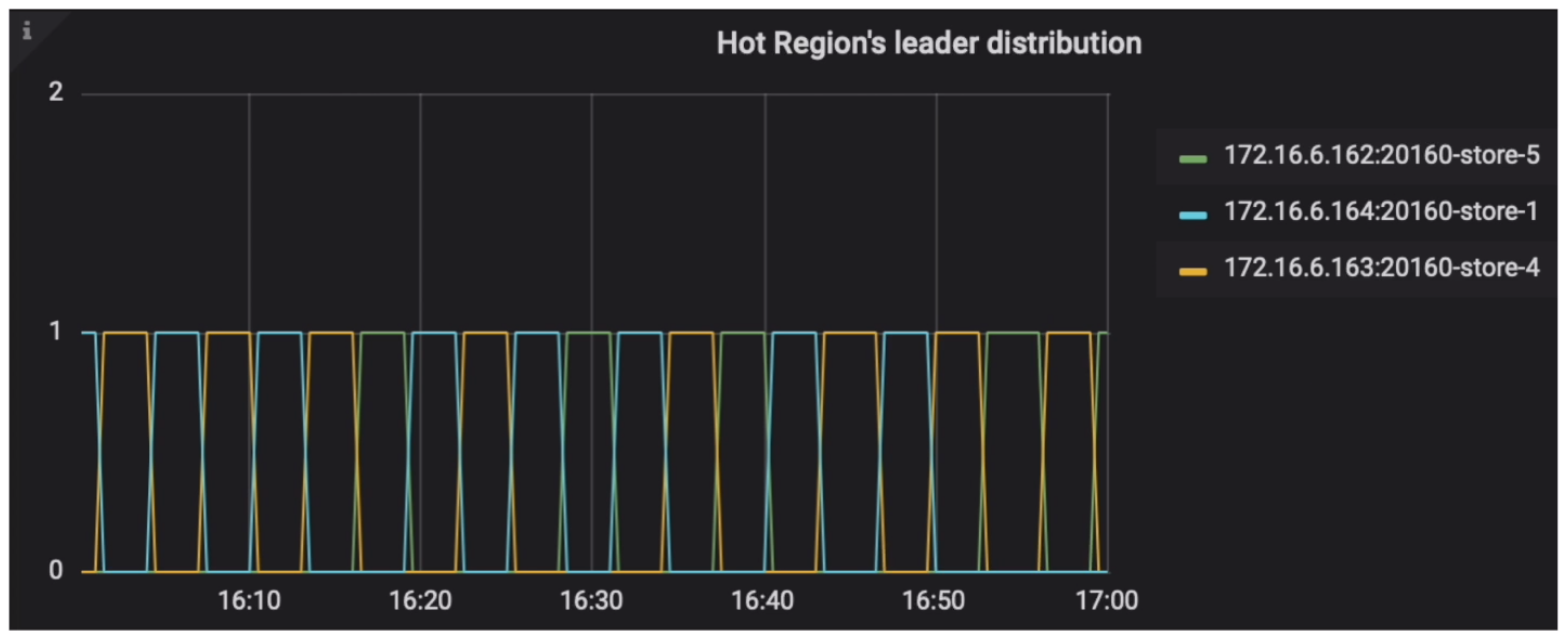
- 重要告警项

PD 调度常见问题及处理方法
PD 调度常见问题
- 集群 TiKV 节点数量没有变化,但逐渐出现若干个 TiKV 占用空间或者 Leader 数量高于其他节点的情况
- 上线了一个 TiKV 节点,但是 Leader transfer 和 Region Balance 速度非常慢
- 通过什么方式,能够加速 TiKV 节点的缩容?
- 大表 Truncate 后,产生的大量 empty region 需要人工介入处理吗?
调度的产生与执行
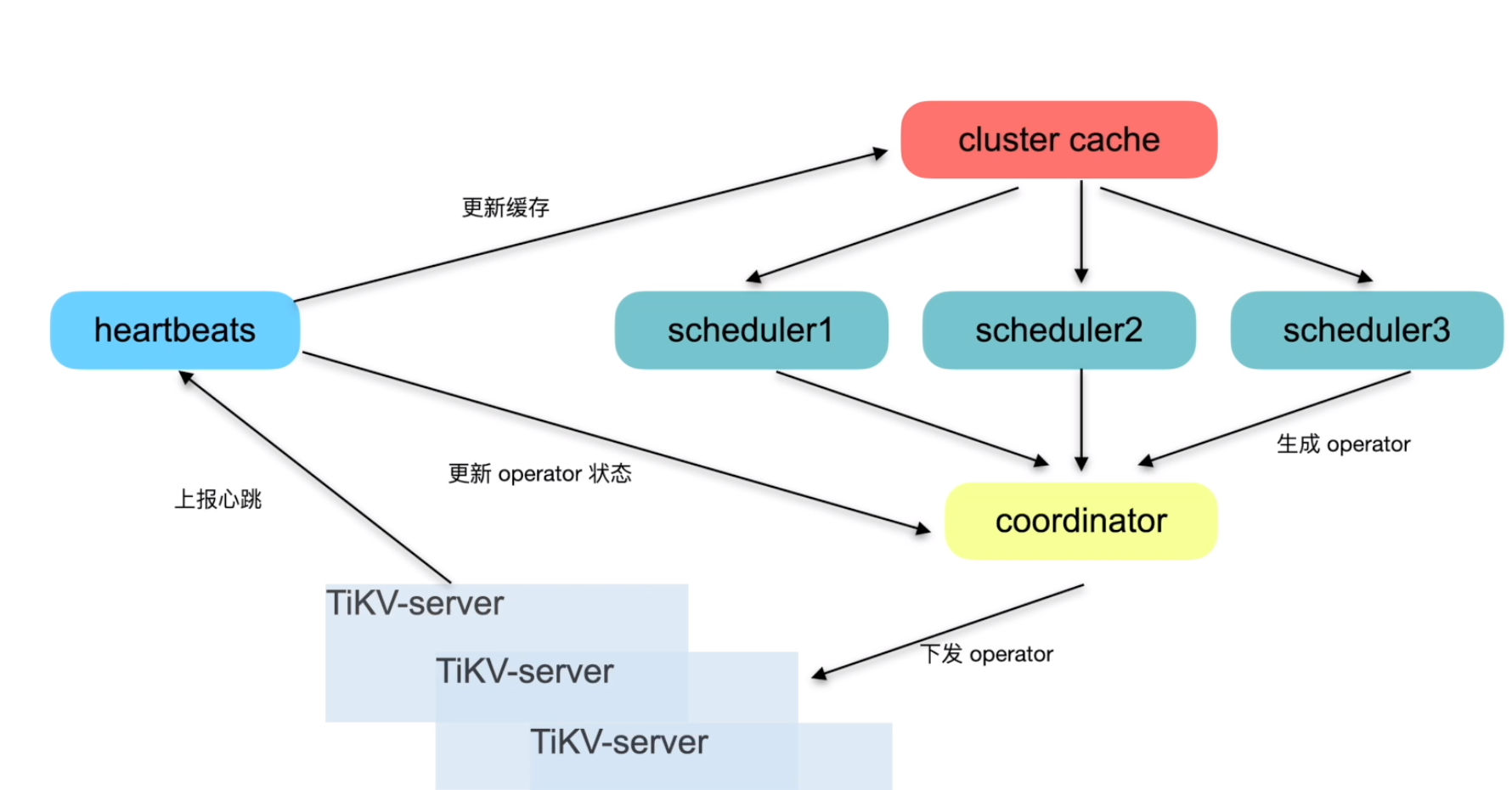
常见的调度类型
- Balance
- leader
- region
- Hot region
- 写热点
- 读热点
- 集群拓扑
- Region merge
调度速度的控制
产生速度控制
| 参数 | 默认值 | 说明 |
|---|---|---|
| region-schedule-limit | 2048 | 同时进行 Region 调度的任务个数 |
| leader-schedule-limit | 4 | 同时进行 leader 调度的任务个数 |
| replica-schedule-limit | 64 | 同时进行replica调度的任务个数 |
| merge-schedule-limit | 8 | 同时进行的 Region Merge 调度的任务,设置为 О 则关闭 Region Merge |
| hot-region-schedule-limit | 4 | 控制同时进行的 hot Region 任务,该配置项独立于 Region 调度 |
消费速度控制
消费限速 - store limit
- 定义: 限制单个 store 的消费速度
- 方式: pd-ctl -u ip:port store limit
- 区别: Store Limit 限制的主要是 operator 的消费速度,而其他的 limit 主要是限制 operator 的产生速度。
PD调度典型场景
- Leader / Region 分布不均衡
- TiKV 节点下线速度慢
- TiKV 节点上线速度慢
- 热点 Region 分布不均衡
- Region Merge 速度慢
Leader / Region 分布不均衡
监控
- Grafana PD --> Statistics - balance 页面展示了负载均衡相关统计
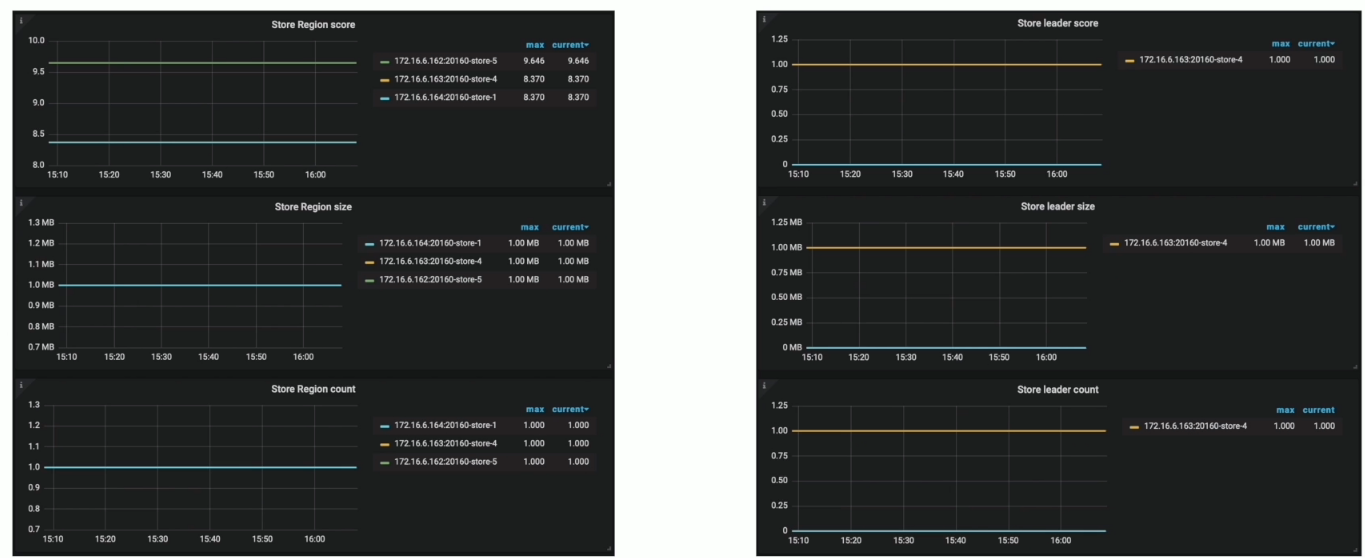
- pd-ctl: 查询 Store 的得分,数量,剩余空间和 weight 等信息
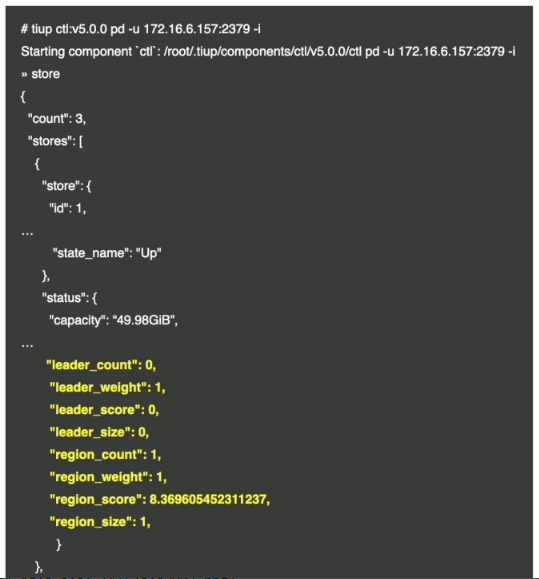
现象
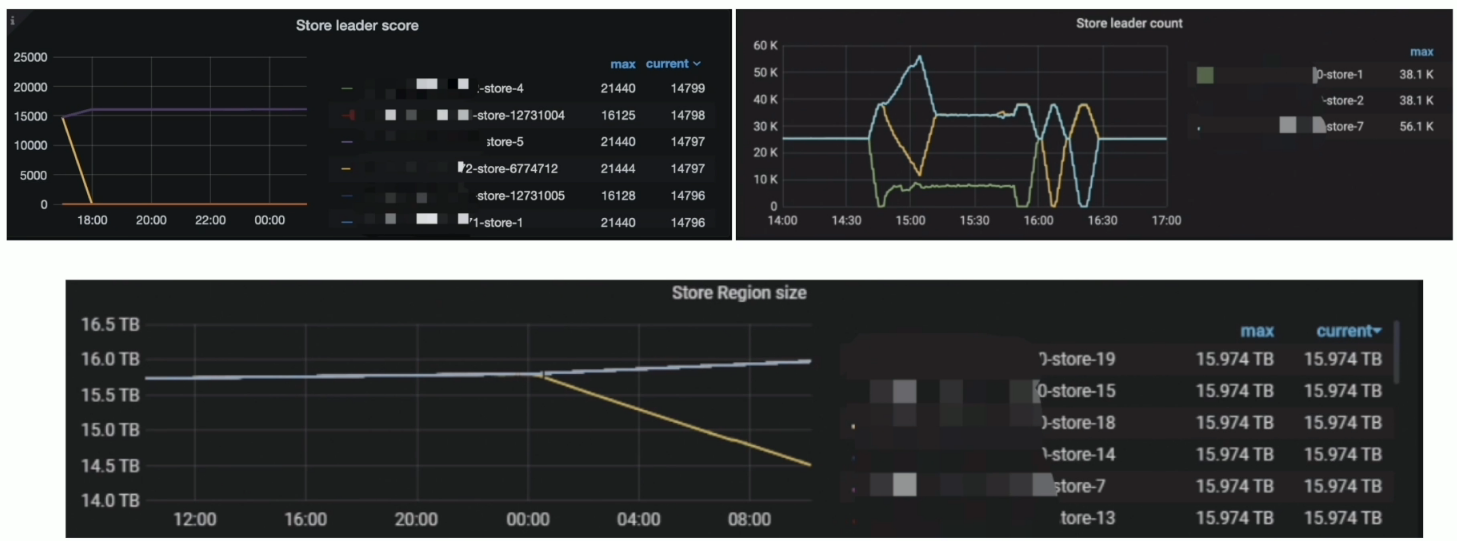
解决方案
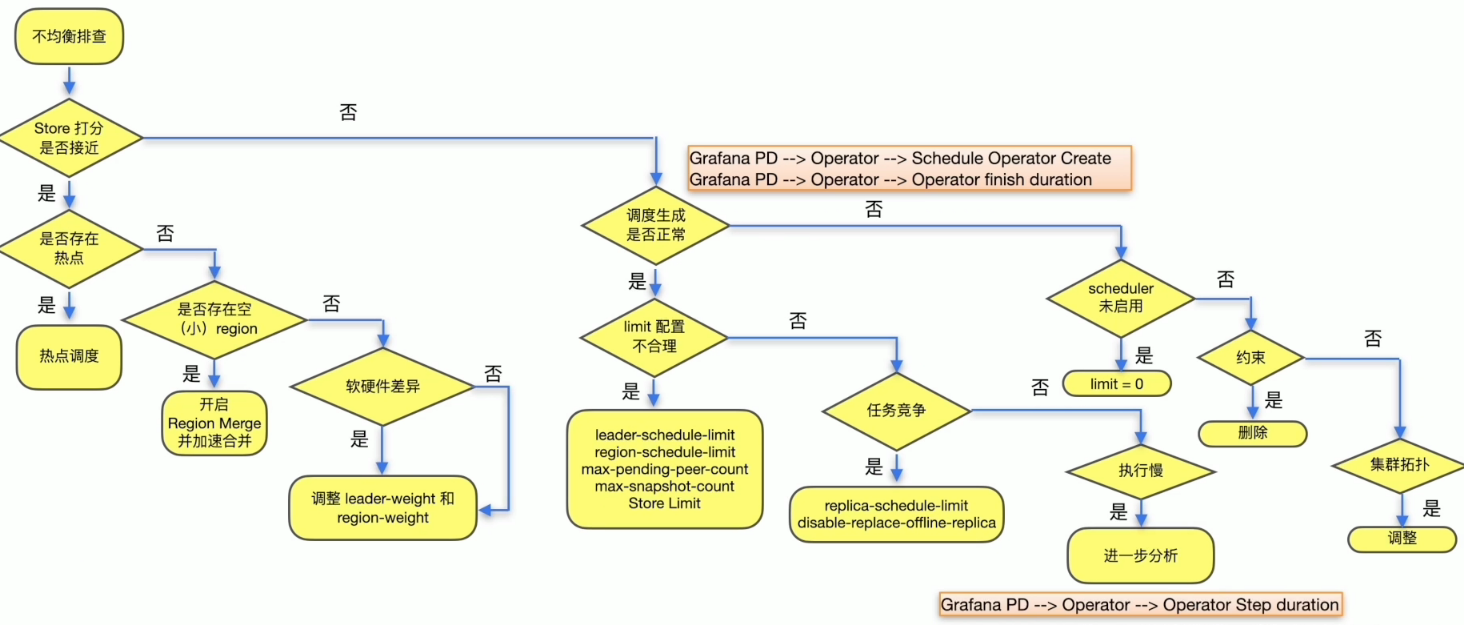
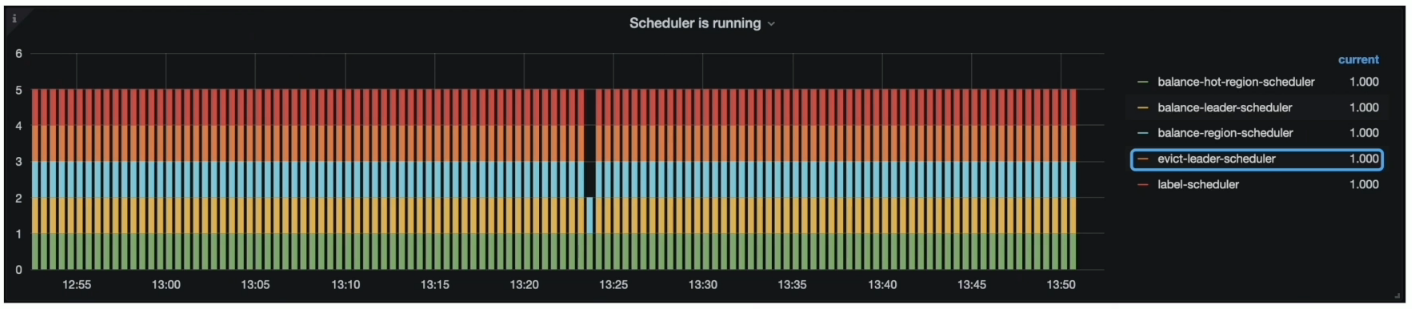
- 约束案例︰ 集群有 evict-leader-scheduler (驱逐某个节点的所有 Leader) ,此时无法把 Leader 迁移至对应的 Store
- 如何监控: Grafana PD --> Scheduler --> Scheduler is running
- 处理步骤:
- 使用 pd-ctl config show all 确认下存在 evict-leader 的 TiKV
- 使用 pd-ctl 将 TiKV 上的 evict-leader 调度 remove 掉
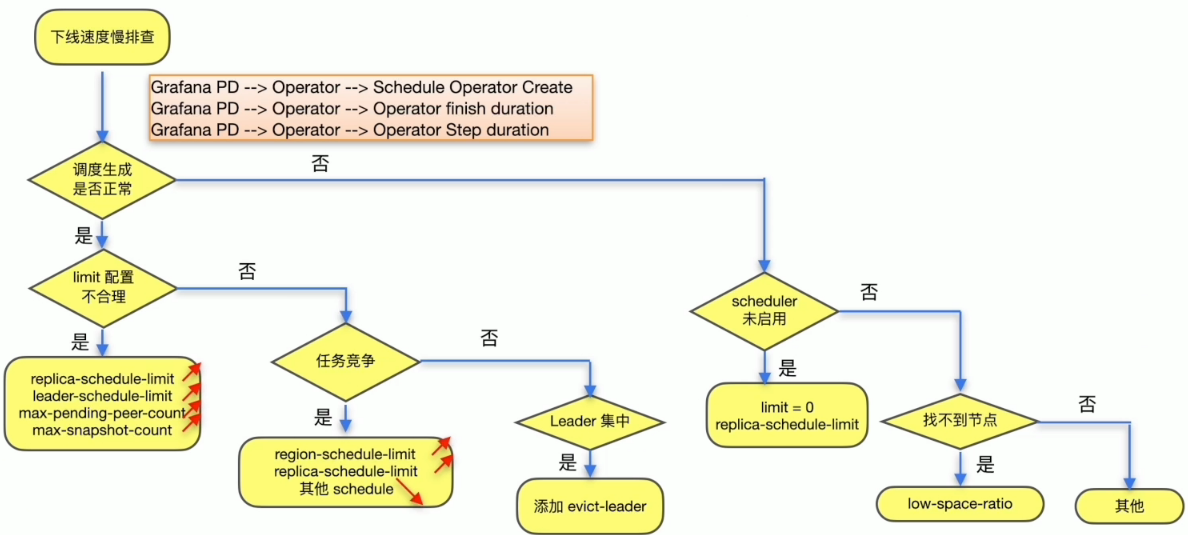
TiKV 节点下线速度慢
监控与现象
- Grafana PD --> Statistics - balance --> Store leader count & Store Region count
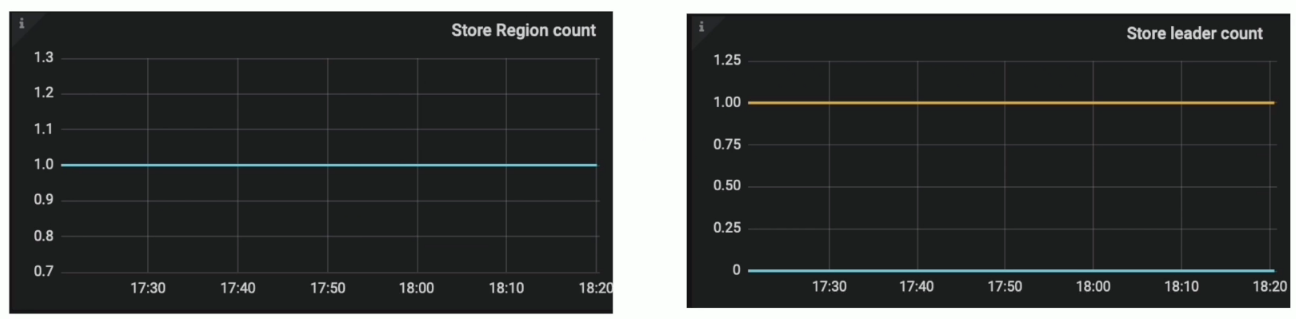
- pd-ctl store {target_store_id} --> region_count & leader_count
解决方案
TiKV 节点上线速度慢
监控与现象
- Grafana PD --> Statistics - balance --> Store leader count & Store Region count
- pd-ctl store {target_store_id} --> region_count & leader_count
解决方案
参考 Leader / Region 分布不均衡解决方案
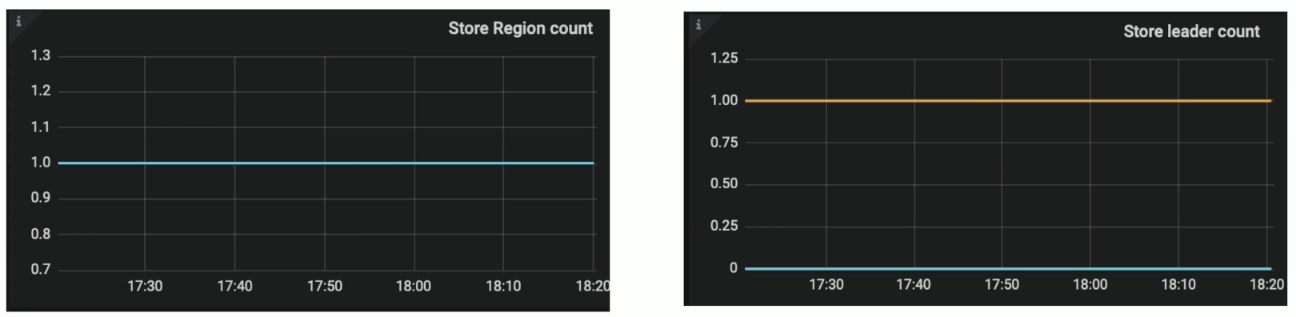
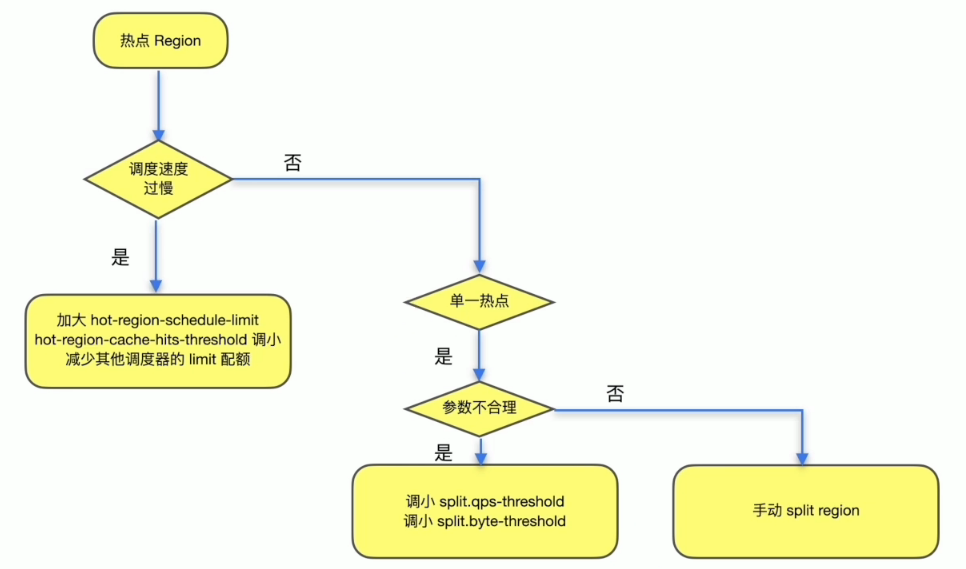
热点 Region 分布不均衡
监控与现象
- Grafana PD --> Statistics --> hot write
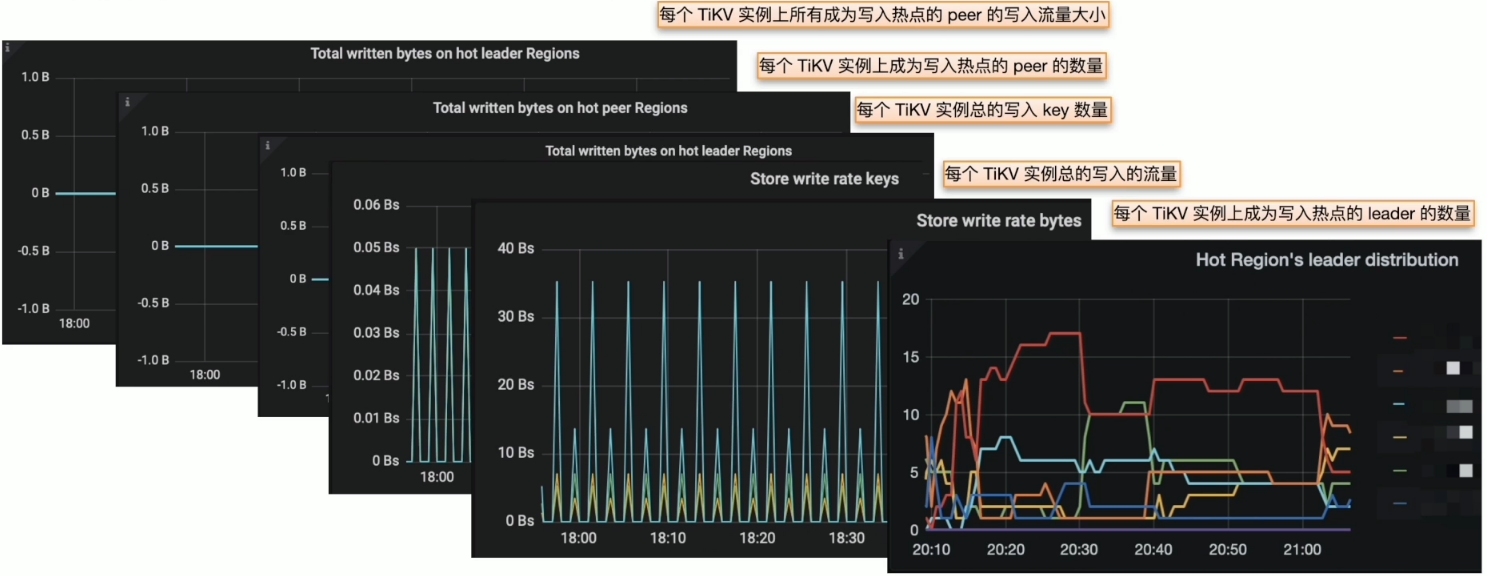
- Grafana PD --> Statistics --> hot read
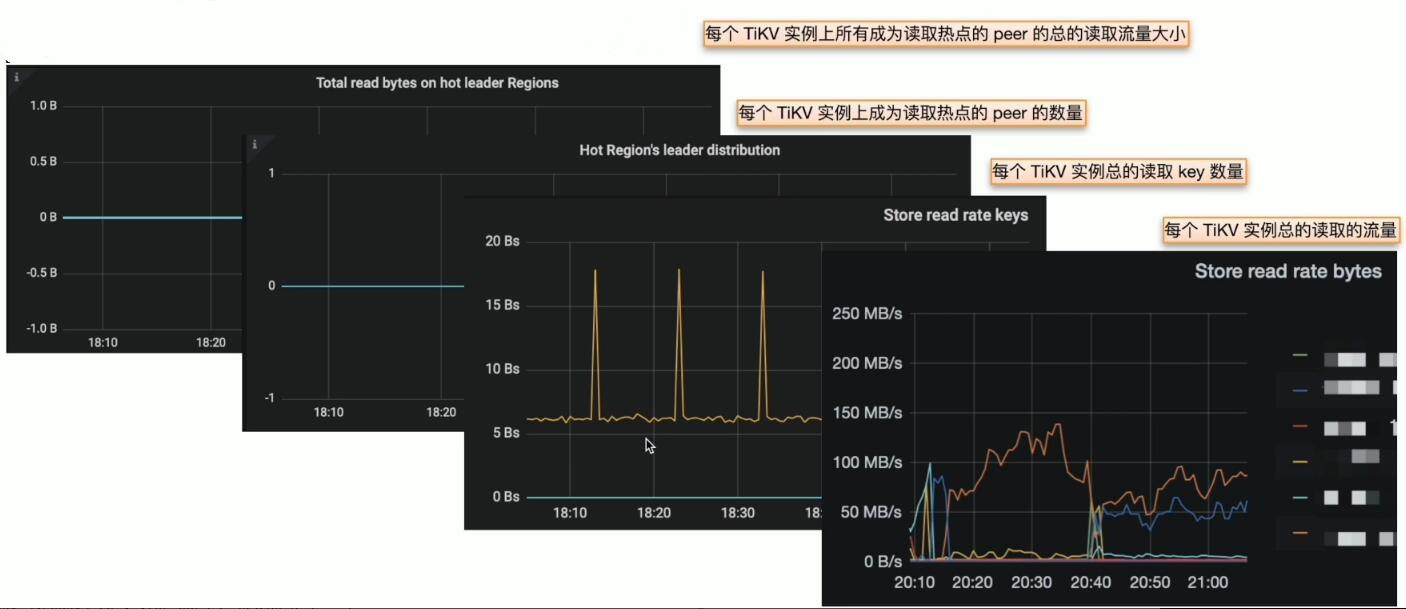
解决方案
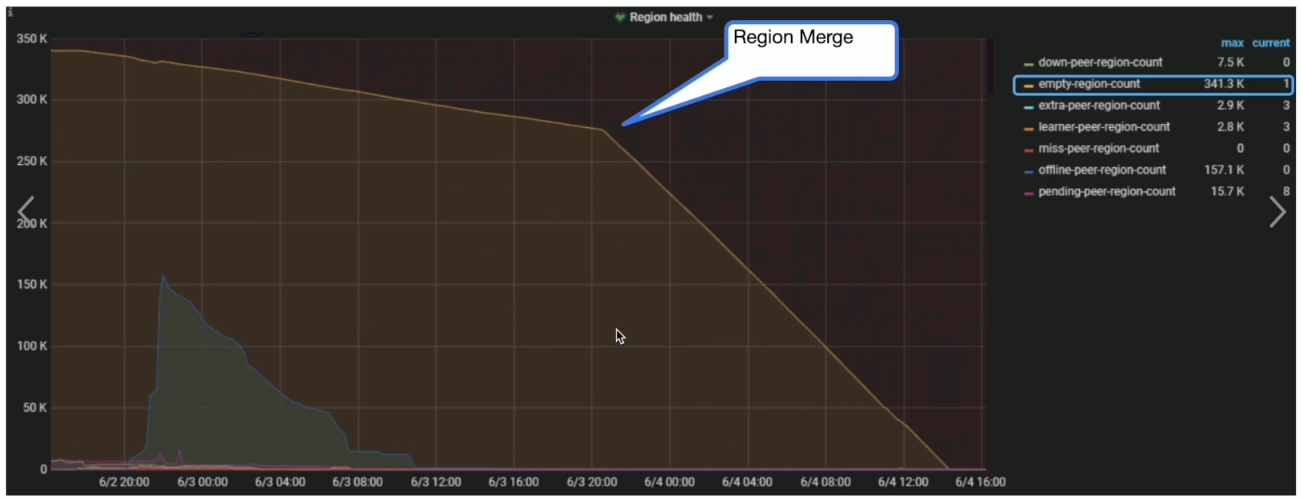
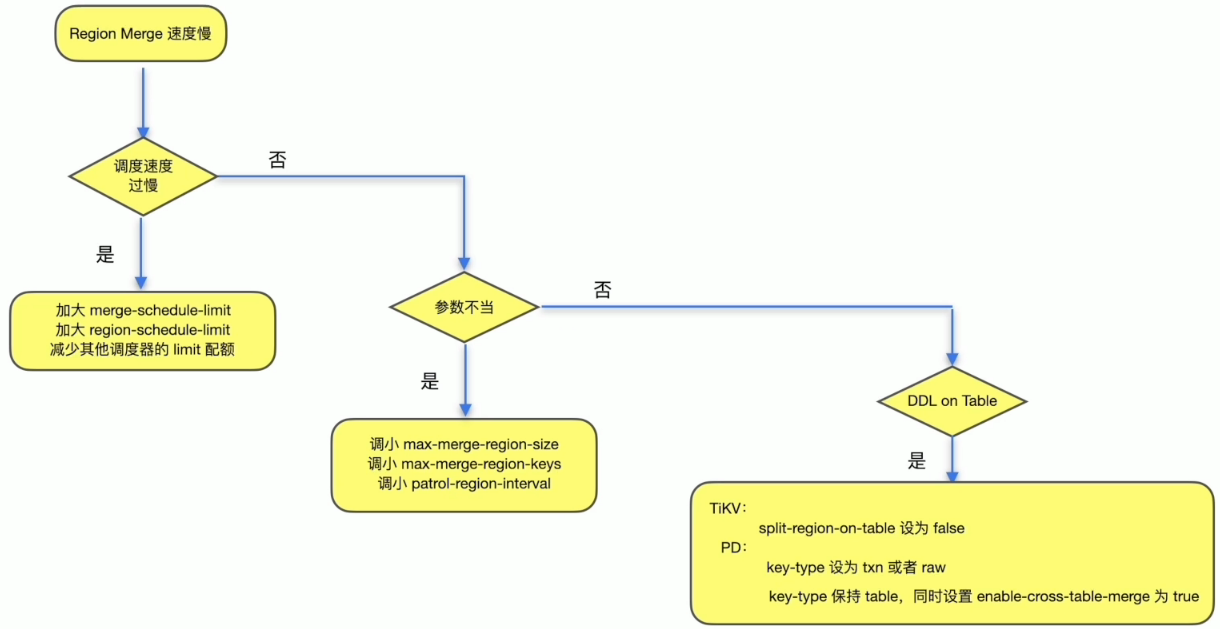
Region Merge 速度慢
监控与现象
- Grafana PD --> Region health
解决方案
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
