




HDFS 的特点与应用场景
1、适合存储大文件
2、容错性高
3、适用于流式的数据访问
4、适用于读多写少场景
HDFS的相关概念
数据块(Block)
NameNode和DataNode
Secondary NameNode
块缓存
HDFS 的架构
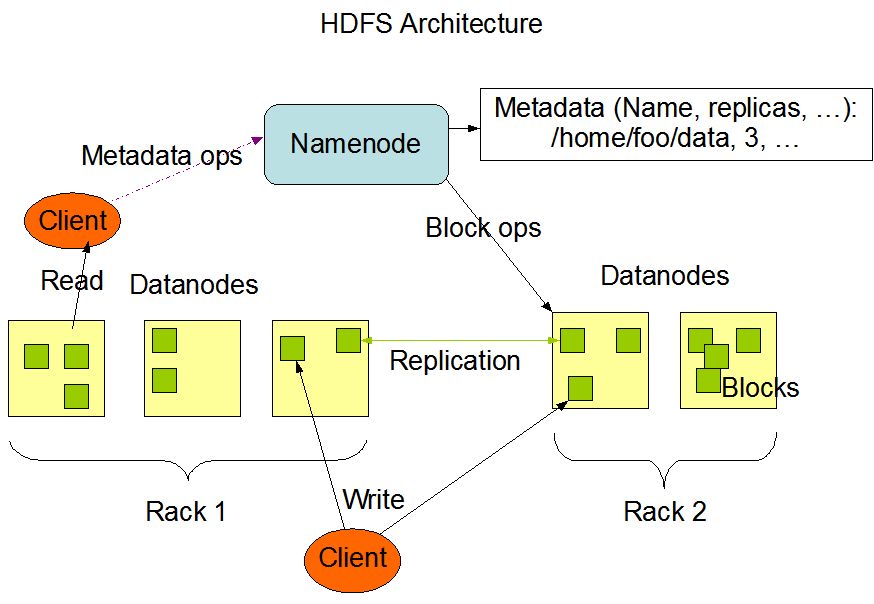
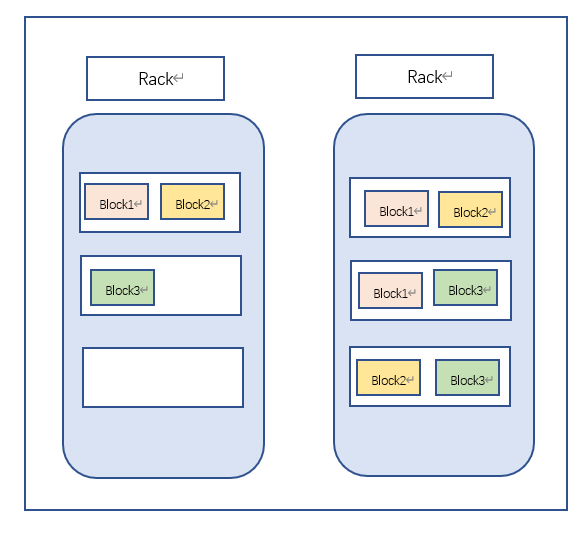
机架感知和副本机制
读写流程
读操作
简要流程:
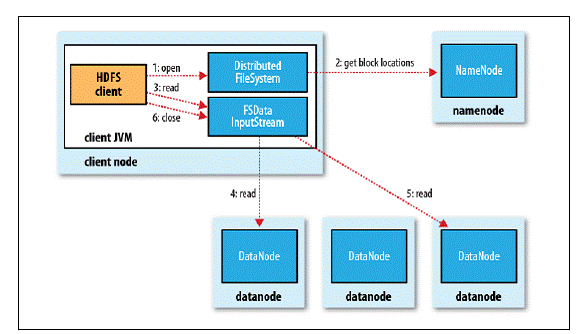
详细流程:
客户端通过调用 FileSystem 对象的 open() 方法来打开希望读取的文件,对于 HDFS 来说,这个对象是分布式文件系统的一个实例; DistributedFileSystem 通过RPC 调用 NameNode 以确定文件起始块的位置,由于存在多个副本,因此Namenode会返回同一个Block的多个文件的位置,然后根据集群拓扑结构排序,就近取; 前两步会返回一个 FSDataInputStream 对象,该对象会被封装成 DFSInputStream 对象,DFSInputStream 可以方便的管理 datanode 和 namenode 数据流,客户端对这个输入流调用 read() 方法; 存储着文件起始块的 DataNode 地址的 DFSInputStream 随即连接距离最近的 DataNode,通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端; 到达块的末端时,DFSInputStream 会关闭与该 DataNode 的连接,然后寻找下一个块的最佳 DataNode,这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流; 一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法关闭文件读取。
写操作
简单流程:
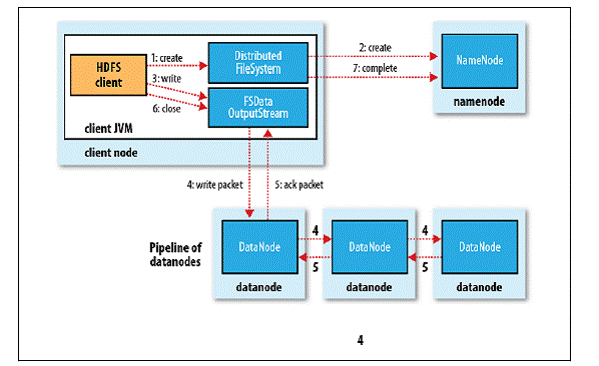
详细流程:
客户端通过调用 DistributedFileSystem 的 create() 方法创建新文件; DistributedFileSystem 通过 RPC 调用 NameNode 去创建一个没有 Blocks 关联的新文件,创建前 NameNode 会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode 会为创建新文件记录一条记录,否则就会抛出 IO 异常; 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode 和 Datanode。客户端开始写数据到 DFSOutputStream,DFSOutputStream 会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue); DataStreamer 会去处理接受 Data Queue,它先问询 NameNode 这个新的 Block 最适合存储在哪几个 DataNode 里,比如重复数是 3,那么就找到 3 个最适合的 DataNode,把他们排成一个 pipeline。DataStreamer 把 Packet 按队列输出到管道的第一个 Datanode 中,第一个 DataNode 又把 Packet 输出到第二个 DataNode 中,以此类推; DFSOutputStream 还有一个队列叫 Ack Quene,也是由 Packet 组成,等待 DataNode 的收到响应,当 Pipeline 中的所有 DataNode 都表示已经收到的时候,这时 Akc Quene 才会把对应的 Packet 包移除掉; 客户端完成写数据后调用 close() 方法关闭写入流; DataStreamer 把剩余的包都刷到 Pipeline 里然后等待 Ack 信息,收到最后一个 Ack 后,通知 NameNode 把文件标示为已完成。
本文简单讲了 HDFS 的特点与应用场景、相关概念、架构、副本机制和机架感知以及读写流程。如果觉得有帮到你或者有所收获,麻烦动动小手点个再看或随手转发。
扫码关注不迷路,第一时间获取文章哦

文章转载自大数据的奇妙冒险,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
372次阅读
2025-03-21 10:33:59
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
311次阅读
2025-04-07 09:44:54
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
255次阅读
2025-04-14 09:40:20
为什么总是很难客观评价某个国产数据库产品
白鳝的洞穴
216次阅读
2025-03-19 11:21:09
关于征集数据库标准体系更新意见和数据库标准化需求的通知
数据库标准工作组
212次阅读
2025-04-11 11:30:08
国产数据库时代,一些20年前的数据库设计小技巧又可以拿出来用了
白鳝的洞穴
202次阅读
2025-04-10 11:52:51
史诗级革新 | Apache Flink 2.0 正式发布
严少安
194次阅读
2025-03-25 00:55:05
TDengine 3.3.6.0 发布:TDgpt + 虚拟表 + JDBC 加速 8 大升级亮点
TDengine
166次阅读
2025-04-09 11:01:22
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
SelectDB
165次阅读
2025-04-03 17:41:08
GoldenDB助力江苏省住房公积金国产数据库应用推广暨数字化发展交流会成功举办
GoldenDB分布式数据库
157次阅读
2025-04-07 09:44:49
