排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
Kafka从入门到放弃 —— Kafka在大数据领域的应用
Kafka从入门到放弃 —— Kafka在大数据领域的应用
大数据的奇妙冒险
2022-01-27
560
Kafka作为一个消息中间件,其应用相当广泛,尤其在大数据领域,基本都会用到。由于笔者参与大数据工作,因此本文将从我的角度和经验出发,讲一下Kafka为什么广泛应用于大数据领域。对于Kafka不是很熟悉的朋友可以点击下方链接跳转进行阅读:
Kafka从入门到放弃——初识Kafka
Kafka从入门到放弃——细说生产者
Kafka从入门到放弃——详说消费者
背景&场景
在大数据场景下,数据经常需要经过ETL(抽取-转换-加载)的处理,从一端流向另一端(当然也有ELT,根据各个企业不同的考量决定不同的架构),比如从各个业务系统经过处理后落地到数据仓库,数据仓库有时候又要把数据提供给业务系统。
由于数据流向比较多,如果不做好数据链路规划,很容易造成开发重复、成本增加,出现问题也比较难以排查。因此,合理构造数据管道是很重要的,而Kafka在数据管道的构建中发挥了很大的优势。
特点&原因
批流一体
大数据处理分为流处理和批处理。流处理对实时性要求比较高,数据像水流一样源源不断的流动;批处理就是批量处理,就是字面意思,比如当天处理前一天的数据。
由于Kafka是一个基于流的数据平台,在数据处理方面可以做到实时,所以经常在流处理架构中用到它。
另外它也提供数据存储,可以将一段时间内的数据存储起来,后续对挤压的数据进行批量处理;也可以在数据到达的时候及时获取并处理。
可用性&可靠性
之前的几篇文章中说的那些特点多少包含了Kafka在这方面的情况。
Kafka通过zookeeper维护集群的信息,同时Kafka也有Controller,它不单能完成broker的工作,同时还负责分区Leader的选举。
另外,Kafka的分区可以有副本,而且分leader和follower,当leader挂掉后follower能顶替其位置,保证其可用性。
在生产者方面,发送消息到Kafka有确认机制以及重试机制,详情可以看这篇文章:
Kafka从入门到放弃——细说生产者
在消费者方面,提交偏移量的策略选择以及重分区可以保证数据可靠性。
Kafka还支持“
exactly once
”语意。exactly once是有且只有一次,可以简单理解为:数据到达并保存了,但还没返回确认消息的时候挂了,生产者再发一次,Kafka再存一次,这种是at least once;而exactly once则只保存一次,没有重复。
一般在消费者端实现exactly once是通过设置唯一键,Kafka也可以通过设置唯一标识对应每一条数据,这种方式是
幂等性
(简单理解为:多次操作,结果是一致的)。
高吞吐
Kafka可以作为生产者和消费者之间的缓冲区,生产和消费的速度就可以不一致了。消费者的吞吐能力差的时候,可以将数据积压到Kafka,慢慢消费。
伸缩性
这个其实也和高吞吐有关,Kafka可以动态扩容,通过增加分区或者增加消费者,提高吞吐能力。
解耦&集成
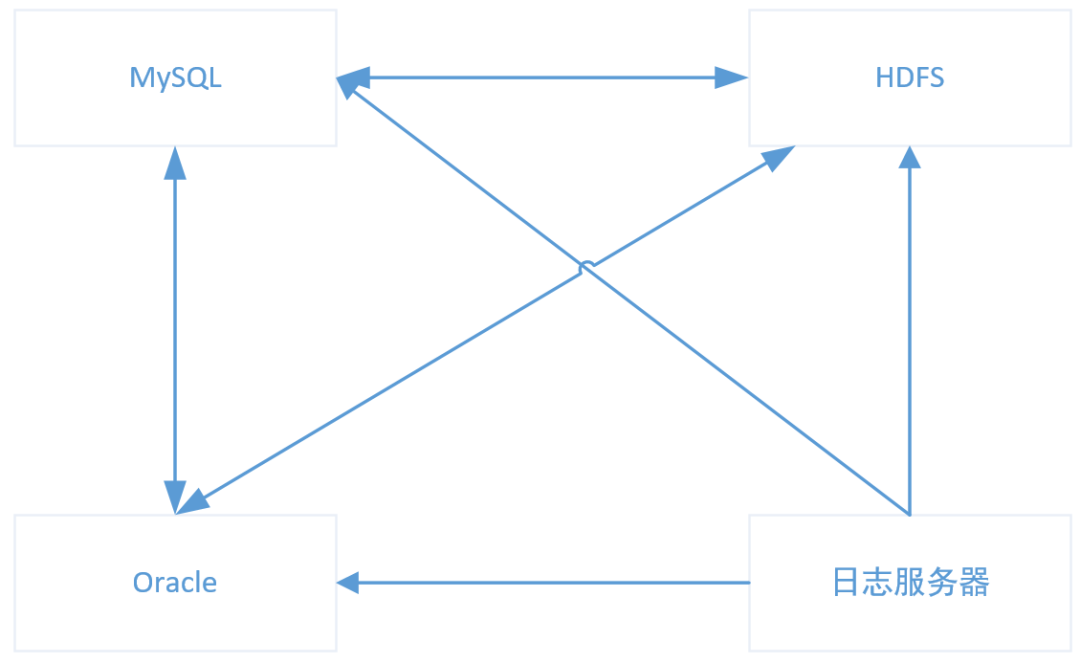
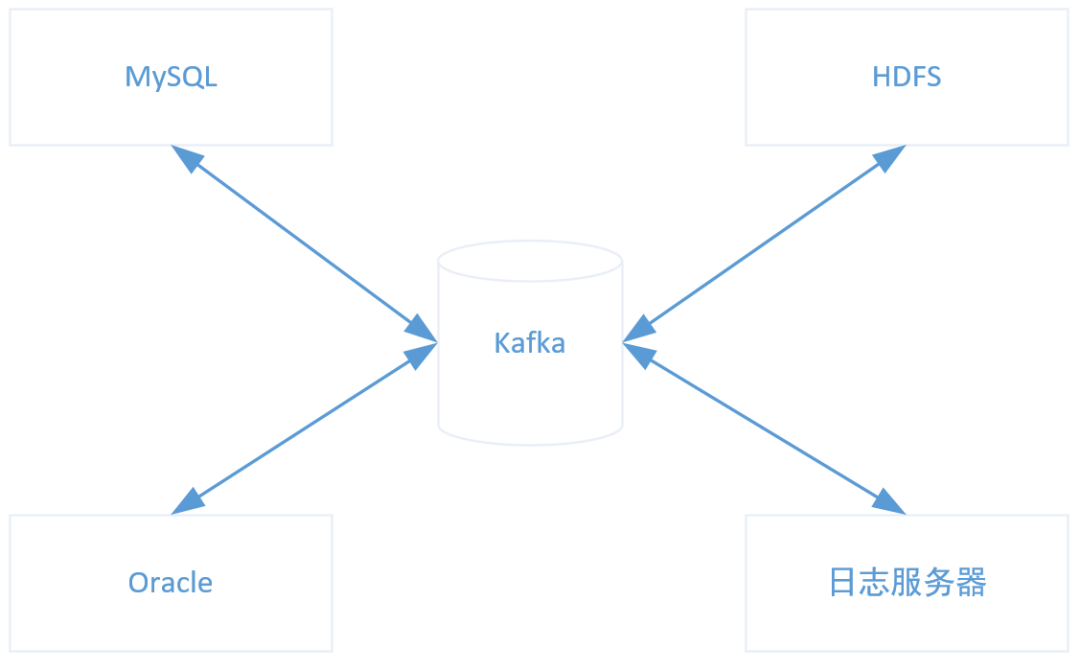
大数据处理的过程中,不管是源端还是目标端都有很多,经常需要将日志导入HDFS,或者从MySQL导数到Oracle,如果每个流程都建一条链路,会变得难以维护,而且有可能造成重复开发。
引入Kafka,可以解耦生产者和消费者,同时可以将多源异构的数据集成起来,就可以减少重复开发,提高效率。
总结
Kafka由于其具有批流一体、可靠性、可用性、解耦、伸缩性、高吞吐的特性,使其在大数据领域应用十分广泛,常作为数据总线,多用于数据采集以及数据服务。
大数据
大数据
文章转载自
大数据的奇妙冒险
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨