




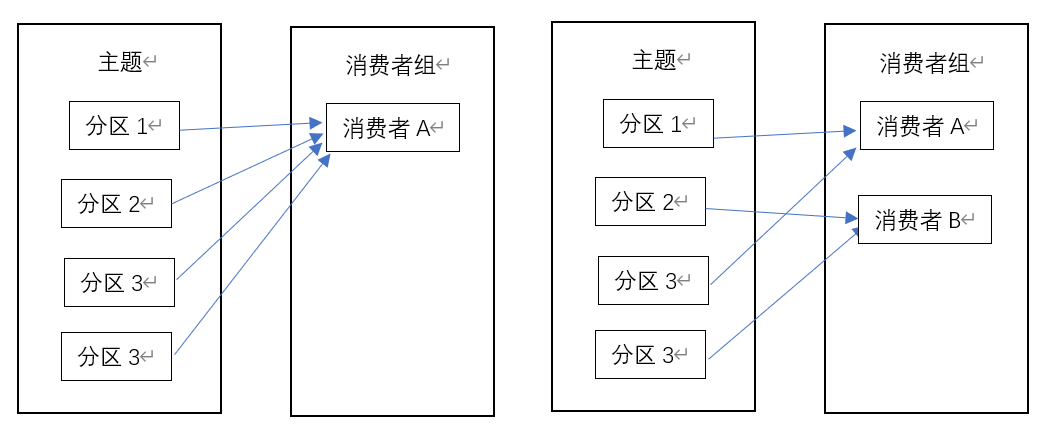
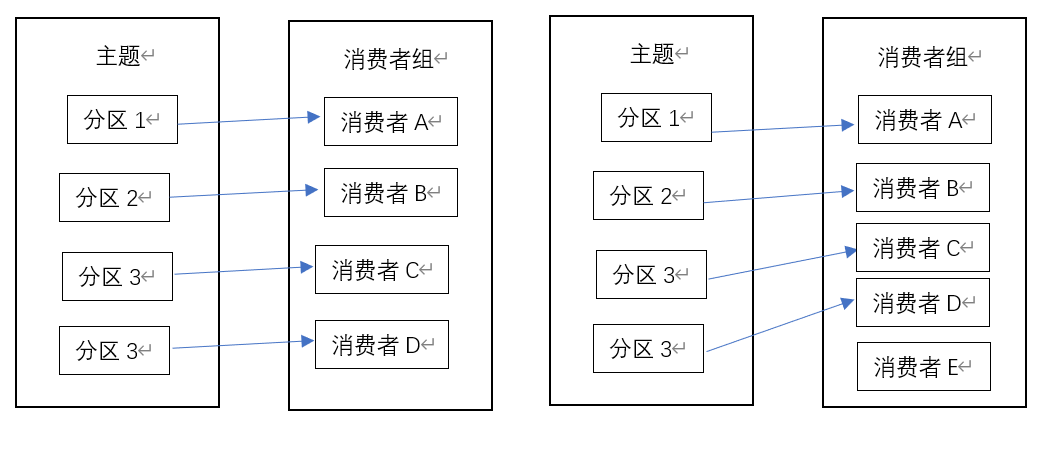
消费者与消费者组
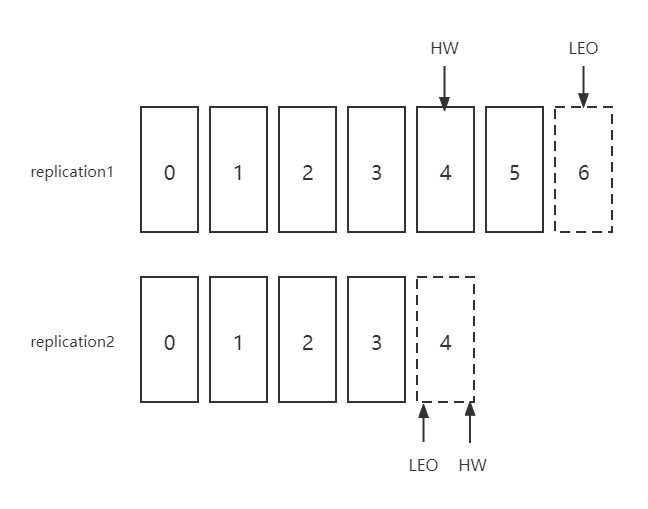
LEO & HW
提交偏移量
1、自动提交
2、通过CommitSync()方法手动提交当前偏移量
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
try{
consumer.commitSync();
} catch(Exception e){
log.error(e);
}
}复制
3、异步提交
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync();
}复制
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(), record.offset(),record.partition());
}
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e){
if(e != null){
log.error("Error");
}
}
});
}复制
4、异步与同步组合提交
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for(ConsumerRecords<String, String> record: records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
}
consumer.commitAsync();
}
}catch(Exception e){
log.error(e);
}finally {
try {
consumer.commitSync();
}
finally{
consumer.close();
}
}复制
5、提交特定偏移量
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();
int count = 0;
try {
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (records.isEmpty()){
continue;
}
for (ConsumerRecord<String, String> record : records){
System.out.println("topic=%s, offset=%s,partition=%s",
record.topic(),record.offset(),record.partition());
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset(), "no metadata"));
// 每处理完1000条消息后就提交偏移量
if (count%1000==0) {
consumer.commitAsync(currentOffsets, null);
}
count++;
}
}
} finally {
try{
consumer.commitSync();
} finally{
consumer.close();
}
}复制
消费者分区分配策略
Range 范围分区
假设现在有10个分区,消费者组里有3个消费者。
分区数量 10 除以消费者数量 3 取整(10/3)得 3,设为 x;分区数量 10 模 消费者数量 3(10%3)得 1,设为 y
则前 y 个消费者分得 x+1 个分区;其余消费者分得 x 个分区。
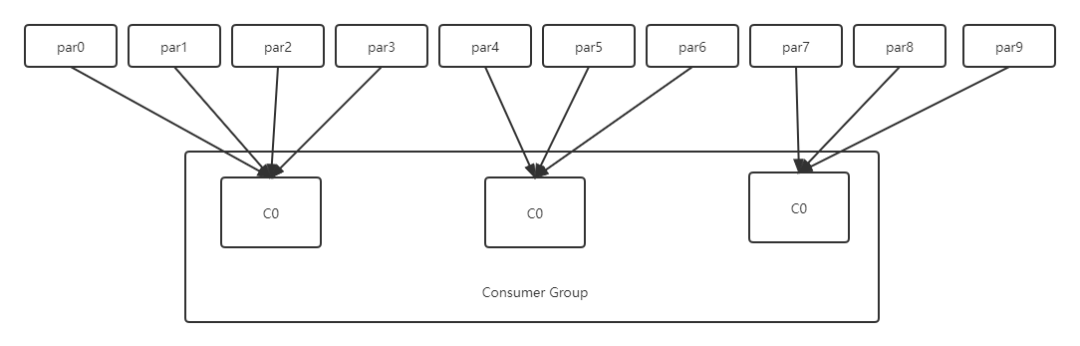
RoundRobin 轮询分区
假设有10个分区,3个消费者,第一个分区给第一个消费者,第二个给第二个消费者,第三个分区给第三个消费者,第四个给第一个消费者... 以此类推
文章转载自大数据的奇妙冒险,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
