







点击上方 蓝字关注我们
HOW TO FIND YOUR FRIENDLY NEIGHBORHOOD: GRAPH ATTENTION DESIGN WITH SELF-SUPERVISION
Link: https://openreview.net/pdf?id=Wi5KUNlqWty
Authors: Dongkwan Kim & Alice Oh KAIST, Republic of Korea
Code: https://github.com/dongkwan-kim/SuperGAT

摘要
图神经网络中的注意力机制旨在将较大的权重分配给重要的邻居节点,以实现更好的表示。但是,人们对图的学习了解得不好,尤其是当图嘈杂时。在本文中,作者提出了一种自监督图注意力网络(SuperGAT),这是一种针对noisy图改进的图注意力模型。
自监督的关键是找到数据中存在的监督信息,其中预测边存在和不存在是一个能够编码节点之间关系的监督信息,也被广泛的使用。本文利用这个与自监督任务兼容的两种注意力形式来预测边的存在和缺失。
提出的SuperGAT通过对边进行编码,在区分错误link的邻居时会获得更多的表达注意。另外本文发现两个图上的基本属性会影响注意力的形式和自监督的有效性:同构和平均度(homophily and average degree)。这两个图的属性,可为使用哪种注意力设计提供指导。
本文对17个现实世界数据集进行的实验表明,该方法可以泛化到其中的15个数据集,并且得到比基线更高的性能。
Introduction和Motivation
图神经网络(GNN)通过聚集中心节点的邻居特征来生成中心节点的特征,从而获得了显着的性能提升。但是,现实世界中的图通常在不相关的节点连接时会有噪声,这使GNN学习了次优的表示。图注意力网络(GAT)通过注意力机制来缓解这一问题。GAT在节点分类中显示出性能上的改进,但是它们在整个数据集上的改进程度不一致,并且对图的注意力实际学习的知识很少。因此,图的注意力仍然有提高的空间。
本文首先通过自监督注意力来评估和学习每个节点的重要性。进一步,观察到:如果图上节点i和j链接在一起,则它们彼此之间的关联度更高;如果节点i和j没有链接,则它们彼此之间的重要性就不重要。然后,本文使用注意力值作为输入来预测节点之间存在边的可能性作为辅助的监督信息。为了对图注意力中的边进行编码,作者首先分析图注意力学到的东西以及它与边存在之间的关系。在此分析中,作者将重点放在两种常用的注意力机制上,即GAT的原始单层神经网络(GO)和点积(DP),作为提出的模型的构建块。观察到,在预测与注意力值联系的任务中,DP注意力表现出比GO注意力更好的性能。另一方面,在捕获目标之间的标签一致时,GO的注意力要优于DP的注意力。
根据上面的分析,作者提出了SuperGAT的两个变体,scaled dotproduct(SD)和 mixed GO and DP (MX),以强调GO和DP的强度。然后,哪个图注意力可以最好地建模关系重要性并产生最佳的节点表示形式?作者发现它取决于图的平均度和同构性。于是通过生成具有不同度和同构性的合成图数据集,分析注意力如何影响节点分类性能。基于此结果,提出了一种通过边自监督来设计图注意力的方法,该方法对于给定的图属性最有效。代码已经公开:
https://github.com/dongkwan-kim/SuperGAT
Methodology
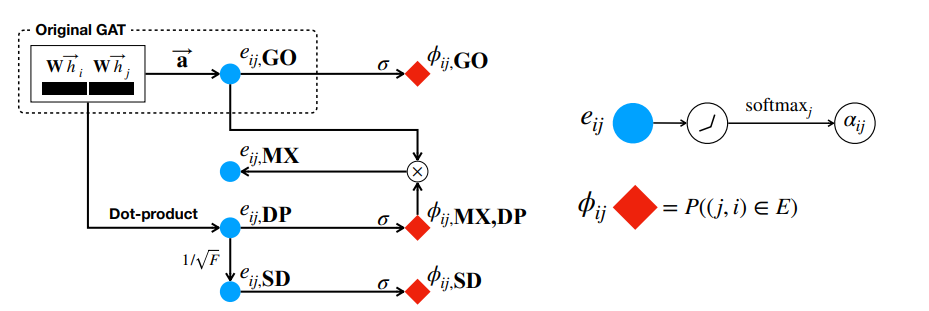
本文的方法可以从上面的图看到,
(1) e_ij DP, DP: dot product, 即把原来GAT出来的一对向量进行点乘
(2) e_ij SD, SD: scaled dotproduct, 即把e_ij DP除以a square root of dimension, 这样可以防止在softmax时一些较大的值主导整个注意力
(3) e_ijMX, MX(mixed GO and DP)原来GAT出来的向量对(GO)与DP进行点乘
进一步经过激活函数,得到ij的对应的三种链接概率也就是上面red diamonds所表示的内容~这些概率用来进行自监督学习。正样本天然存在,负样本的话如果节点非常多就需要采样了(However, if the number of nodes is large, it is not efficient to use all possible negative cases. So, we use negative sampling as in training word or graph embeddings)
最终的方法是在GAT中添加了关于边预测的损失函数
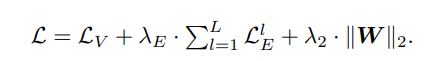
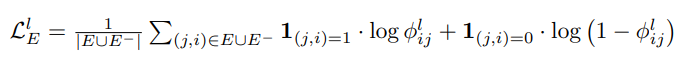
实验分析与讨论
本文在试验上进行了大量的分析,提出了四个问题,并一一回答
RQ1. Does graph attention learn label-agreement?
首先,作者评估在没有边监督的情况下,GAT-GO和GAT-DP的图注意学习的内容。我们知道,在深层的图网络中,连接的节点将收敛到相同的值,因为oversmoothing。如果在具有不同标签的节点之间存在边,那么多层的GAT是很难进行区分;换一句话说,理想状况下的注意力应该放到 label-agreed neighbors。从这个意义上讲,作者选择label-agreement between nodes as ground-truth评估谁学的好. 具体来说,作者通过label-agreement and graph attention based on Kullback–Leibler divergenc进行比较提出方法到底有没有学到label-agreement?
实验结果表明:GO learns label-agreement better than DP
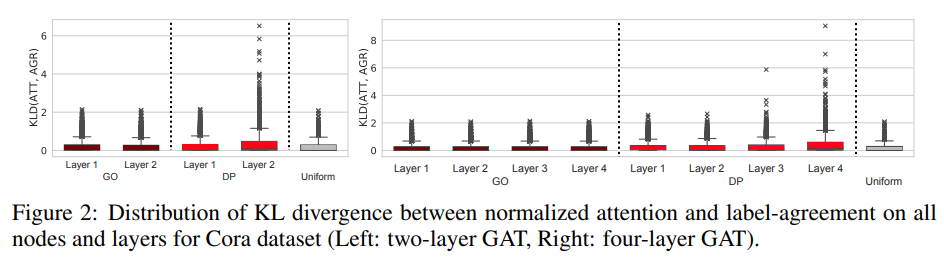
在图2中绘制了GO和DP注意的两层和四层GAT的注意力和标签分布之间的KL散度的箱形图,Cora数据集。首先咱们先看一下每个子图的最右侧,是uniform attention,最一般的形式。需要注意的是,由于节点度不同,所以每个节点的KLD的最大值也不同。KLD分布呈长尾状,类似于真实世界图的度分布。
关于KLD的分布有三点观察。首先,观察到GO的KLD分布与所有引文数据集的uniform 注意力模式相似。这意味着受过训练的GO注意类似于均匀分布。其次,对于最后一层,DP的KLD值倾向于大于GO注意的KLD值,从而导致更大的长尾。学习的DP注意分布与标签一致分布之间的这种不匹配表明DP注意没有学习附近的标签一致。第三,模型越深,最后一层中DP注意的KLD值越大。
RQ2. Is graph attention predictive of edge presence?(注意力能预测边吗?)
为了评估SuperGAT中边信息的编码程度,作者使用最后一层的φij作为预测变量,使用SuperGAT-GO和SuperGAT-DP进行链接预测实验
实验结果表明:DP predicts edge presence better than GO
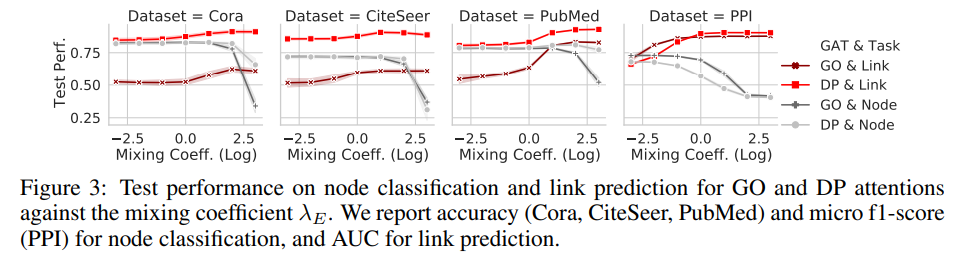
在图3中,作者报告了链接预测(红线)和节点分类(灰线)的多次运行的平均AUC(PPI为5,其他为10)。随着混合系数λE的增加,链接预测得分在所有数据集中和注意力中都增加,λE是自监督图注意力权重因子。在实验中,对于四分之三的数据集,DP注意力在所有λE范围上的表现都优于GO。令人惊讶的是,即使对于较小的λE,DP的注意力也显示为80 AUC,远远高于GO的表现。PPI是一个例外,GO注意力显示较小的λE比显示DP具有更高的性能,但差异很小。该实验的结果表明,在编码边时,DP注意力比GO注意力更合适。
RQ3. Which graph attention should we use for given graphs?
以上两个问题探讨了在有或没有自监督存在的情况下,不同的图注意力机制学到了什么。那么,对于给定的图,哪一种图注意有效?
作者在各种图统计数据中选择同构和平均度这两个属性,因为它们决定了自监督任务中标签的质量和数量。从带有边标签的图注意力的监督学习的角度来看,学习结果取决于嘈杂的标签有多大(即同质性低)和存在多少个标签(即平均度有多高)。因此,作者生成了144个合成图(第4.1节),分别控制9个同构图(0.1 – 0.9)和16个平均度(1 – 100),并使用GCN,GAT-GO,SuperGAT-SD和SuperGAT-MX在不同的环境中执行节点分类任务。
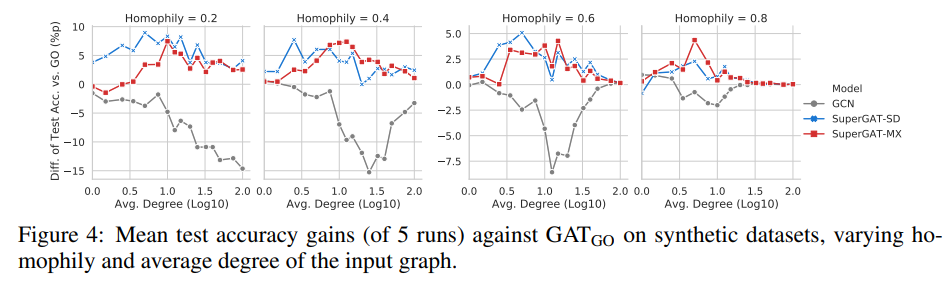
实验表明:It depends on homophily and average degree of the graph.
从该图4中得出以下观察结果。首先,如果同质性较低(≤0.2),则SuperGAT-SD在模型中表现最佳,因为DP的注意力往往集中在少数邻居身上。其次,即使同质性较低,SuperGAT对GAT的性能增益也会随着平均度增加到一定水平(大约10),这意味着关系建模可以受益于自监督是否有足够多的边提供监督。第三,如果平均度和同构性足够高,所有模型(包括GCN)之间没有区别。如果还有超过一定数量的正确边,我们可以学习精细表示而无需自监督。最重要的是,如果平均程度不太低或太高且同构性高于0.2,则SuperGAT-MX的性能将优于或类似于SuperGAT-SD。这意味着我们可以通过混合GO和DP来同时利用GO注意来学习标签一致性和DP注意来学习边存在。
RQ4. Does design choice based on RQ3 generalize to real-world datasets?
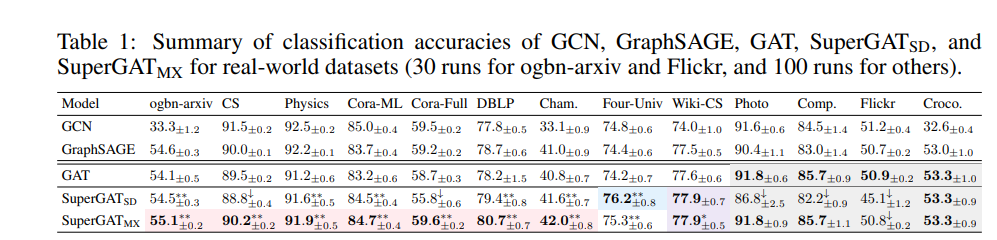
It does for 15 of 17 realworld datasets,具体看下面的实验结果,

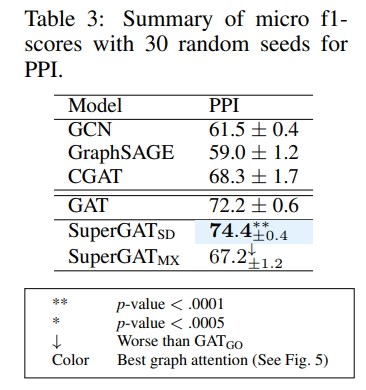
结论
本文提出了新的图神经体系结构,以根据输入图的属性设计自监督注意力。作者首先评估图注意力,并分析了边自监督对链接预测和节点分类性能的影响。该分析表明,两种广泛使用的注意力机制(原始GAT和点积)难以同时编码标签一致性和边存在。为了解决这个问题,提出了几种图表注意形式来平衡这两个因素,并认为应该根据输入图的平均度和同构性来设计图注意力。

