





基于样式的生成对抗网络
——styleGAN ——
01
研究背景
什么是GANs?
GANs简单的想法就是用两个模型,一个生成模型,一个判别模型。判别模型用于判断一个给定的图片是不是真实的图片(从数据集里获取的图片),生成模型的任务是去创造一个看起来像真的图片一样的图片。而在开始的时候这两个模型都是没有经过训练的,这两个模型一起对抗训练,生成模型产生一张图片去欺骗判别模型,然后判别模型去判断这张图片是真是假,最终在这两个模型训练的过程中,两个模型的能力越来越强,最终达到稳态。
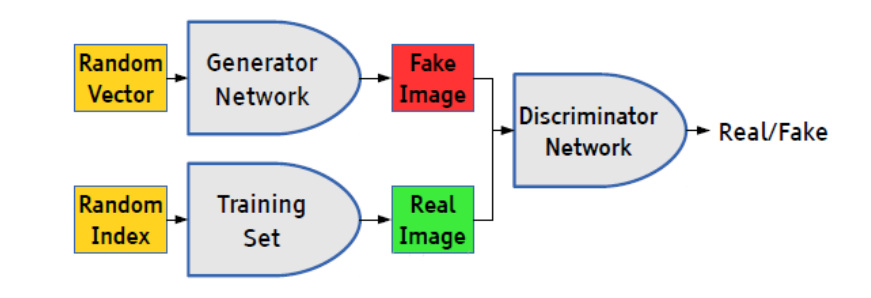
例如我们现在的数据集是手写数字数据集minst,生成模型的输入可以是二维高斯模型中一个随机的向量,生成模型的输出是一张伪造的 fake image,同时通过索引获取数据集中的真实手写数字图片real image,然后将 fakeimage 和 real image 一同传给判别模型,由判别模型给出 real 还是fake 的判别结果。于是,一个简单的 GANs 模型就搭建好了。值得注意的是,生成模型G和判别模型D可以是各种各样的神经网络,对抗网络的生成模型和判别模型没有任何限制。
计算机视觉中的GANS本质是在做啥呢?

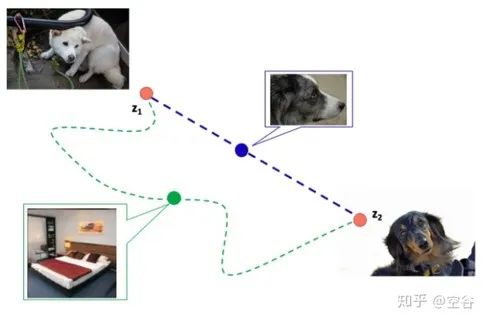
我们假设把每一个图片看作二维空间中的一个点,并且现有图片会满足于某个数据分布。以人脸举例,在很大的一个图像分布空间中,实际上只有很小一部分的区域是人脸图像。如上图所示,只有在蓝色区域采样出的点才会看起来像人脸,而在蓝色区域以外的区域采样出的点就不是人脸。我们需要做的,就是让机器去找到人脸的分布函数。具体来说,就是我们会有很多人脸图片数据,我们观测这些数据的分布,大致能猜测到哪些区域出现人脸图片数据的概率比较高,但是如果让我们找出一个具体的定义式,去给明这些人脸图片数据的分布规律,我们是没有办法做到的。但是如今,我们有了机器学习,就可以通过机器去学习到这样一个分布规律,并能够给出一个极致贴合的表达式。
StyleGAN 的前身——ProGAN
ProGAN是一种渐进增长式GAN,训练开始于有着一个4×4 像素的低空间分辨率的生成器和判别器。随着训练的改善,我们逐渐向生成器和判别器网络中添加层,进而增加生成图片的空间分辨率。所以它的网络结构是在动态变化的,这是有别于其它GANs的部分,可以提高训练高分辨率图像速率。
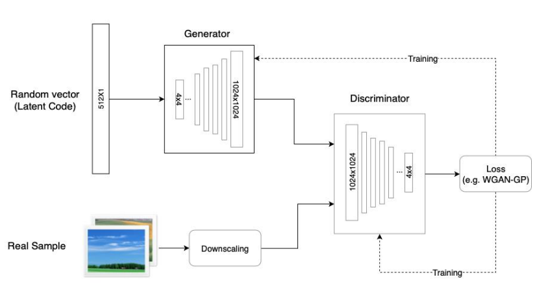
由于 ProGAN是逐级直接生成图片,我们没有对其增添控制,我们也就无法获知它在每一级上学到的特征是什么,这就导致了它控制所生成图像的特定特征的能力非常有限,存在很高的特征纠缠。这些特性是互相关联的,只要调整一下输入,通常也会同时影响多个特性。

所以我们希望有一种更好的模型,能让我们控制住输出的图片是长什么样的,也就是在生成图片过程中每一级的特征,要能够特定决定生成图片某些方面的表象,并且相互间的影响尽可能小。
02
模型、方法及结果
于是,一种基于样式的生成对抗网络出现了——StyleGAN。StyleGAN是NVIDIA继ProGAN之后提出的新的生成网络,其主要通过分别修改每一层级的输入,在不影响其他层级的情况下,来控制该层级所表示的视觉特征。

StyleGAN有以下几点改进和创新:
映射网络
样式模块
删除传统输入
随机变化
样式混合
在W中的截断技巧
两种新的量化隐空间耦合度的方法

映射网络
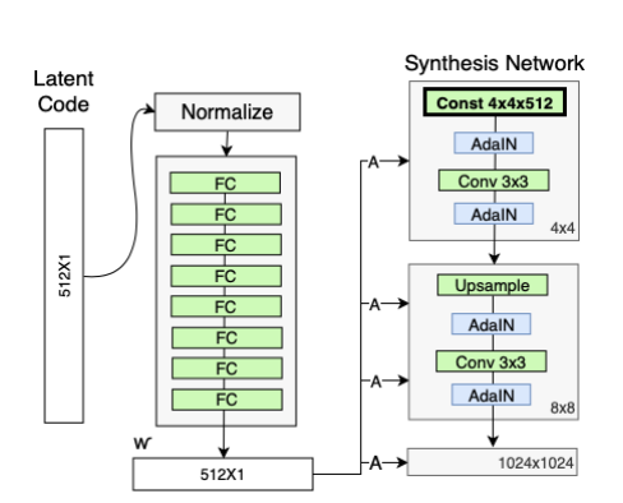
StyleGAN的第一点改进是,给生成器的输入加上了由8个全连接层组成的映射网络,映射网络的输出𝑊′与输入层(512×1)的大小相同。添加映射网络的目标是将输入向量编码为中间向量,并且中间向量后续会传给生成网络得到18 个控制向量,使得该控制向量的不同元素能够控制不同的视觉特征。
如果不加映射网络的话,后续得到的18 个控制向量之间会存在特征纠缠的现象——比如说我们想调节8*8 分辨率上的控制向量(假设它能控制人脸生成的角度),但是我们会发现 32*32 分辨率上的控制内容(譬如肤色)也被改变了,这个就叫做特征纠缠。所以MappingNetwork 的作用就是为输入向量的特征解缠提供一条学习的通路
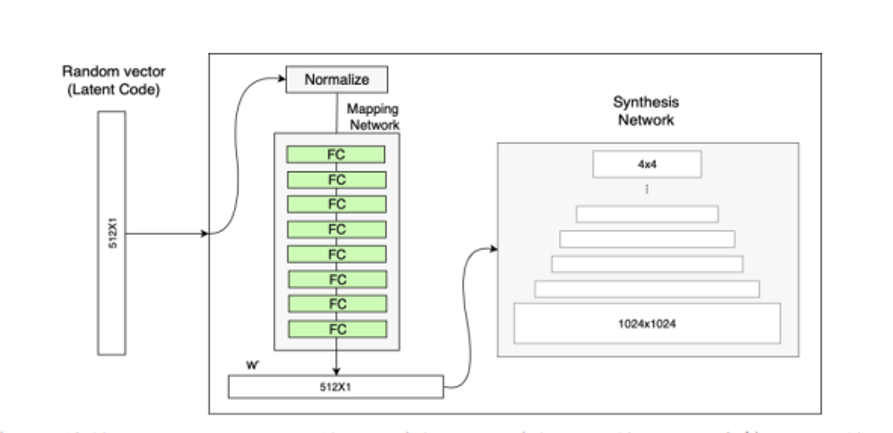
为什么映射网络能够学习到特征解缠呢?简单来说,如果仅使用输入向量来控制视觉特征,能力是非常有限的,因此它必须遵循训练数据的概率密度。例如,如果黑头发的人的图像在数据集中更常见,那么更多的输入值将会被映射到该特征上。因此,该模型无法将部分输入(向量中的元素)映射到特征上,这就会造成特征纠缠。然而,通过使用另一个神经网络,该模型可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性(解耦、特征分离)
样式模块
StyleGAN 的第二点改进是,将特征解缠后的中间向量𝑊′变换为样式控制向量,从而参与影响生成器的生成过程
生成器由于从4*4变换到 8*8,并最终变换到1024*1024,所以它由9 个生成阶段组成,而每个阶段都会受两个控制向量(A)对其施加影响,其中一个控制向量在Upsample 之后对其影响一次,另外一个控制向量在Convolution之后对其影响一次,影响的方式都采用AdaIN(自适应实例归一化)。因此,中间向量𝑊′总共被变换成18个控制向量(A)传给生成器。
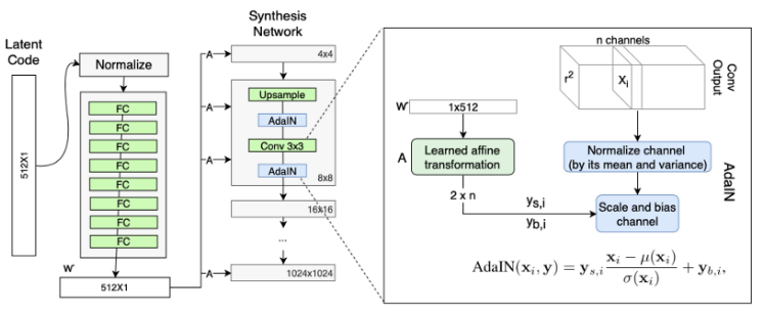
其中 AdaIN的具体实现过程如上右图所示:将𝑊′通过一个可学习的仿射变换(A,实际上是一个全连接层)扩变为放缩因子y𝑠,𝑖与偏差因子y𝑏,𝑖,这两个因子会与标准化之后的卷积输出做一个加权求和,就完成了一次𝑊′影响原始输出x𝑖的过程。而这种影响方式能够实现样式控制,主要是因为它让𝑊′(即变换后的y𝑠,𝑖与y𝑏,𝑖)影响图片的全局信息(注意标准化抹去了对图片局部信息的可见性),而保留生成人脸的关键信息由上采样层和卷积层来决定,因此𝑊′只能够影响到图片的样式信息。
删除传统输入
既然 StyleGAN 生成图像的特征是由𝑊′和AdaIN 控制的,那么生成器的初始输入可以被忽略,并用常量值4*4*512替代。这样做的理由是,首先可以降低由于初始输入取值不当而生成出一些不正常的照片的概率(这在GANs 中非常常见),另一个好处是它有助于减少特征纠缠,对于网络在只使用𝑊′不依赖于纠缠输入向量的情况下更容易学习。
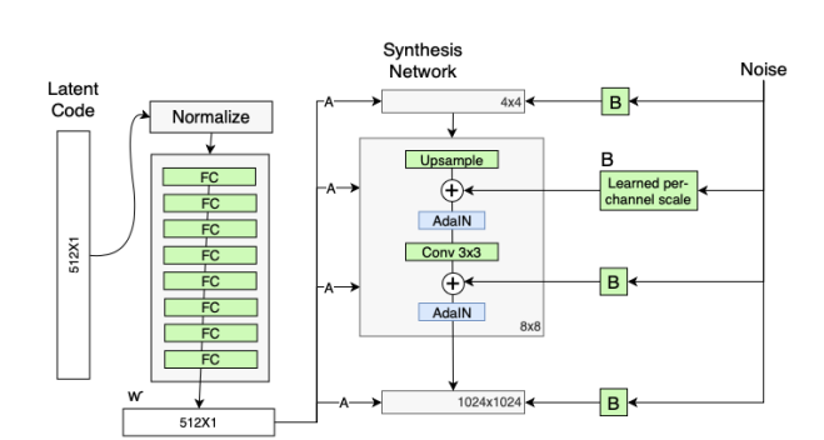
随机变化
人们的脸上有许多小的特征,可以看作是随机的,例如:雀斑、发髻线的准确位置、皱纹。将这些小特征插入 GAN 图像的常用方 法是在输入向量中添加随机噪声,然后通过输入层输入生成器。然而,在很多情况下,控制噪声效果是很棘手的,因为特征纠缠现象,略微改变噪声会导致图像的其他特征受到影响。
于是,该架构通过在合成网络的每个分辨率级上增加尺度化的噪声来回避这些问题。噪声是由高斯噪声组成的单通道图像,将一个噪声图像提供给合成网络的一个特征图。在卷积之后、AdaIN之前将高斯噪声加入生成器网络中。B使用可学习的缩放参数对输入的高斯噪声进行变换,然后将噪声图像广播到所有的特征图中(分别加到每个特征图上)。加入噪声后的生成人脸往往更加逼真与多样。
样式混合
StyleGAN 生成器在合成网络的每个级别中使用了中间向量,这有可能导致网络学习到这些级别是相关的。为了降低相关性,模型随机选择两个输入向量(潜码)z1,z2通过映射网络,并生成相应的 w1,w2 控制样式, w1在某个交叉点之前应用,w2 在交叉点之后应用--称之为样式混合操作。随机的切换确保了网络不会学习并依赖于一个合成网络级别之间的相关性。
这种操作会产生一种有趣的现象--它能够以一种连贯的方式来组合多个图像。如图,该模型生成了两个图像 A 和B,然后通过从 A 中提取低级别的特征并从B 中提取其余特征再组合这两个图像,这样能生成出混合了 A 和B 的样式特征的新人脸。

两种新的量化隐空间耦合度的方法
一、感知路径长度
Perceptual path length 是一个指标,用于判断生成器是否选择了从当前分布到目标分布中的最短迁移路径。
二、线性可分性
如果潜在空间被充分解开,则应该可以找到始终与各个 变化因素相对应的方向向量。我们提出了另一个度量,通过测量潜在空间点通过线性超平面分成两个不同的集合的程度 来量化这种效应,以便每个集合对应于图像的特定二进制属性。
实验结果
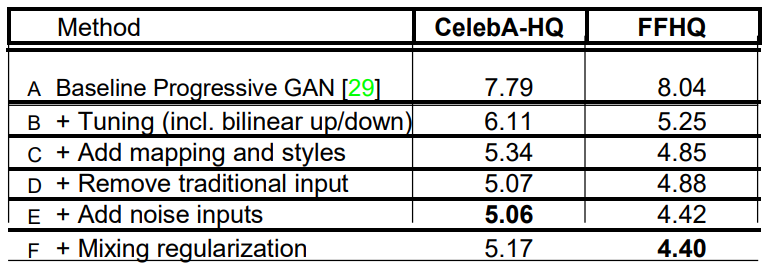
各种生成器设计的 Frechet'起始距离(FID)(越低越好)。在本文中,我们使用从训练集中随机抽取的 50,000 张图像来计算FID,并报告在训练过程中遇到的最低距离。

在我们的生成器的不同层的噪声输入的影响。(a)噪音适用于所有层。( b ) 没 有 噪 音 。( c )仅有精细层的噪音(64*64-1024*1024 )。(d)仅粗糙层的噪音(4*4-32*32 )。我们可以看到,人为地忽略噪音会导致无意义的“绘画”外观。粗糙的噪音会导致头发大规模卷曲和出现更大的背景特征,而细微的噪音则会带来更精细的头发卷曲,更细致的背景细节和皮肤毛孔。

随机变化的例子。(a)两个生成的图像。(b)放大输入噪声的不同实现。虽然整体外观几乎相同,但个别毛发的放置方式却截然不同。(c)100 个不同实现中每个像素的标准偏差,突出显示图像的哪些部分受到噪声的影响。主要区域是头发,轮廓和背景的一部分,但眼睛反射也有有趣的随机变化。身份和姿势等全局方面不受随机变化的影响。
03
代码复现
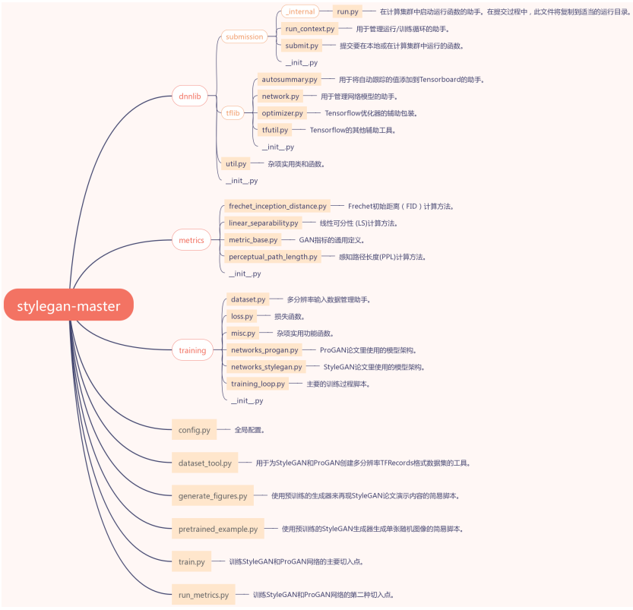
styltGAN代码架构
10000张超模人脸数据集训练

16x16分辨率

32x32分辨率

64x64分辨率

128x128分辨率

256x256分辨率

512x512分辨率

1024x1024分辨率
也可以训练动漫头像噢~

• end •

