




引言
现有的基于FPGA的图处理加速器,通常都是为静态图设计的,而鲜少有工作利用FPGA来加速处理动态图。然而实际上,在现实世界中,图数据常常会随着时间而变化,这样的图数据被称为动态图。为了加速动态图的图处理性能,本文旨在利用FPGA这一硬件来加速动态图的图更新过程。本文通过动态图更新中存在着的空间相似性,设计了一个名为GraSU的FPGA库,其利用了这种空间相似性来进行快速的图更新。GraSU采用差异化的数据管理,将高价值数据保存在片上UltraRAM中,将绝大多数低价值数据驻留在片外存储中,从而将大量的片外通信转换为快速的片上内存访问,从而提高了访存性能。下面,我们就带大家了解一下这篇文章是如何在FPGA上实现动态图框架的。

·· 一、背景与动机 ··
图处理已被广泛用于各个领域的数据分析:例如:社交网络分析、财务欺诈检测、冠状病毒传播跟踪等等。而近年来,使用硬件加速图处理的性能已经被证明是一种行之有效的策略。而FPGA,有着细粒度的并行性、低功耗和灵活的可配置性,是一种优秀的图处理硬件。不过目前大多数的基于FPGA的图加速器都是为处理静态图而设计的,但是现实世界的图通常是以动态图的形式呈现的,这些图会随着时间而变化,例如twitter。对于处理一个动态图,通常是两个核心操作:图更新和图计算的迭代过程,如图1所示。图更新是通过对一个顶点或边进行添加或删除操作来修改一个图快照,从而生成一张新图。图计算则是在新图上执行图算法,提取有用的信息。FPGA上的图算法已经得到了广泛的研究,而基于FPGA的图更新加速器设计仍是一片空白。作为动态图处理过程中的重要一环,图更新的效率至关重要。缓慢的图更新会导致在过时的图上执行图计算,从而产生不准确甚至是无用的分析结果。

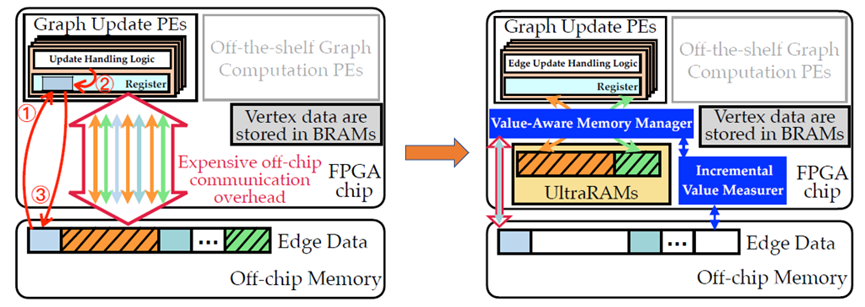
如图2左图所示,使用传统的基于FPGA的图加速器框架实现的图更新框架,顶点通常存储在片上BRAM中,而边数据存储在片外存储上(通常是DRAM)。在这种框架下,图更新操作一般分为三个基本步骤:第一,读取待更新边的源顶点索引,从片外存储加载边表并存储到与PE(图更新处理引擎)相连的寄存器中;第二,将更新的边添加到边表中(或从边表中删除);第三,将边表写回到片外存储。这种图更新处理框架的性能受限于过多的片外通信,因为真实场景下可能存在大量的边更新,使得片外存储上的边数据被PE重复地访问。而本文观察到,其实动态图更新过程中是呈现空间相似性的,即大多数随机访存只与几个顶点的边有关。因此本文重点利用FPGA上差异化的数据管理来将昂贵的片外通信开销转化为快速的片上内存访问。对于每一个顶点,用变量值value来衡量其价值,对于每一批图更新,高价值顶点相关的边数据驻留在片上UltraRAM [1]中,大部分低价值顶点相关的边数据存储在片外,如图2右图所示。而要实现差异化的数据管理,本文需要着重解决两个问题:其一,由于动态图是不断变化的,需要设计一个可以有效衡量value值的策略;其二,由于边数据被分别保存在片上和片外两种存储中,需要设计新的数据寻址机制,保证在FPGA上的时间和空间效率。
如图3(a)所示,基于FPGA的动态图更新库GraSU的系统框架主要分为五个模块:
动态图组织(Dynamic Graph Organization):本文采用大多数动态图系统使用的PMA [2]格式存储动态图数据,其好处是可以快速地更新,其带来的代价是PMA满了之后的重组。为了防止一个PMA段内包含不同价值级别的边,本文强制每个PMA段只包含一个顶点的边,如图3(c)所示。而由于FPGA不能有效地支持动态内存分配[4],因此本文通过预先分配多余内存空间来实现逻辑上的PMA空间翻倍。
增量价值测量器(Incremental Value Measurer, IVM):IVM模块负责为图更新量化每个顶点的value值,并进一步通知价值感知内存管理器(Value-Aware Memory Manager, VMM),将高价值顶点的边分配到片上UltraRAM中。由于数据值是动态变化的,IVM采用基于图更新历史的增量价值测量,不断提高测量精度。每完成一批图更新时,都会调用IVM模块。
边更新调度(Edge Update Dispatcher, EUD):当高价值数据已经保存在片上UltraRAM中时,EUD模块启动。它会从片外存储中读取一批边更新,并根据每个边更新的时间戳顺序,将它们有序地分发到适当的PE中去。
更新处理逻辑(Update Handling Logic, UHL):UHL模块确保每个边更新都能正确添加或从边数组中删除。UHL是一个三阶段流水设计,包括读边、更新边和写边,如图3(b)所示。读阶段通过向VMM发送读请求来加载待更新边的边数据。然后,更新阶段执行具体的插入或删除操作。最后,写阶段将更新后的边数据通过VMM写回。
价值感知内存管理器(Value-Aware Memory Manager, VMM):VMM模块负责准确和高效地定位请求的边数据。而为了在内存空间开销和数据寻址效率之间取得良好的平衡,VMM采用了位图索引结构来减少空间开销,并使用位图辅助的寻址解析机制来支持快速而准确的差异化数据访问。当VMM模块接收到读请求时,VMM将获取源顶点的边数组地址作为初始的片上(或片外)地址。之后,VMM在边数据中定位目标段,将该段加载到UHL相应的寄存器中。当VMM模块接收到写请求时,根据目标段的地址,UHL关联的写缓冲区中的内容将被写回。
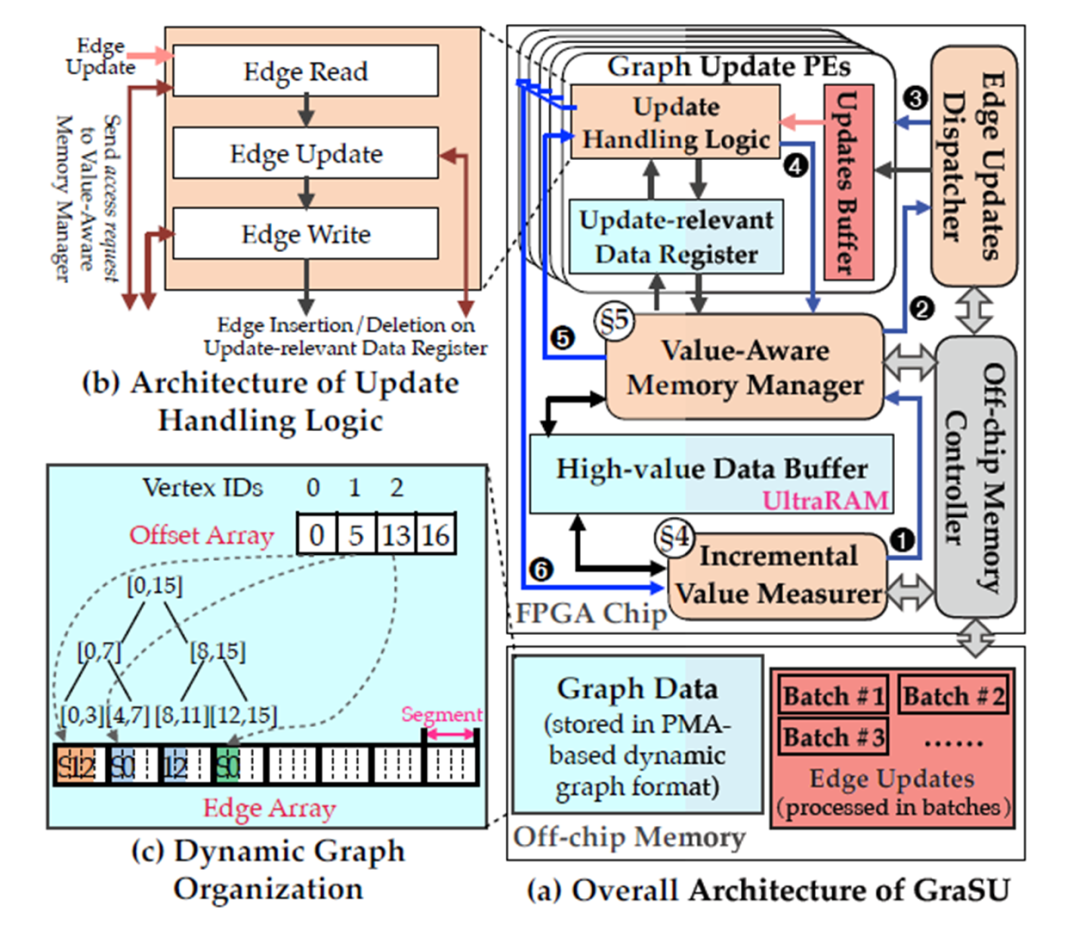
图3. GraSU系统框架
·· 三、关键技术 ··
本文要实现差异化的数据管理模式,两个关键的技术就是顶点价值的度量和边数据的寻址机制。
增量价值度量:根据“富者越富”[3]这种现象,量化顶点价值最直觉的方法是使用顶点的度数。这种方法的确有用,但准确性远低于理想情况。原因有两方面:其一,一些低度顶点随着更新批次的进行可能被插入很多边从而变成高度顶点,比如一个默默无闻的演员因为新作品而大火;其二,一些高度顶点的边的增长速度可能比其他顶点要慢,比如一个“超级传播者”被隔离后,病毒传播链被切断。这两种现象都表明了一个问题,那就是顶点的价值不仅取决于顶点目前的度数,还取决于其历史的更新频率。因此本文提出了如下的增量方法来量化一个顶点的价值 ,其中所有顶点的价值被初始化为其度数,然后根据其上一轮的更新次数进行增量修改。
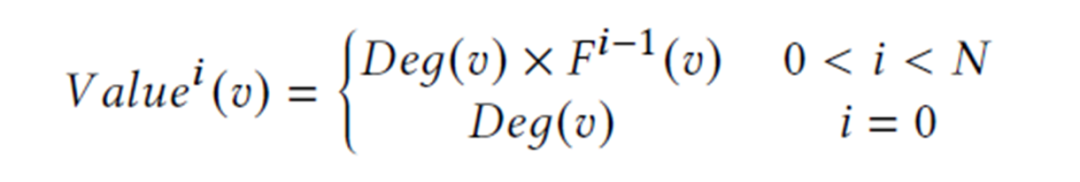
因此,测量一个顶点的价值需要得到顶点的度数和更新频率,而这两个值在图更新时是动态变化的,这会引入潜在的运行时开销。而由于动态图更新和图计算之间的交错性,可以将这个开销隐藏在图计算之中,因为图计算通常需要对顶点进行迭代计算[5],其执行时间会比价值测量的时间要长,如图4所示。
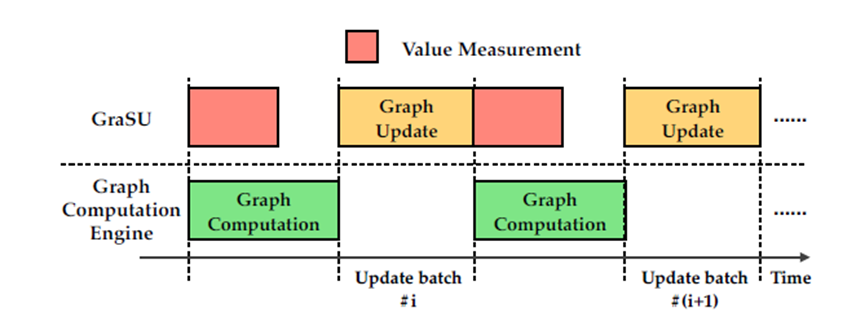
图4. 图计算与价值测量的重叠计算
价值感知内存访问:在设计如何访问高价值数据和低价值数据的机制之前,需要先确定哪些数据是高价值数据,应该被存储在UltraRAM上。GraSU的策略是在UltraRAM上存储尽可能多的高价值数据,因此高价值数据的计算如下所示:
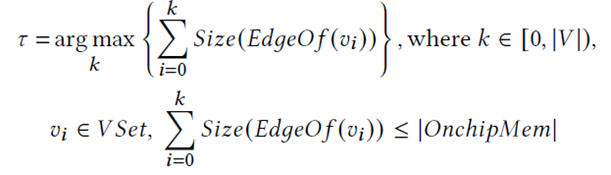
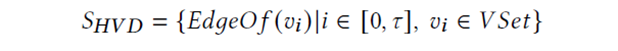
然后,本文提出了一种简单有效的基于位图索引的方法来进行内存寻址。如图5所示,位图中的每一位代表一个顶点,对应位为1代表该顶点的边数据存储在片上,为0代表该顶点的边数据存储在片外。当一个顶点的所有边数据加载到UltraRAM上时,它在位图中的位就被设置为1,并且其在偏移数组中的偏移值被修改为在UltraRAM中的新偏移值。当高价值数据需要被写回片外存储时,需要在偏移数组中计算它们原始的偏移值。具体来说,扫描位图找到需要被写回的顶点v后面第一个为0的顶点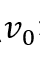 和第一个为1的顶点
和第一个为1的顶点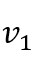 ,那么原始的偏移值:
,那么原始的偏移值:
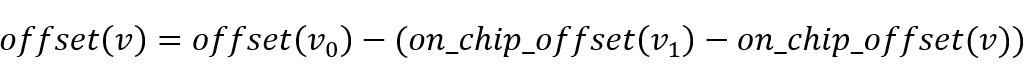
当处理读写请求时,通过位图可以定位其在片上(片外)的起始位置,对于在片上的高价值顶点,其度数可以直接通过与下一个顶点的偏移差得到,对于在片外的顶点,其度数需要计算下一个顶点的原始偏移值,再计算偏移差得到。
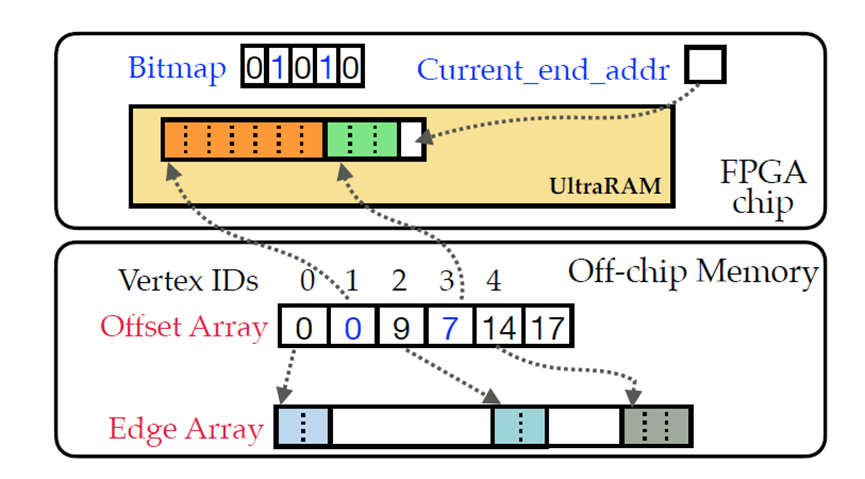
图5. 价值感知内存访问机制
在实验方面,本文使用了Xilinx的U250的FPGA加速卡,并配有64GB的DRAM作为片外存储,在AU,SU,WK,SO [6]和BC [7]五个真实世界动态图上进行实验,对标的基于CPU的动态图处理系统是Stinger和Aspen,测试的算法是BFS、PR和WCC。实验结果如图6和图7所示,图6比较的是图更新的效率,图7比较的是动态图处理整体的效率(包括图更新和图计算)。结果表明本文实现的GraSU系统可以取得更好的性能结果,更多的实验结果和分析可以参考原文。
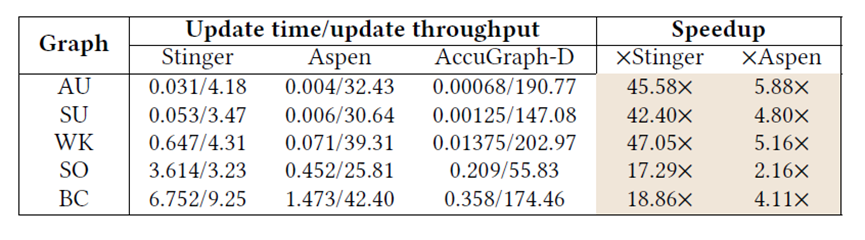
图6. 图更新性能对比
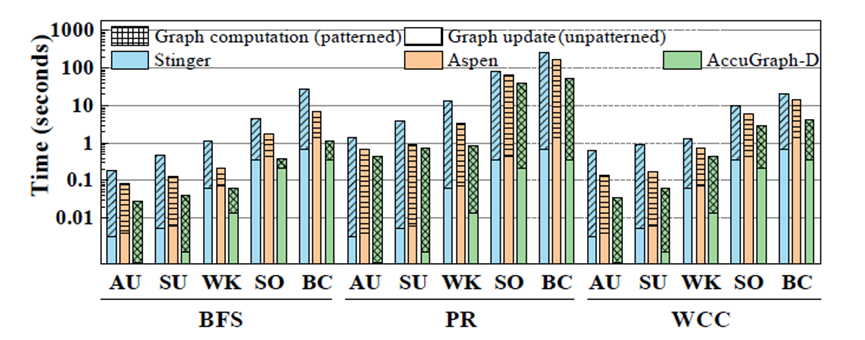
图7. 动态图处理性能对比
[1] Xilinx.2019. UltraScale Architecture Memory Resources UserGuide.https://www.xilinx.com/support/documentation/user_guides/ug573-ultrascalememory-resources.pdf.
[2] Mo Sha,Yuchen Li, Bingsheng He, and Kian-Lee Tan. 2017. Accelerating Dynamic GraphAnalytics on GPUs. Proc. VLDB Endow. 11, 1 (2017), 107–120.
[3] RaviKumar, Jasmine Novak, and Andrew Tomkins. 2006. Structure and Evolution ofOnline Social Networks. In KDD. ACM, 611–617.
[4] Xilinx.2020. Vivado Design Suite User Guide High-Level Synthesis. https://www.xilinx.com/support/documentation/sw_manuals/xilinx2020_1/ug902-vivado-high-level-synthesis.pdf.
[5] LongZheng, Xianliang Li, Yaohui Zheng, Yu Huang, Xiaofei Liao, Hai Jin, Jingling Xue,Zhiyuan Shao, and Qiang-Sheng Hua. 2020. Scaph: Scalable GPU-Accelerated GraphProcessing with Value-Driven Differential Scheduling. In ATC. USENIX, 573–588.
[6] JureLeskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford Large Network DatasetCollection. http://snap.stanford.edu/data.
[7] Ryan A.Rossi and Nesreen K. Ahmed. 2015. The Network Data Repository with InteractiveGraph Analytics and Visualization. In AAAI. http://networkrepository. com
更多链接


