PostgreSQL数据库自动生成主键通常有如下几种方式:
- sequence序列
- serial和bigserial伪类型
- identity columns
- UUIDs
- BEFORE INSERT触发器
这些主键方式使用了两个基本的方法:序列和UUID算法。
这两种基本方法在其它数据库使用非常广泛,UUID更是在软件开发中作为最常用的通用标识符。
最近在github看到一个足可与UUID竞争的对手,它就是Nano ID。
下面是Nano ID的官网介绍:
https://github.com/ai/nanoid/blob/main/README.zh-CN.md
它是一个小巧、安全、URL友好、唯一的JavaScript字符串ID生成器。
Nano ID的特点
- 小巧. 130 bytes (已压缩和 gzipped), 没有依赖, Size Limit 控制大小。
- 快速. 它比UUID快两倍。
- 安全. 它使用硬件随机生成器,可在集群中使用。
- 紧凑. 它使用比UUID(A-Za-z0-9_-)更大的字母表。 因此,ID大小从36个符号减少到21个符号。
- 易用. Nano ID 已被移植到20种编程语言,包括C#、C++、Clojure and ClojureScript、ColdFusion/CFML、Crystal、Dart & Flutter、Deno、Go、Elixir、Haskell、Janet、Java、Nim、OCaml、Perl、PHP、Python with dictionaries、Ruby、Rust、Swift、Unison、V
与UUID的比较
Nano ID与UUID v4 (基于随机) 相当。 它们在 ID 中有相似数量的随机位 (Nano ID 为126,UUID 为122),因此它们的冲突概率相似:
要想有十亿分之一的重复机会, 必须产生103万亿个版本4的ID.
Nano ID 和 UUID v4之间有三个主要区别:
- Nano ID使用更大的字母表,所以类似数量的随机位被包装在21个符号中,而不是36个。
- Nano ID代码比uuid/v4 包少 4倍: 130字节而不是483字节。
- 由于内存分配的技巧,Nano ID 比 UUID 快两倍。
下面这个网址显示这两者之间npg的趋势
https://www.npmtrends.com/nanoid-vs-uuid
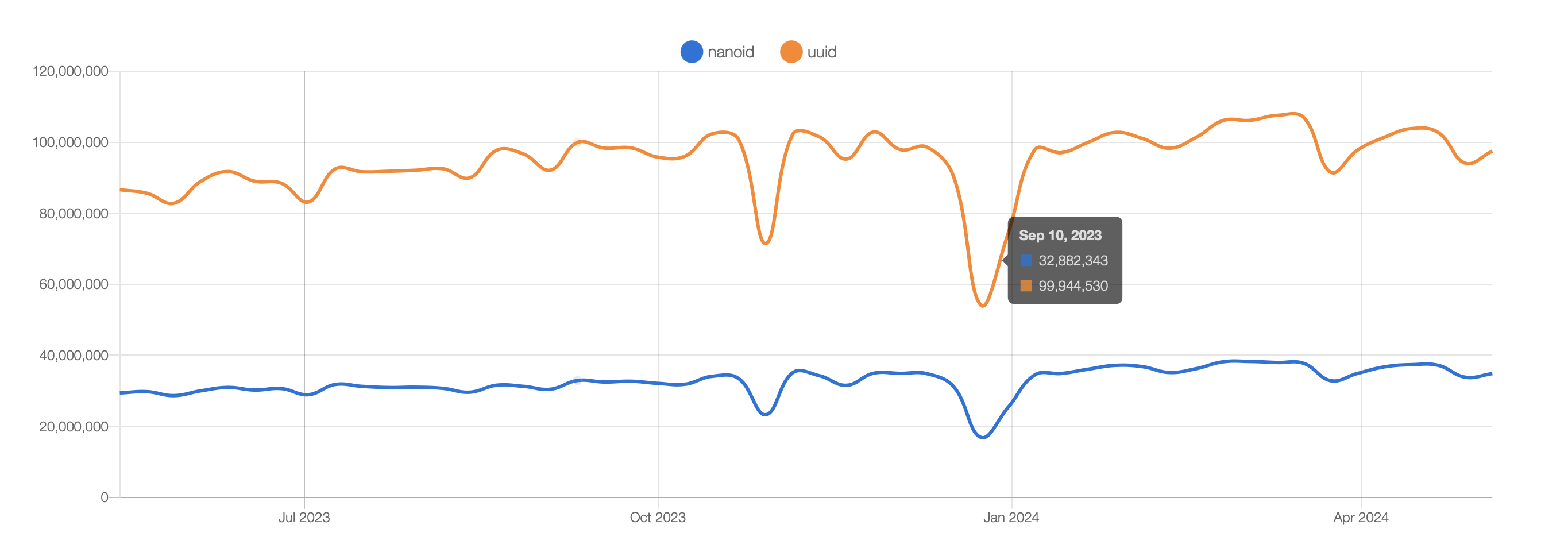
下面的统计数据可以看到Nano ID星星数量(23k)超过了UUID(14k)。

基准测试
$ node ./test/benchmark.js
crypto.randomUUID 25,603,857 ops/sec
@napi-rs/uuid 9,973,819 ops/sec
uid/secure 8,234,798 ops/sec
@lukeed/uuid 7,464,706 ops/sec
nanoid 5,616,592 ops/sec
customAlphabet 3,115,207 ops/sec
uuid v4 1,535,753 ops/sec
secure-random-string 388,226 ops/sec
uid-safe.sync 363,489 ops/sec
cuid 187,343 ops/sec
shortid 45,758 ops/sec
Async:
nanoid/async 96,094 ops/sec
async customAlphabet 97,184 ops/sec
async secure-random-string 92,794 ops/sec
uid-safe 90,684 ops/sec
Non-secure:
uid 67,376,692 ops/sec
nanoid/non-secure 2,849,639 ops/sec
rndm 2,674,806 ops/sec
测试配置: ThinkPad X1 Carbon Gen 9, Fedora 34, Node.js 16.10.
安全性
请看一篇关于随机生成器理论的好文章: Secure random values (in Node.js)
-
不可预测性. 不使用不安全的 Math.random(), Nano ID使用Node.js的crypto模块和浏览器的Web Crypto API。 这些模块使用不可预测的硬件随机生成器。
-
统一性. random % alphabet 是编写ID生成器时常犯的一个错误。 符号的分布是不均匀的; 有些符号出现的几率会比其他符号低。因此, 它将减少刷新时的尝试次数。 Nano ID 使用了一种更好的算法,并进行了一致性测试。

-
有据可查: Nano ID所有的行为都有记录。参考源代码中的注释。
-
漏洞: 报告安全漏洞,请与安全联系人Tidelift security contact协调修复和披露。
PostgreSQL如何支持Nano ID
github上提供了Nano ID的PostgreSQL实现:
先创建pgcrypto扩展
CREATE EXTENSION if not exists pgcrypto;
再创建nanoid函数
CREATE OR REPLACE FUNCTION nanoid(size int DEFAULT 21)
RETURNS text AS $$
DECLARE
id text := '';
i int := 0;
urlAlphabet char(64) := 'ModuleSymbhasOwnPr-0123456789ABCDEFGHNRVfgctiUvz_KqYTJkLxpZXIjQW';
bytes bytea := gen_random_bytes(size);
byte int;
pos int;
BEGIN
WHILE i < size LOOP
byte := get_byte(bytes, i);
pos := (byte & 63) + 1; -- + 1 because substr starts at 1 for some reason
id := id || substr(urlAlphabet, pos, 1);
i = i + 1;
END LOOP;
RETURN id;
END
$$ LANGUAGE PLPGSQL VOLATILE;
使用nanoid函数,我们可以控制想要的长度,比如使用nanoid(2)更快,生成更简单的id:
postgres=# select nanoid(2);
nanoid
--------
sz
(1 row)
默认长度是21:
postgres=# select nanoid();
nanoid
-----------------------
YRlOhP53juqe-r68Faok3
(1 row)
接着我们在PostgreSQL 16.2里对Nano ID和UUID进行简单的插入性能对比测试,表结构如下:
create unlogged table test_uuid (
id uuid default gen_random_uuid() primary key
);
create unlogged table test_nanoid (
id character varying default nanoid() PRIMARY KEY
);
使用本地虚拟机(内存1G,CPU 1核)单条insert批量插入一万条数据。
select 'insert into test_uuid values('||repeat('default),(',99999)||'default);';\gexec
或者
select 'insert into test_nanoid values('||repeat('default),(',99999)||'default);';\gexec
测试结果:UUID花销大约200毫秒,Nano ID花销大约1474毫秒。
这是因为UUID类型在PostgreSQL里可以很好的映射为byte存储,而Nano ID必须存储在text/varchar,并且PostgreSQL从v13开始已在内核层支持UUID生成函数,受这两个因素的影响,目前UUID的性能比Nano ID要好。
不过相比UUID,从上面Nano ID的特性介绍来看,Nano ID有很大的优势,也许在PostgreSQ里很快能看到对Nano ID原生或者插件的支持。
参考文章
https://github.com/ai/nanoid
https://www.npmtrends.com/nanoid-vs-uuid
https://blog.bitsrc.io/why-is-nanoid-replacing-uuid-1b5100e62ed2
https://dev.to/bibekkakati/nanoid-alternative-to-uuid-2kgn
https://www.libhunt.com/compare-nanoid-vs-pg_random_id
https://github.com/Jakeii/nanoid-postgres
保持联系
现组建了一个PG乐知乐享交流群,欢迎关注文章的小伙伴加微信进群吹牛唠嗑,交流技术。