




前言:
数据开发团队经常会遇到一个问题,一份数据要到处共享使用,如果每个业务都到生产系统查询会有以下几个问题:
直接影响生产系统线上稳定性。比如被某个系统一个慢查询拖死。
权限无法控制导致数据泄密。比如个别不怀好意的员工乱爬数据。
无法针对数据做更深度更灵活的分析。比如做机器学习或者大数据统计。
因此需要把数据按需发布到指定的队列里面。具备队列权限的业务组自行同步到对应的数据栈进行处理。
DataStax CDC for Apache Cassandra是DataStax开源的一个CDC工具,它为Apache Pulsar™ 启用更改数据捕获 (CDC) 的表发送变更记录,进而可以将数据同步写入 Elasticsearch,HBase或者其它数据库,并且在捕获过程自动去重了,不会导致重复消费。从而帮助企业把实时数据连接到整个数据生态系统,帮助开发人员创建更智能的应用程序。以下就是 DataStax CDC连接到其它数据系统的一些用例:
搜索,构建可靠、高性能的数据存储和检索
分析统计,为目标用例推动有影响力的交互,启用对数据关键方面的报告和可见性,利用数据发现有关您的业务和客户的新有用信息。
人工智能/机器学习,构建可带来差异化业务价值的实时 ML 模型。
从而获得以下收益:
节省时间 - 构建数据管道以更快地连接您的数据生态系统。
省钱 - 避免构建和维护本土解决方案。
更好的决策 - 更快地将实时数据交到业务利益相关者手中。
更智能的应用程序 - 通过从时间序列变化中训练 ML 模型来丰富应用程序。
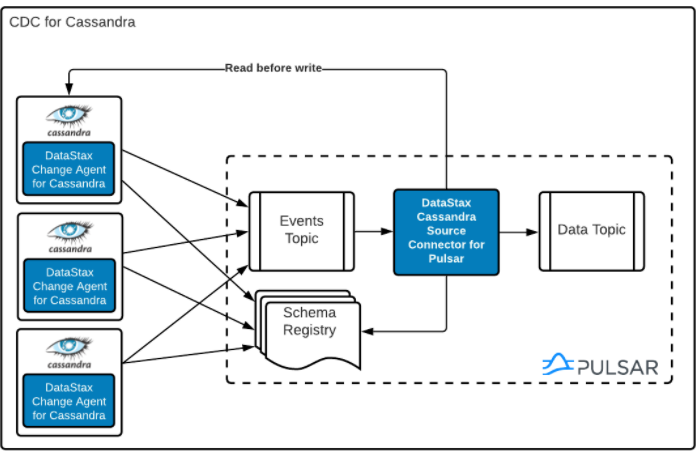
正文:
今天我们用一个简单案例来演示下,这个案例是把写入DSE/Cassandra的数据通过Pulsar source 和 sink 实时同步到Elasticsearch。
假设我们已经部署好DSE,Pulsar,Elasticsearch。现在我们开始步骤。
第一步,为DSE开启CDC,把cdc_enabled 设置为true。
sed -i 's/cdc_enabled: false/cdc_enabled: true/g' dse-6.8.21/resources/cassandra/conf/cassandra.yamlsed -i "s/commitlog_sync_period_in_ms: 10000/commitlog_sync_period_in_ms: 1000/g" dse-6.8.21/resources/cassandra/conf/cassandra.yamlecho "cdc_total_space_in_mb: 5000" >> /dse-6.8.21/resources/cassandra/conf/cassandra.yaml
下载:agent-dse4-luna-1.0.3-all.jar,这个agent运行在每个节点上,会消费变更记录发送到Pulsar。
下载地址:
https://github.com/datastax/cdc-apache-cassandra/releases/download/v1.0.3/agent-dse4-pulsar-1.0.3-all.jar
官方链接:
https://docs.datastax.com/en/cdc-for-cassandra/cdc-apache-cassandra/1.0.2/install.html
下载好之后把agent加入JVM启动项,
export JVM_EXTRA_OPTS="-javaagent:/agent-dse4-luna-1.0.3-all.jar=pulsarServiceUrl=pulsar://pulsar:6650,cdcWorkingDir=/var/lib/cassandra/cdc_raw"//注意cdcWorkingDir 要跟你环境配置的一致
之后启动DSE或Cassandra,启动时候system.log可以看到这个
AgentConfig.java:506 - cdcConcurrentProcessors=-1, errorCommitLogReprocessEnabled=false, pulsarServiceUrl=pulsar://localhost:6650, cdcWorkingDir=/var/lib/cassandra/cdc_raw, cdcPollIntervalMs=60000, sslCipherSuites=null, sslHostnameVerificationEnable=false, pulsarAuthPluginClassName=null, pulsarMaxPendingMessages=1000, pulsarKeyBasedBatcher=false, maxInflightMessagesPerTask=16384, sslTruststorePath=null, sslEnabledProtocols=TLSv1.2,TLSv1.1,TLSv1, sslTruststorePassword=null, sslTruststoreType=JKS, topicPrefix=events-, pulsarMaxPendingMessagesAcrossPartitions=50000, sslProvider=null, sslAllowInsecureConnection=false, sslKeystorePath=null, pulsarBatchDelayInMs=-1, sslKeystorePassword=null, pulsarAuthParams=null
创建表并为其开启CDC:
CREATE TABLE IF NOT EXISTS db1.meteorite (name text,id text PRIMARY KEY,nametype text,recclass text,mass float,fall text,finddate text,geolocation text,) WITH cdc=true; //开启CDC
这样在DSE或者Cassandra端的就安装好了,接下去安装Pulsar Cassandra source 和Pulsar Elasticsearch sink。
我们需要下载 cassandra-source-agents-<version>.tar 下载地址
https://downloads.datastax.com/cdc-apache-cassandra/cassandra-source-agents-1.0.1.tar//采自:https://docs.datastax.com/en/pulsar-connector/1.4/pulsarInstall.html
解压出来 pulsar-cassandra-source-1.0.1.nar 放到随便一个目录。我们现在要把上面创建的db1.meteorite的数据实时同步到Pulsar。创建一个source
bin/pulsar-admin source create \--name cassandra-source-db1-meteorite \--archive pulsar-cassandra-source-1.0.1.nar \--tenant public \--namespace default \--destination-topic-name data-db1.meteorite \--parallelism 1 \--source-config "{\"keyspace\": \"db1\",\"table\": \"meteorite\",\"events.topic\": \"persistent://public/default/events-db1.meteorite\",\"events.subscription.name\": \"meteorite\",\"contactPoints\": \"ip1,u2\",\"loadBalancing.localDc\": \"Cassandra\"}"
创建好Cassandra source后,数据就能从Cassandra发送到Pulsar的Topic,现在我们再创建一个Elasticsearch sink,把数据从Pulsar 写入到Elasticsearch 。
下载pulsar-io-elastic-search-2.9.1.nar ,下载地址
https://www.apache.org/dyn/mirrors/mirrors.cgi?action=download&filename=pulsar/pulsar-2.9.1/connectors/pulsar-io-elastic-search-2.9.1.nar
放到Pulsar 的connectors目录下,这个目录不存在需要手动创建。
mkdir -p connectors
现在可以创建sink了
bin/pulsar-admin sink create \--sink-type elastic_search \--tenant public \--namespace default \--name elasticsearch-sink-db1-meteorite \--inputs persistent://public/default/data-db1.meteorite \--subs-position Earliest \--sink-config "{\"elasticSearchUrl\":\"http://192.168.0.109:9200\",\"indexName\":\"db1.meteorite\",\"keyIgnore\":\"false\",\"nullValueAction\":\"DELETE\",\"schemaEnable\":\"true\"}"
可以通过以下命令看看source 和sink 安装成功没
bin/pulsar-admin source status --name cassandra-source-db1-meteoritebin/pulsar-admin sink status --name elasticsearch-sink-db1-meteorite
接下来我们在ES上面创建一个索引,这样数据就可以实时同步写入到ES了。
curl -XPUT $ELASTICSEARCH_URL/db1.meteorite?include_type_name=true \-H 'Content-Type: application/json' \-d '{"mappings": {"_doc" : {"properties": {"@timestamp": {"type": "alias","path": "finddate"},"fall": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"mass": {"type": "float"},"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"nametype": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"recclass": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"geolocation": {"type": "geo_point"}}}}}'
接下来我们往DSE导入数据
copy meteorite(name,id,nametype,recclass,mass,fall,finddate,geolocation) from '/var/import.csv' with header = true;
我们看看Cassrandra 的Souce状态
bin/pulsar-admin source status --name cassandra-source-db1-meteorite返回:{"numInstances" : 1,"numRunning" : 1,"instances" : [ {"instanceId" : 0,"status" : {"running" : true,"error" : "","numRestarts" : 0,"numReceivedFromSource" : 31962,"numSystemExceptions" : 0,"latestSystemExceptions" : [ ],"numSourceExceptions" : 0,"latestSourceExceptions" : [ ],"numWritten" : 31962,"lastReceivedTime" : 1648268906526,"workerId" : "c-standalone-fw-localhost-8080"}} ]}
再看看sink的状态:
bin/pulsar-admin source sink --name elasticsearch-sink-db1-meteorite返回:{"numInstances" : 1,"numRunning" : 1,"instances" : [ {"instanceId" : 0,"status" : {"running" : true,"error" : "","numRestarts" : 8,"numReadFromPulsar" : 31962,"numSystemExceptions" : 0,"latestSystemExceptions" : [ ],"numSinkExceptions" : 0,"latestSinkExceptions" : [ ],"numWrittenToSink" : 31962,"lastReceivedTime" : 1648269275281,"workerId" : "c-standalone-fw-localhost-8080"}} ]}
可以看到导入的31962条数据已经写入到ES中了,我们再到ES查看下是否已经导入进来:
curl -XGET $ELASTICSEARCH_URL/:9200/db1.meteorite/_count//返回{"count": 31962,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0}}
到此处,大功告成。这个例子有点长,毕竟涉及的技术栈有点多,包括( DSE Cluster, Pulsar Cluster, Grafana, Elasticsearch, and Kibana)。该实例在Github上有,上面是基于Google GKE 部署的。
https://github.com/jamesc127/datastax-enterprise-cdc-demo
有兴趣的童鞋可以fork下来自己跑一遍,或者修改它,比如把数据同步到HBase 、 ClickHouse等,有疑问可以找小编沟通。Pulsar io提供了很多的sink可以去看看。
https://pulsar.apache.org/zh-TW/download/
本期的分享就到这边了
如果你有关于Cassandra/Pulsar相关素材,欢迎投稿,我们将会给你赠送一个小礼物。
想学习更多的Casssandra、Spark、Pulsar相关知识,请扫码关注。

