





TimescaleDB 如何比较?
TimescaleDB 通常与普通的关系数据库(即 PostgreSQL)和 NoSQL 变体(如 InfluxDB 或 MongoDB)进行比较。虽然这些技术,尤其是 NoSQL,已经被整个数据社区所接受,但现代应用程序需要现代数据架构。
看看我们如何与常规 SQL 和 NoSQL 数据库进行比较,尤其是当 PB 级时间序列数据是应用程序成功的关键时!
为什么在关系数据库上使用 TimescaleDB?
与 vanilla PostgreSQL 或其他传统 RDBMS 相比,TimescaleDB 在存储时间序列数据方面提供了三个关键优势:
更高的数据摄取率,尤其是在较大的数据库大小时。
查询性能从相当到更大的数量级不等。
面向时间的功能。
而且因为 TimescaleDB 仍然允许您使用 PostgreSQL 的全部功能和工具——例如,与关系表的 JOIN、通过 PostGIS 的地理空间查询pg_dump以及pg_restore任何使用 PostgreSQL 的连接器——没有理由不使用 TimescaleDB 来存储时间序列PostgreSQL 节点中的数据。
更高的摄取率
对于时间序列数据,TimescaleDB 比 PostgreSQL 实现了更高和更稳定的摄取率。正如我们在架构讨论中所描述的,一旦索引表不再适合内存,PostgreSQL 的性能就会开始受到严重影响。
特别是,每当插入新行时,数据库需要更新表的每个索引列的索引(例如,B 树),这涉及从磁盘交换一个或多个页面。在问题上投入更多内存只会延迟不可避免的问题,一旦您的时间序列表达到数千万行,您每秒 10K-100K+ 行的吞吐量可能会崩溃到每秒数百行。
TimescaleDB 通过大量使用时空分区来解决这个问题,即使在单台机器上运行也是如此。因此,对最近时间间隔的所有写入都仅对保留在内存中的表,因此更新任何二级索引也很快。
基准测试显示了这种方法的明显优势。以下 10 亿行(在单台机器上)的基准模拟了一个常见的监控场景,数据库客户端插入包含时间、设备标签集和多个数字指标(在本例中为 10)的中等大小的数据批次。在这里,实验是在带有网络附加 SSD 存储的标准 Azure VM(DS4 v2,8 核)上进行的。
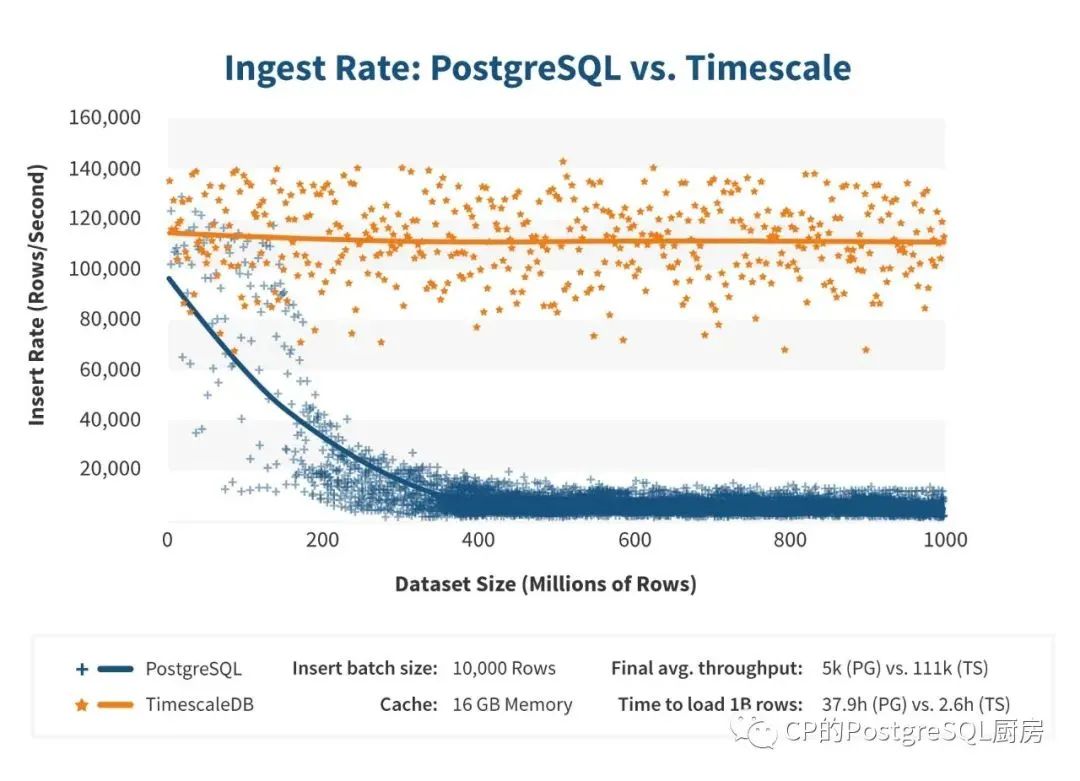
我们观察到 PostgreSQL 和 TimescaleDB 对于前 20M 的请求或每秒超过 1M 的指标以大约相同的吞吐量开始(分别为 106K 和 114K)。然而,在大约 50M 行时,PostgreSQL 的性能开始急剧下降。它在过去 100M 行中的平均值仅为 5K 行/秒,而 TimescaleDB 保持其 111K 行/秒的吞吐量。
简而言之,TimescaleDB 加载 10 亿行数据库 的时间是 PostgreSQL 总时间的十五分之一,并且在这些更大的规模下,吞吐量是 PostgreSQL 的20 倍以上。
我们对 TimescaleDB 的基准测试表明,即使使用单个磁盘,它也能在超过 10B 行时保持稳定的性能。
此外,用户报告称,当在一台机器上利用多个磁盘时,无论是在 RAID 配置中还是使用TimescaleDB支持将单个超表分布到多个磁盘(通过多个表空间,这在传统的 PostgreSQL 表)。
优越或相似的查询性能
在单磁盘机器上,许多仅执行索引查找或表扫描的简单查询在 PostgreSQL 和 TimescaleDB 之间的性能相似。
例如,在具有索引时间、主机名和 cpu 使用信息的 100M 行表上,对于每个数据库,以下查询耗时不到 5ms:
SELECT date_trunc('minute', time) AS minute, max(user_usage) FROM cpu WHERE hostname = 'host_1234' AND time >= '2017-01-01 00:00' AND time < '2017-01-01 01:00' GROUP BY minute ORDER BY minute;复制
涉及对索引进行基本扫描的类似查询在两者之间也具有同等性能:
SELECT * FROM cpu WHERE usage_user > 90.0 AND time >= '2017-01-01' AND time < '2017-01-02';te;复制
涉及基于时间的 GROUP BY 的较大查询(在面向时间的分析中很常见)通常在 TimescaleDB 中实现卓越的性能。
例如,以下涉及 33M 行的查询在 TimescaleDB 中当整个(超)表为 100M 行时快 5 倍,而当它为 1B 行时快约2倍。
SELECT date_trunc('hour', time) as hour, hostname, avg(usage_user) FROM cpu WHERE time >= '2017-01-01' AND time < '2017-01-02' GROUP BY hour, hostname ORDER BY hour;复制
此外,其他可以专门针对时间排序进行推理的查询在 TimescaleDB 中的性能可能更高。
例如,TimescaleDB 引入了基于时间的“合并追加”优化,以最小化必须处理以执行以下操作的组的数量(假设它知道时间已经排序)。对于我们的 100M 行表,这导致查询延迟比 PostgreSQL 快 396 倍(82ms vs. 32566ms)。
SELECT date_trunc('minute', time) AS minute, max(usage_user) FROM cpu WHERE time < '2017-01-01' GROUP BY minute ORDER BY minute DESC LIMIT 5;复制
我们总是发布 PostgreSQL 和 TimescaleDB 之间更完整的基准比较,以及复制我们的基准的软件。
我们的查询基准测试的高级结果是,对于我们尝试过的几乎每个查询,TimescaleDB的性能都与普通 PostgreSQL相似或优越(或大大优越) 。
与 PostgreSQL 相比,TimescaleDB 的一项额外成本是更复杂的规划(假设单个超表可以由许多块组成)。这可以转化为额外几毫秒的计划时间,这可能对非常低延迟的查询(< 10ms)产生不成比例的影响。
面向时间的功能
TimescaleDB 还包括许多传统关系数据库中没有的面向时间的特性。这些包括特殊的查询优化(如上面的合并附加),为面向时间的查询提供了一些巨大的性能改进,以及其他面向时间的功能(其中一些在下面列出)。
面向时间的分析
TimescaleDB 包括用于面向时间的分析的新功能,包括以下一些:
时间分桶:标准功能的更强大版本date_trunc,它允许任意时间间隔(例如,5 分钟、6 小时等),以及灵活的分组和偏移量,而不仅仅是秒、分钟、小时等。
Last和first聚合:这些函数允许您按另一列的顺序获取一列的值。例如,last(temperature, time)根据组内的时间(例如,一个小时)返回最新的温度值。
这些类型的函数可以实现非常自然的面向时间的查询。例如,以下财务查询打印每个资产的开盘价、收盘价、最高价和最低价。
SELECT time_bucket('3 hours', time) AS period asset_code, first(price, time) AS opening, last(price, time) AS closing, max(price) AS high, min(price) AS low FROM prices WHERE time > NOW() - INTERVAL '7 days' GROUP BY period, asset_code ORDER BY period DESC, asset_code;复制
last通过辅助列(甚至不同于聚合)排序的能力支持一些强大的查询类型。例如,财务报告中的一种常用技术是“双时态建模”,它将与观察相关的时间与观察记录的时间分开推理。在这样的模型中,更正作为新行插入(具有更新的time_recorded字段)并且不会替换现有数据。
以下查询返回每个资产的每日价格,按最新记录的价格排序。
SELECT time_bucket('1 day', time) AS day, asset_code, last(price, time_recorded) FROM prices WHERE time > '2017-01-01' GROUP BY day, asset_code ORDER BY day DESC, asset_code;复制
有关 TimescaleDB 当前(和不断增长的)时间功能列表的更多信息,请参阅我们的 API。
面向时间的数据管理
TimescaleDB 还提供了某些数据管理功能,这些功能在 PostgreSQL 中不可用或无法执行。例如,在处理时间序列数据时,数据通常会很快建立起来。因此,您希望按照“仅将原始数据存储一周”的方式编写数据保留策略。
事实上,这与连续聚合的使用相结合是很常见的,因此您可能会保留两个超表:一个包含原始数据,另一个包含已经汇总到每分钟或每小时聚合中的数据。然后,您可能希望在两个(超)表上定义不同的保留策略,从而将聚合数据存储更长时间。
TimescaleDB 允许通过其功能在块级别而不是行级别有效删除旧数据。drop_chunks
SELECT drop_chunks('conditions', INTERVAL '7 days');复制
这会从超表“条件”中删除仅包含超过此持续时间的数据的所有块(文件),而不是删除块中的任何单个数据行。这避免了底层数据库文件中的碎片,从而避免了在非常大的表中可能非常昂贵的清理的需要。
为什么使用 TimescaleDB 而不是 NoSQL?
与一般的 NoSQL 数据库(例如 MongoDB、Cassandra)甚至更专业的面向时间的数据库(例如 InfluxDB、KairosDB)相比,TimescaleDB 提供了定性和定量的差异:
普通 SQL:TimescaleDB 为您提供对时间序列数据的标准 SQL 查询的能力,即使是在规模上也是如此。大多数(全部?)NoSQL 数据库需要学习一种新的查询语言或使用充其量是“SQL-ish”的东西(这仍然会破坏与现有工具的兼容性)。
操作简单:使用 TimescaleDB,您只需为关系和时间序列数据管理一个数据库。否则,用户通常需要将数据存储到两个数据库中:一个“普通”关系数据库,另一个是时间序列数据库。
可以跨关系和时间序列数据执行JOIN 。
对于一组不同的查询,查询性能更快。更复杂的查询通常是对 NoSQL 数据库的慢速或全表扫描,而有些数据库甚至无法支持许多自然查询。
像 PostgreSQL 一样管理并继承其对各种数据类型和索引(B-tree、hash、range、BRIN、GiST、GIN)的支持。
对地理空间数据的原生支持:存储在 TimescaleDB 中的数据可以利用 PostGIS 的几何数据类型、索引和查询。
第三方工具:TimescaleDB 支持任何使用 SQL 的工具,包括 Tableau 等 BBI 工具。





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序
中国PostgreSQL分会入选工信部重点领域人才能力评价机构

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓



