




「尺有所短,寸有所长;不忘初心,方得始终。」
一、微服务的演进策略
「由单体应用到微服务应用的演进过程中,服务的拆分是微服务建设的基础,一般基于不同的业务进行拆分。但是业务往往与数据有较大耦合性,所以进行业务拆分接需要将【业务和数据】两大维度结合起来对服务拆分。」
业务体现在各种功能代码中,通过确定业务的边界,使用领域模型与界限上下文、领域事件等技术手段实现拆分。
数据的拆分则体现在如何将集中式的中心化数据转变为各个微服务各自拥有的独立数据。
「业务和数据两个维度的拆分没有先后,但是因为在数据库中,可能存在各种跨表连接查询、跨库连接查询以及不同业务模块的代码与数据耦合的场景,所以导致数据层面拆分服务变的非常的困难。因此更多的是数据库先行。数据模型能否彻底分开,很大程度上决定了微服务的边界功能是否彻底划清。」
总结:服务拆分有【业务和数据】两大维度,「实现的方法根据系统自身的特点和运行状态,分为绞杀者与修缮者两种模式。」
1.1 绞杀者策略(Strangler Pattern)
绞杀者模式由Martin Fowler提出,「指在原有系统外围将【新功能】用【新的方式】构建为【新的服务】,逐步剥离原有系统的业务能力,用微服务逐步替代原有系统的策略」。不修直接改原有系统,两者通过服务或异步化的数据进行业务关联,逐步实现对老系统替换。
「应用场景」
绞杀者策略,随着时间的推移,新的服务就会逐渐【绞杀】老的系统。「对于规模很大而又难以对现有架构进行修改的原有系统」,推荐采用绞杀者模式。
之前做的一个系统重构就是使用的绞杀者模式推进整个重构的进程。
「绞杀者模式演进示意图」
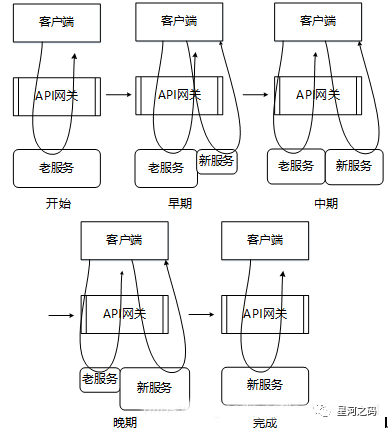
通过示意图,可以看到随着功能演进和时间的推移,老的遗留系统功能逐步被微服务所替代,最终完成从量变到质变,完全下线旧服务。
「绞杀者模式实施原则」
「任何新功能都要在完整微服务架构中开发」,分为两种:
「完全独立的新功能」:独立在新服务中开发。 「原始业务变更」:对于涉及到原始业务变更,需要我们通过【「在新服务中对整体业务进行重构」】来实现。
1.2 修缮者模式(Repairer Pattern)
在现有系统的基础上,剥离影响整体业务的部分功能对其进行单独重构,独立为微服务。「是一种维持原有系统整体能力不变,通过优化局部以提升系统整体能力的策略。」
「应用场景」
修缮者模式更多的是体现在重构技术上,在重构的同时保障原有功能的正常,新功能的逐步迭代。
「修缮者模式演进示意图」
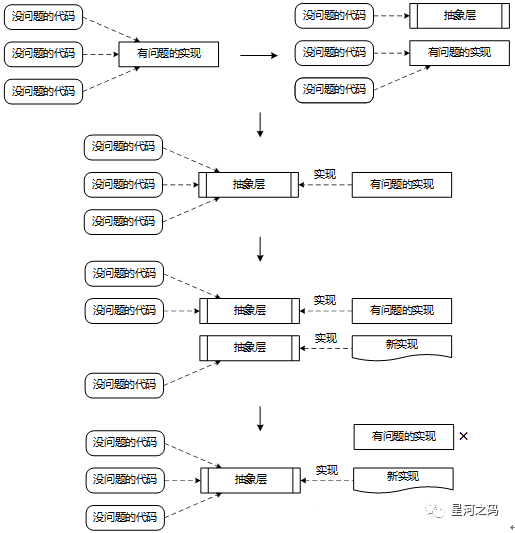
通过示意图,可以将修缮者模式的实现分为三个过程:
「抽象层提取」
增加依赖抽象层,识别原有功能,对其进行改造,实现该抽象层。
「抽象层实现」
采用微服务方式为抽象层提供新的实现。
「抽象层替换」
「通过抽象层使用新的实现对原有实现进行逐步替换」,从而完成新老实现方式之间的替换。
1.3 另起炉灶模式
这个方式就简单粗暴,「将原有的系统推到重做,也就是系统重构,建设微服务。」 在此期间,原有单体系统照常运行,一般会停止接受和开发新需求。而新系统则按照原有系统的功能域,重构领域模型,开发新的微服务,完成数据迁移,新旧系统切换。
在此期间,原有单体系统照常运行,一般会停止接受和开发新需求。而新系统则按照原有系统的功能域,重构领域模型,开发新的微服务,完成数据迁移,新旧系统切换。
二、不同场景下的微服务建设策略
微服务建设策略一般分为新建系统、单体遗留系统两种方式,需要我们按照实际情况进行取舍。
2.1 新建系统
新建微服务系统需要根据实际业务的大小划分:简单领域建模,复杂领域建模
「简单领域建模」
「当前问题域就是一个子域,通过事件风暴进行业务场景分析,建立领域模型,完成微服务设计。」
「复杂领域建模」
当前问题域是个复杂的领域时,需要对其进行拆分成各个子域。通过子域建立领域模型,完成微服务的设计和拆分
2.2 单体遗留系统
无论是系统重构,还是新系统的建设,如果涉及到原始遗留系统,我们就要考虑在迁移过程中新旧系统的平缓过渡、数据迁移等诸多问题,总的来说分为应用与数据两部分
「应用」
应用有分为「保留」原有单体应用和「不保留」原有单体应用两个方向
「当业务领域小」,不必分解子域时,可直接采用事件风暴构建领域模型。 「当业务领域大」,将业务领域进行子域分解。通过事件风暴完成领域建,使用绞杀者策略完成新旧系统的迁移 「保留」原有单体应用,使用修缮者策略将部分特定功能独立为子域 「不保留」原有单体应用 「数据」
当我们建设新系统的时候,不可避免的需要考虑数据的迁移问题,而数据迁移就需要考虑新旧系统「数据模型的兼容性」,往往这是很难达到统一的,因此可以借鉴CQRS的设计思想, 不做数据迁移
新服务只负责业务逻辑处理和业务数据变更,存储自身产生的业务数据。 基于CQRS的读写分离思想建立CQRS查询库,存储查询全量业务数据,并基于查询库构建「查询微服务」。 新服务完成业务逻辑处理后,先写本地数据库,然后通过领域事件驱动机制将数据复制到CQRS查询库。
三、微服务设计原则
3.1 AKF拆分原则
在《架构即未来》书中有介绍的「可扩展架构的方法论【AKF扩展立方体(Scalability Cube)】,它是一种可扩展模型,每个轴线描述扩展性的一个维度。」
「X轴」
「水平复制」:代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上
「Y轴」
「数据分区」:关注应用中职责的划分,比如数据类型,交易执行类型的划分
「Z轴」
「业务拆分」:关注服务和数据的优先级划分,如分地域划分。
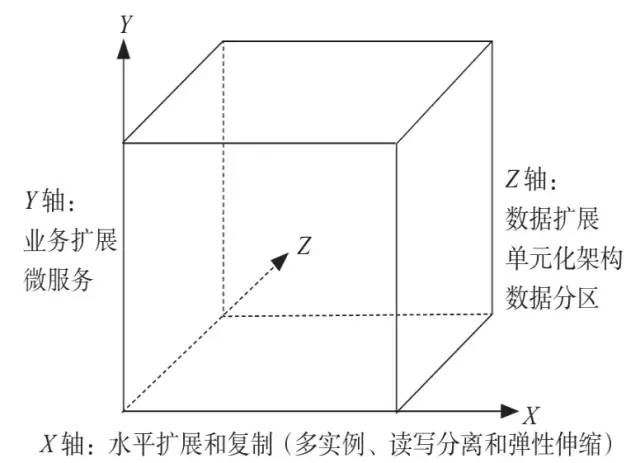
「理论上按照XYZ三个扩展维度,可以将一个单体系统进行无限扩展。」
3.2 前后端分离原则
前后端分离并不陌生,「前端和后端的代码在技术上和物理上的分离」,分别单独开发、运维、部署。使得前后端交互界面更加清晰,容易维护。后端服务采用统一的数据和模型支撑多个前端客户端。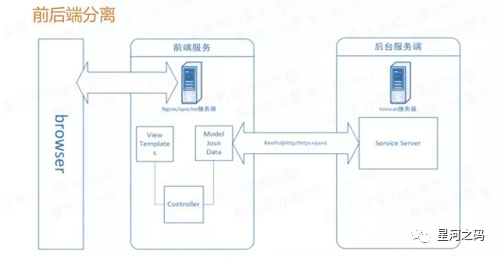
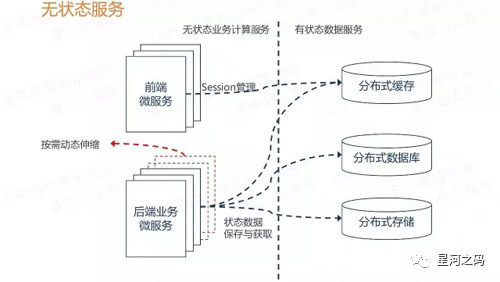
3.3 无状态服务原则
「状态」
当某个数据需要被多个服务共享,以此完成一个操作,则这个数据称为状态。而「依赖这个状态数据的服务被称为有状态服务,反之称为无状态服务。」
「无状态服务原则」
「把有状态的业务服务改变为无状态的计算类服务,则状态数据也就迁移到对应的有状态数据服务中。」
通俗的讲就是将有状态的数据集中缓存
例如:我们在本地内存中建立的数据缓存、Session缓存,而在微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。以此达到动态伸缩,在运行时动态增删节点的目的,不需要考虑缓存数据如何同步的问题。
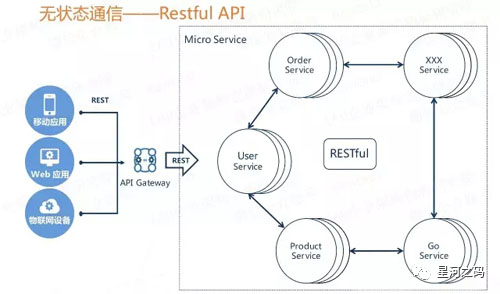
3.4 无状态通信原则
「每次通信都是独立的,不存在共用的数据(状态),不相互依赖某一数据。」
无状态通信的最佳实践就是「RESTful通信风格」,RESTful具有如下优势:
天生适合无状态的HTTP协议,具有很强的扩展能力(HTTPS)。
JSON报文序列化,轻量简单,人机均可读,学习成本低,对搜索引擎友好。
RESTful具有语言无关性,各大热门语言都有成熟的API框架。
四、分布式架构的关键设计
「选择什么样的分布式数据库」
分布式数据库的选择一般分为三类:
原生分布式数据库方案,支持数据多副本,高可用,多采用Paxos协议。
集中式数据库+数据库中间件方案 如MyCat+ MySQL
集中式数据库+分库类库方案,分库类库是一个jar 包,与应用软件部署在一起。如ShardingSphere.
「如何设计数据库分库主键」
「数据库的数据同步和复制」
一般采用数据库日志捕获技术(CDC)
「跨库关联查询如何处理」
「如何处理高频热点数据」
加载到Redis ,ES等搜素引擎
「数据中台与企业级数据集成」
第一:按照统一数据标准,完成不同微服务和渠道业务数据的汇集和存储,解决数据孤岛和初级数据共享的问题。
第二:建立主题数据模型,按照不同主题和场景对数据进行加工处理,建立面向不同主题的数据视图。
第三:建立业务需求驱动的数据体系,支持业务和商业模式创新。
「BFF与企业级业务编排和协同」
BFF的主要职责是处理微服务之间的服务组合和编排,将可复用的服务往下沉淀。避免跨中心的服务调用。

「分布式事务」
分布式事务或者事件驱动机制实现
「多中心多活设计」
【选择合适的分布式数据库】
多数据中心部署,满足数据多副本以及数据底层复制和同步的要求。
【单元化架构设计】
将业务单元集合部署的基本单位,所有业务流程都可在本单元集合内完成。任何单元故障不影响其他同类单元的正常运行,尽量避免跨数据中心和跨单元的调用。
【访问路由】
授权认证业务单元
【全局配置数据管理】。
统一管理各数据中心全局配置数据,所有数据中心全局配置数据可实现实时同步。保证所有数据中心配置数据一致性,可以一键切换。
