首先申明,我反对不同主机之间的DBLink直接关联。因为中间有网络层,这样关联效果较差。遇到这种场景和需求我通常会有如下几个方案:
1、迁移到一起。
2、物化视图。(需要通过DBLink)但是在本地落地。
3、OGG同步过来。
如果在同一主机上呢?这个比较特殊了,就比如说PDB之间。因为一个CDB上的多个PDB没有跨网络。那么这个毕竟不是本地表,这两个差多少?
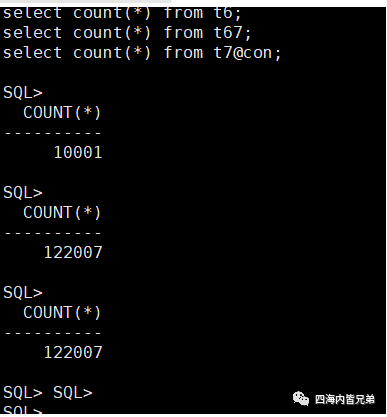
今天实验一下。在一个PDB上建立两个表t6和t67.在另外一个PDB上建立t7连接名是con。
t6 1w条数据
t67和远程的t7表都是12w的数据。
每个表的ID都有索引。
set autotrace on 打开跟踪,执行下面的比较。
首先看本地表关联
select * from t6 a,t67 b where a.id=b.id and a.id<101;
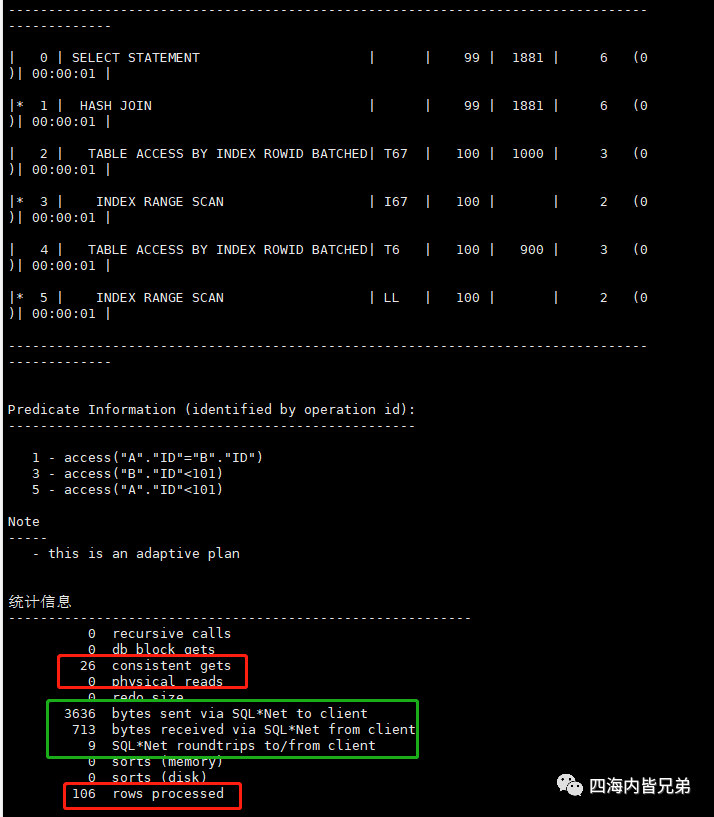
26个一致性读(在内存)
106行
网络返回有一些数据为绿色框。
下面来看跨主机的dblink
select * from t6 c,t7@con d where c.id=d.id and c.id<101;
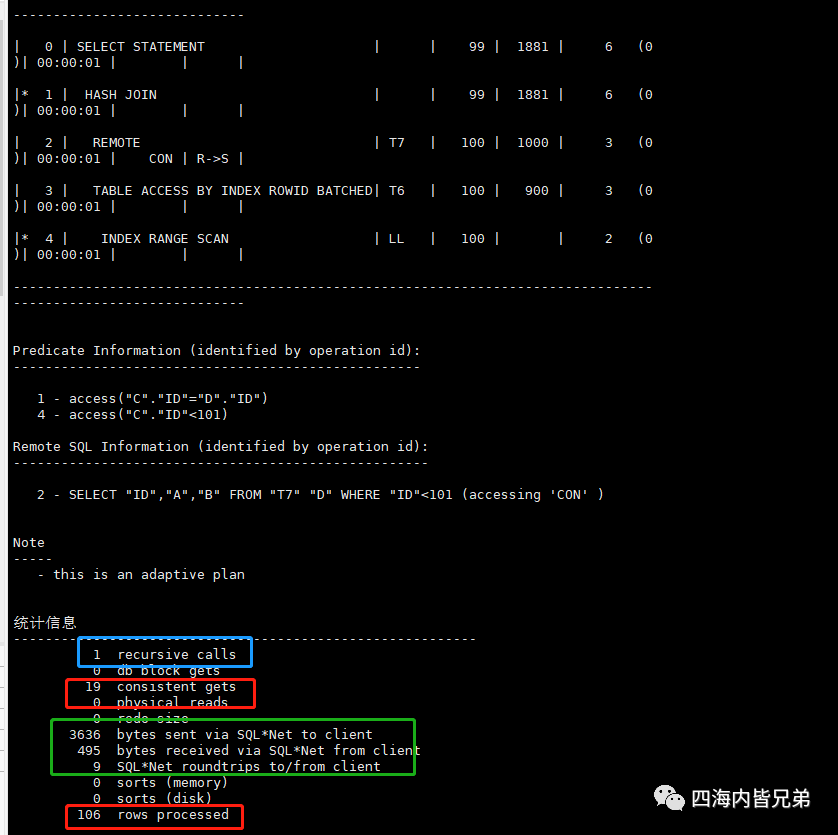
看到行数一样。一致性读少了(在内存)。但是多了一个递归调用。这就是DBLink产生的。可见没有什么明显的改变。
那么如果连接多个PDB呢?
再找了一个PDB,建立一个w表, 连接名是con2
select * from t6 c,t7@con d,w@con2 e where c.id=d.id and c.id=e.id and c.id<101;
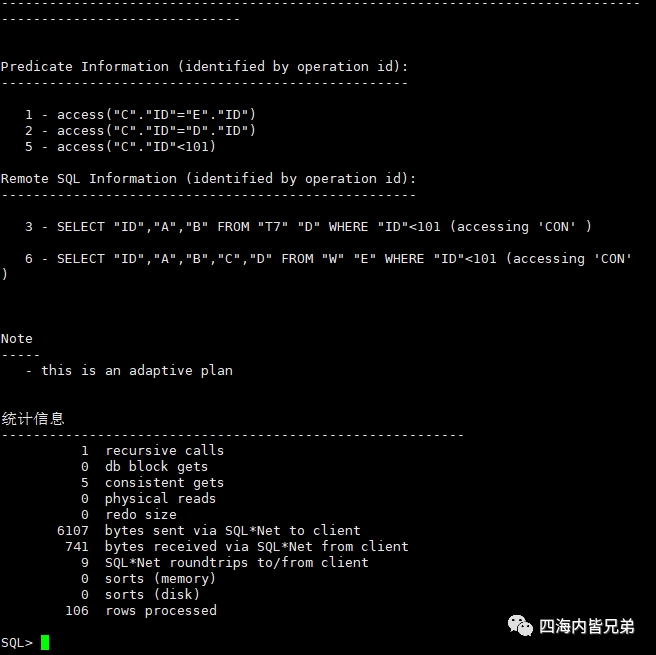
发现一致性读又少了,递归调用还是一个。这里和我最初想的不一样。我开始人为会有两个。
所以最后结论。PDB直接的dblink和本地几乎没有差别。(我不敢说一模一样),但是就这些数据来说,如果SQL写的好,那都一样好,如果SQL写的差,那就一样的差。