




点击上方蓝字关注我们吧
01
数据库硬件
一、业务评估
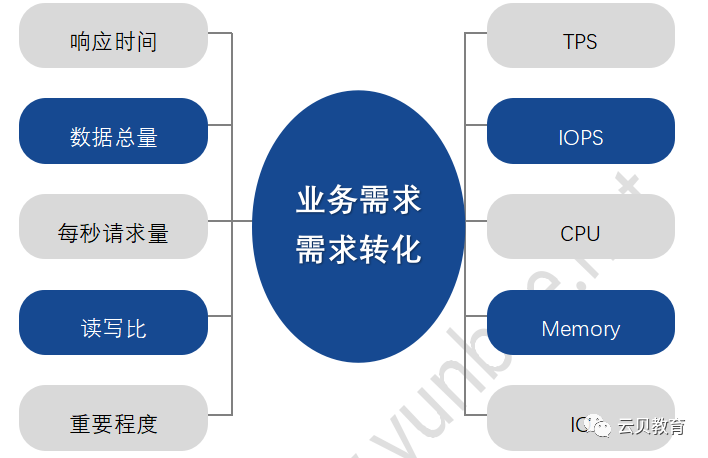
需求 | 指标 |
响应时间 | 查询和写请求ms级返回。 |
数据总量 | 1年内数据量大约2T数据量。 |
每秒请求量 | 每秒有1.2w次请求。 |
读写比 | 读写比是3:1。 |
重要程度 | 核心系统,P1级故障。 |
其他说明 | 数据具有时效性,历史数据访问较少,。数据记录总体长度大约为1KB。 |
二、机型测试
性能对比测试
稳定性测试
掉电保护测试
内存异常测试
IO设备坏盘和rebuild测试
三、成本评估
设备成本
运维成本
功耗成本
四、CPU
Q:选择 核心数量?or 主频?
A:top命令
如果每个CPU运行的进程数量较少。主频
如果每个CPU都很繁忙,且伴随着多进程并发运行。核心数
PostgreSQL 9.6开始支持并行查询。
五、内存
1、操作的数据量,小于系统的RAM大小。加大内存也不会提升性能。
2、OLAP类型系统,数据量级远大于RAM。高速硬盘。
3、频繁访问的数据相对于内存较大时,可以加大内存提升性能。
六、磁盘
1.1 磁盘1 - 类型
串行口
并行口
SATA
SCSI
SAS
SSD
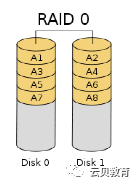
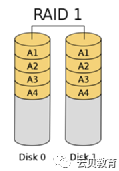
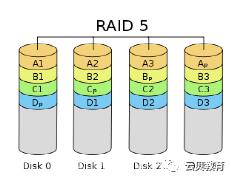
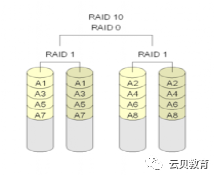
1.2 磁盘2 - RAID
1.3 磁盘3 – 机械硬盘、固态硬盘
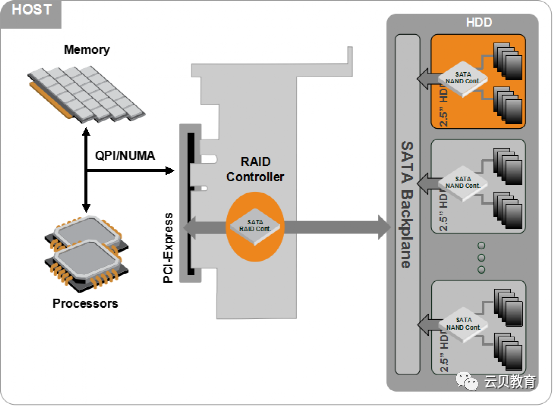
1.4 磁盘4 – 机械硬盘、固态硬盘
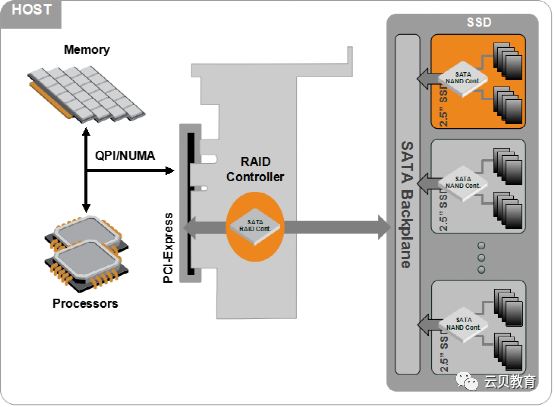
1.5 磁盘5 – 机械硬盘、固态硬盘
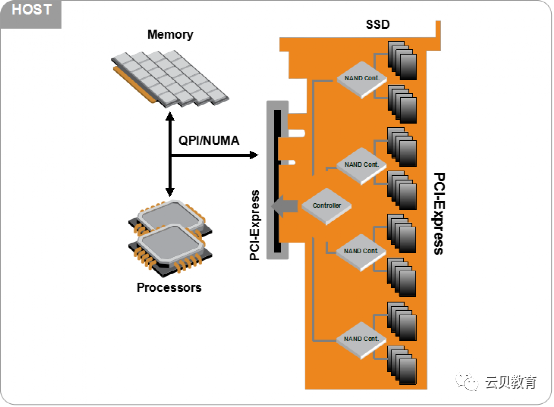
1.6 磁盘6 –固态硬盘(NVMe协议接口)

1.7 存储设备
02
硬件基准测试
一、概述
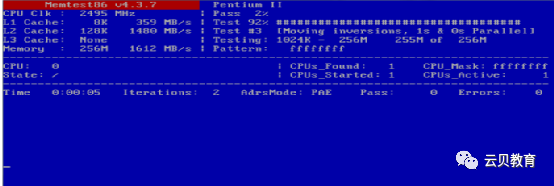
二、Memtest86+
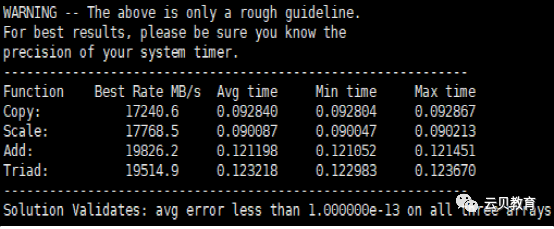
三、STREAM
四、CPU基准测评
pgbench
\timing
generate_seried
五、内存及处理器速度慢的问题!
1.内存插错位置、单通道、双通道问题。
2.内存寻址时序问题。
3.内存不能有效地与CPU的时钟频率相匹配。
六、IOPS
七、提交率
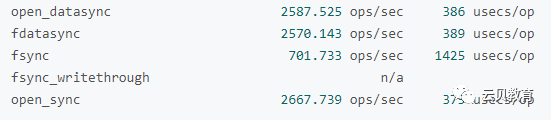
八、硬盘基准测试工具
HD Tune Windows
Linux
sysbench
pgbench
iozone:是一个文件系统的benchmark工具,可以测试不同的操作系统
中文件系统的读写性能。
fio:是一个 I/O 工具用来对硬件进行压力测试和验证。
九、磁盘性能预期值
机械硬盘举例~
顺序传输速率,50MBps-100MBps
RAID类型
RAID 0
RAID 1
RAID 10
RAID 5
十、磁盘和阵列速度慢的原因
磁盘性能低下时,多数都是读取数据慢。
十一、小结
03
硬盘设置
一、概述
二、文件系统最大值
三、文件系统的崩溃恢复
使用man fsck中找到这段解释:check and repair a Linux file system。
从这里可以知道,fsck工具不仅可以做文件系统的检查(扫描),还能修复文件系统,当然fsck所能修复的问题也是有限的,但又不失为一个便捷的自带修复工具。fsck的使用权限必须是root权限。
四、日志文件系统
五、Linux文件系统
Ext2
Ext3 增加日志
Ext4 提升fsync操作
Xfs 顺序写、随机写性能较好。
JFS 性能接近XFS,稳定性?
ReiserFS
Btrfs Oralce 赞住的文件系统,目前还没有稳定版本。
六、solaris 10 UFS文件系统
七、ZFS文件系统
八、FAT32
九、NTFS
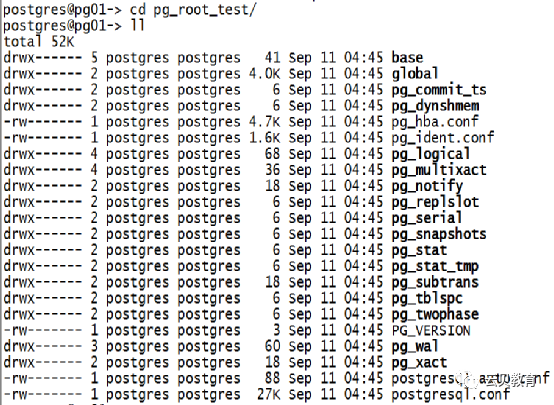
十、PostgreSQL磁盘布局
pg_wal
-X, --waldir=WALDIR location for the write-ahead log directory
--wal-segsize=SIZE size of WAL segments, in megabytes
软连接 ln –sf 源 目标
表空间

/home/postgres/tbltest/PG_12_201909212

十一、PostgreSQL磁盘布局
PG_VERSION | 主版本号 |
pg_hba.conf | 客户端认证 |
pg_ident.conf | 用户名映射 |
postgresql.conf | 配置参数 |
postgresql.auto.conf | alter system修改的配置参数 |
postmaster.opts | 上次启动的命令行选项 |
base/ | 每个数据库对应的子目录都存储在此 |
global/ | 包含pg_database及pg_control等公共文件视图 |
pg_commit_ts/ | 事物提交时间戳数据 |
pg_clog/ (Version 9.6-) | 事物提交状态数据 |
pg_dynshmem/ | 动态共享内存子系统中使用的文件 |
pg_logical/ | 逻辑解码状态数据 |
pg_multixact/ | 多事物状态数据 |
pg_notify/ | LISTEN/NOTIFY状态数据 |
pg_repslot/ | 复制槽数据 |
pg_serial/ | 已提交的可串行化事物相关信息 |
pg_snapshots/ | Pg_export_snapshot在此子目录中创建的快照信息文件 |
pg_stat/ | 统计子系统的永久文件 |
pg_stat_tmp/ | 统计子系统的临时文件 |
pg_subtrans/ | 子事物状态数据 |
pg_tblspc/ | 表空间的软连接 |
pg_twophase/ | 两阶段事物的状态文件 |
pg_wal/ (Version 10 or later) | 事务日志文件预写日志 |
pg_xact/ (Version 10 or later) | 事物提交状态数据 |
pg_xlog/ (Version 9.6-) | 9.6版本之前的的事物日志叫法 |
十二、PostgreSQL磁盘布局
位置 | 磁盘个数 | RAID级别 | 用途 |
/ | 2 | 1 | 操作系统 |
$PGDATA | 6+ | 10 | 数据库 |
Pg_wal | 2 | 1 | WAL |
Tablespace | 1+ | 无 | 临时文件 |
位置 | 磁盘个数 | RAID级别 | 用途 |
/ | 12 | 10 | 操作系统、数据库、WAL |
位置 | 磁盘个数 | RAID级别 | 用途 |
固态硬盘 |
04
数据库缓存
一、PG配置文件中的内存单位
$PGDATA/postgresql.confshared_buffers = 128MB # min 128kBshow shared_buffers;select name,setting,unit,current_setting(name) from pg_settings;
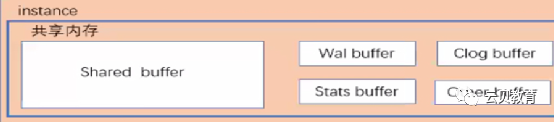
二、OS中的共享内存参数
2.1 增加共享内存参数以增大共享内存块
#!/bin/bash# simple shmsetup scriptPage_size = `getconf PAGE_SIZE`Phys_pages = `getconf _PHYS_PAGES`shmall=`expr $phys_pages 2`Shmmax = `expr $shmall \* $page_size`Echo kernel.shmmax = $shmmaxEcho kernel.shmall = $shmall
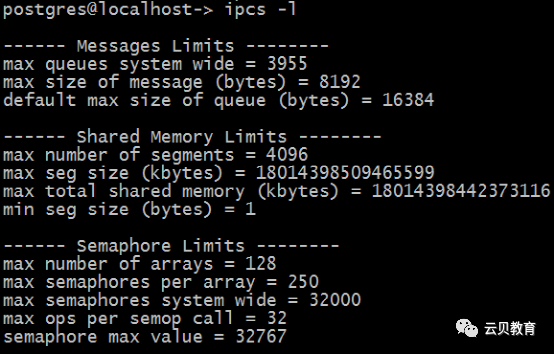
[root@localhost ~]# sysctl kernel.semkernel.sem = 250 32000 32 128
max_connections# min( 2G, (1/4 主机内存)/autovacuum_max_workers ) maintenance_work_mem = 2GB # min 1MB# CPU核多,并且IO好的情况下,可多点,但是注意最多可能消耗这么多内存:# autovacuum_max_workers * autovacuum mem(autovacuum_work_mem),# 会消耗较多内存,所以内存也要有基础。# 当DELETE\UPDATE非常频繁时,建议设置多一点,防止膨胀严重 autovacuum_max_workers = 6 # max number of autovacuum subprocesses # (change requires restart)# 建议 min( 512MB, shared_buffers/32 ) wal_buffers = -1# 1/4 主机内存 shared_buffers = 24GB # min 128kB # (change requires restart)
2.4 数据库缓存检查
pg_buffercache模块提供了一种实时检测共享缓冲区的方法。
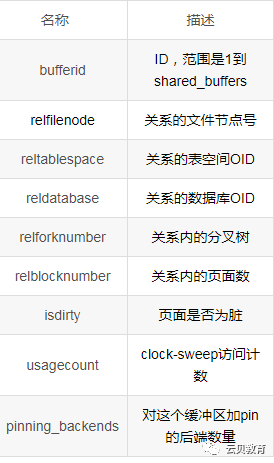
2.5 Pg_buffercache

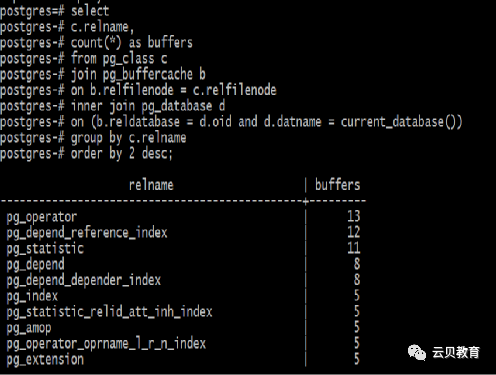
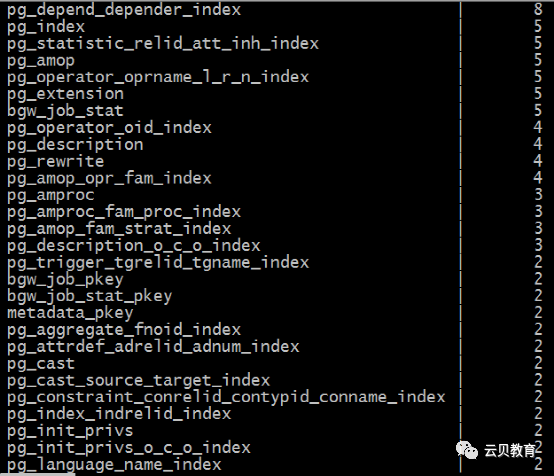
2.6 数据库磁盘布局
postgres=# show data_directory;data_directory----------------opt/pg_root(1 row)
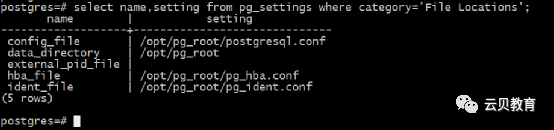
2.7 创建新的Block


Usagecount = 1 这意味着一个数据库进程已经访问了该块.
2.8 写脏块到磁盘
1. 检查点
2. bgwrite
2.9 检查点处理基础
1. 将事务提交的修改写进disk(写脏数据);保证数据库的完整性和一致性。
2. 缩短恢复时间,将脏页写入相应的数据文件,确保修改后的文件通过fsync()写入到磁盘。
2.10 WAL与恢复处理
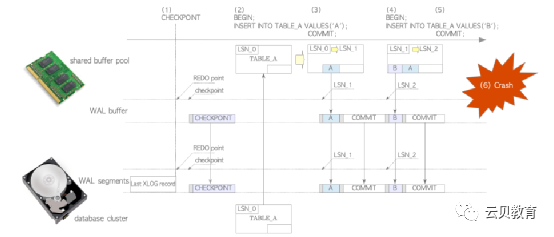
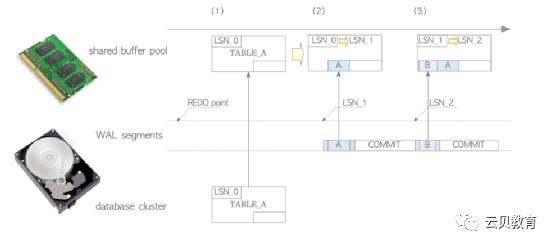
2.11 检查点的触发条件
2.12 数据库块的生命周期
1.查询数据库缓冲区。
2.判断是否有对应的数据页面。
3.没有,物理读,在缓冲区中构建物理数据页面。
4.读取或者修改数据块。
5.等待检查点/bgwrite刷新脏快。
2.13 双重缓存数据
OS缓存一份
DB缓存一份
2.14 检查点开销
2.15 起始大小指导
# 25% 主机内存
shared_buffers = xxGB # min 128kB # (change requires restart)
投稿平台
http://www.tdpub.cn/ 欢迎各位同学在TDPUB发表文章~

