




分析类查询即便是TPC-H中的简单分析查询,PostgreSQL的性能都要远远优于MySQL。 昆仑数据库继承并扩展了PostgreSQL在分析类SQL查询处理方面的强大能力,可以支持TPC-H和TPC-DS的所有查询。同时,一个昆仑数据库集群可以管理的数据规模远远大于 一个PostgreSQL 实例。
一、测试环境
服务器配置: PostgreSQL和MySQL分别部署在一台:亚马逊m5.4xlarge(CPU 8cores 16 Threads,内存 64G,存储gp3, 通用型SSD卷 3000IOPS ,125 MB/s 吞吐量)上。
软件版本:
PostgreSQL:PostgreSQL 12.7 on x86_64-koji-linux-gn
MySQL: percona 8.0.26-16
数据库参数配置:
PostgreSQL:shared_buffers 8192MB
MySQL: innodb_buffer_pool_size 8192MB
**测试背景:**PostgreSQL和MySQL采用默认的安装配置,只调整了内存参数, 整个测试过程PostgreSQL没有任何优化行为。
二、测试数据
表的信息:
1张事实表:lineorder
4张维度表:customer,part,supplier,dates
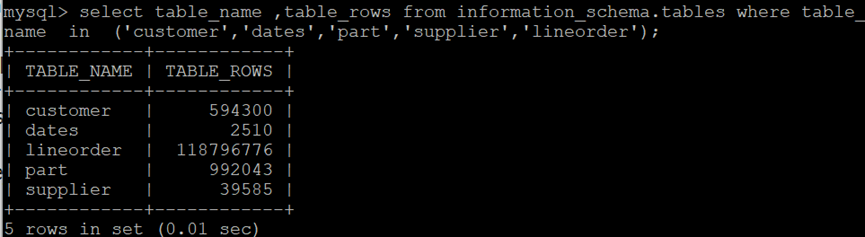
表占用操作系统存储空间:19G
数据查询:11条标准SQL查询测试语句(统计查询、多表关联、sum、复杂条件、group by、order by等组合方式)。
具体SQL语句:附录1 TPC-H测试SQL。
三、测试结果
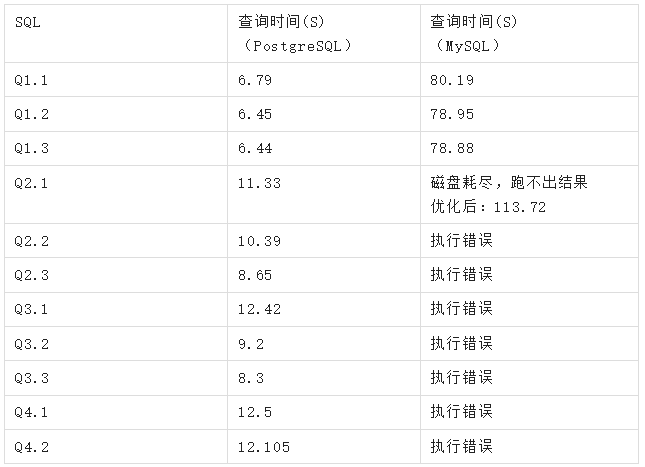
MySQL错误信息: ERROR 3 (HY000): Error writing file ‘/kunlun2/data10/6010/tmp/MYfd=332’(OS errno 28-No space left on device)
分析及总结: 通过对比同一SQL语句在PostgreSQL和MySQL执行计划,会发现MySQL的执行计划没有采用最优的join次序及并行操作,导致性能差。
譬如Q2.1 MySQL执行计划:
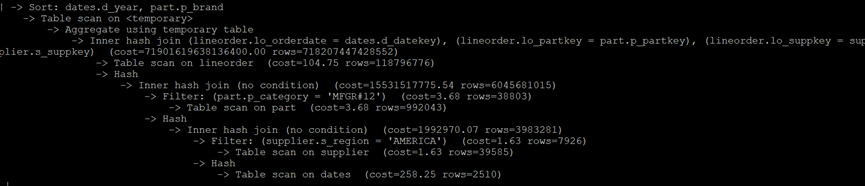
执行计划分析: 上述执行计划首先将几个维度表做join(dates和supplier和part),得到的结果再与事实表lineorder join,因而得出了一个超级大的中间结果集,数据量达到10的15次方的数量(查询计划第五行返回的 rows),最终导致临时文件耗尽磁盘空间而未能完成查询。
优化方案: 通过在SQL语句中强制指定表join次序:首先与part表join得到一个最小的数据子集,然后再与supplier和dates join,逐步缩小范围,查询语句及查询计划的效果如下:
explain format=tree selectsum(lo_revenue) as lo_revenue, d_year as year, p_brand from ((lineorderstraight_join part on lo_partkey = p_partkey) straight_join supplier on lo_suppkey = s_suppkey) straight_join dates ON lo_orderdate = d_datekey where p_category ='MFGR#12' and s_region = 'AMERICA' group by year, p_brand order by year,p_brand;
在MySQL上指定join次序,
同时开启动并行查询:set local innodb_parallel_read_threads=16
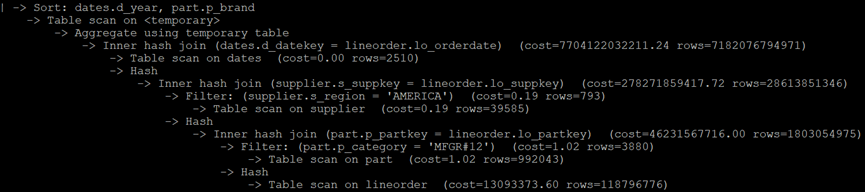
执行时间:1 min 53.72 sec
而PostgreSQL的执行计划:
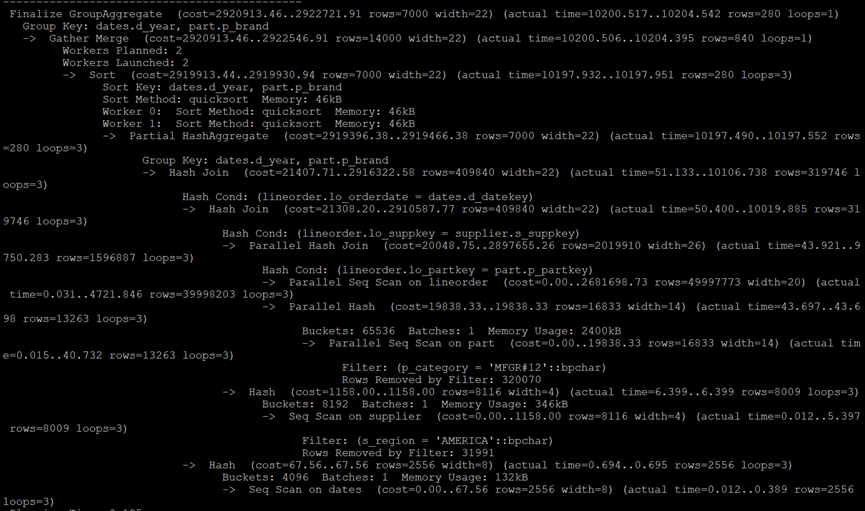
执行时间:1133ms
PostgreSQL自动采用最优的join次序,大大减少了最后排序的数据量,并且启动了3个并行分割数据集,因此执行的性能比手动优化后的MySQL还快10倍。
结论: MySQL执行TPC-H的测试,需要手动优化查询语句,即使如此,性能任然远远低于PostgreSQL,而PostgreSQL默认的配置就可以达到相对好的性能。
四、附录:测试SQL及查询计划
Q1.1
select sum(lo_revenue) as revenue from lineorder
join dates on lo_orderdate = d_datekey
where d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25;
PostgreSQL执行计划:
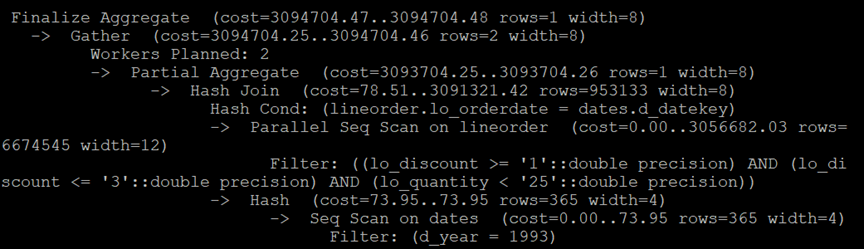
MySQL执行计划:

Q1.2
select sum(lo_revenue) as revenue from lineorder
join dates on lo_orderdate = d_datekey
where d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35;
PostgreSQL执行计划:

MySQL执行计划:

Q1.3
select sum(lo_revenue) as revenue from lineorder
join dates on lo_orderdate = d_datekey
where d_weeknuminyear = 6 and year(d_datekey) = 1994
and lo_discount between 5 and 7
and lo_quantity between 26 and 35;
PostgreSQL执行计划:

MySQL执行计划:

Q2.1
select sum(lo_revenue) as lo_revenue, d_year as year, p_brand
from lineorder
join dates on lo_orderdate = d_datekey
join part on lo_partkey = p_partkey
join supplier on lo_suppkey = s_suppkey
where p_category = 'MFGR#12' and s_region = 'AMERICA'
group by year, p_brand
order by year, p_brand;
PostgreSQL执行计划:
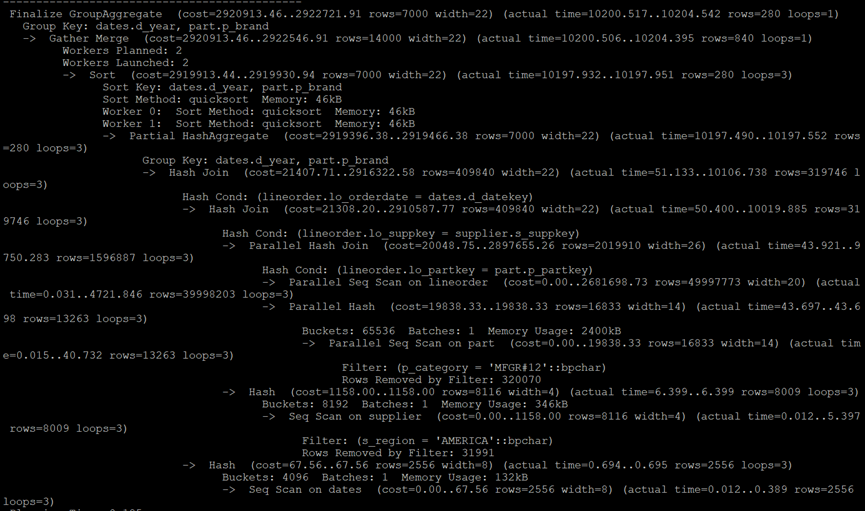
MySQL执行计划:
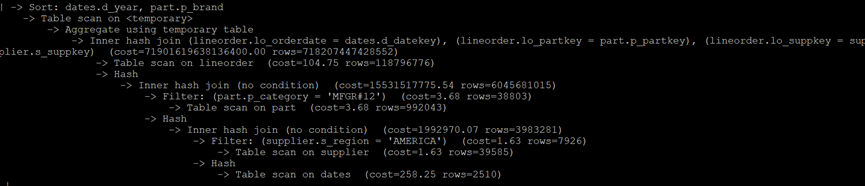
Q2.2
select sum(lo_revenue) as lo_revenue, year(d_datekey) as year, p_brand
from lineorder
join dates on lo_orderdate = d_datekey
join part on lo_partkey = p_partkey
join supplier on lo_suppkey = s_suppkey
where p_brand between 'MFGR#2221' and 'MFGR#2228' and s_region = 'ASIA'
group by year, p_brand
order by year, p_brand;
PostgreSQL执行计划:
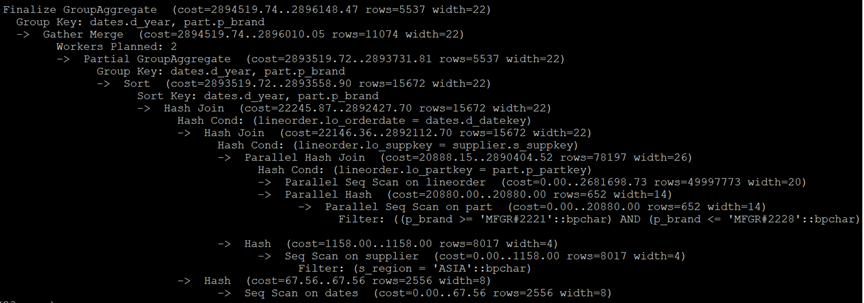
MySQL执行计划:
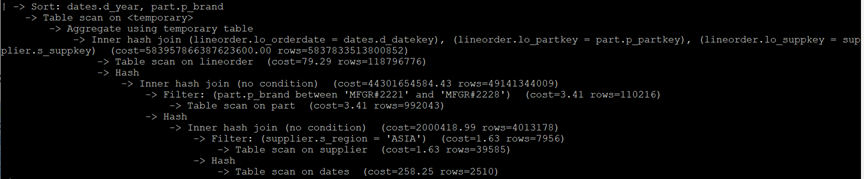
Q2.3
select sum(lo_revenue) as lo_revenue, year(d_datekey) as year, p_brand
from lineorder
join dates on lo_orderdate = d_datekey
join part on lo_partkey = p_partkey
join supplier on lo_suppkey = s_suppkey
where p_brand = 'MFGR#2239' and s_region = 'EUROPE'
group by year, p_brand
order by year, p_brand;
PostgreSQL执行计划:
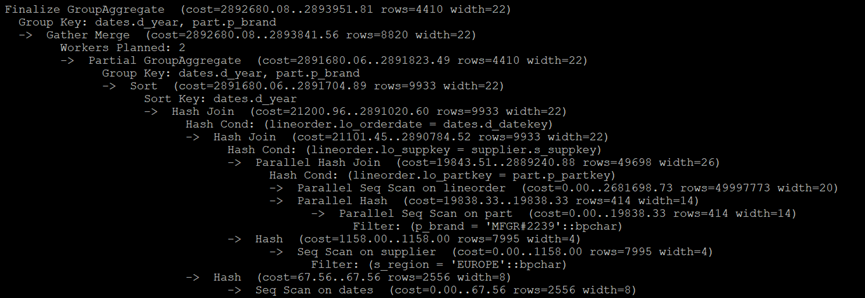
MySQL执行计划:
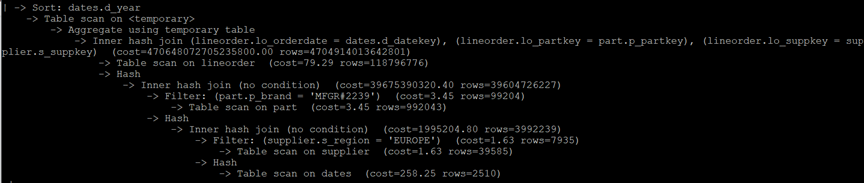
Q3.1
select c_nation, s_nation, year(d_datekey) as year, sum(lo_revenue) as lo_revenue
from lineorder
join dates on lo_orderdate = d_datekey
join customer on lo_custkey = c_custkey
join supplier on lo_suppkey = s_suppkey
where c_region = 'ASIA' and s_region = 'ASIA' and year(d_datekey) between 1992 and 1997
group by c_nation, s_nation, year
order by year asc, lo_revenue desc;
PostgreSQL执行计划:
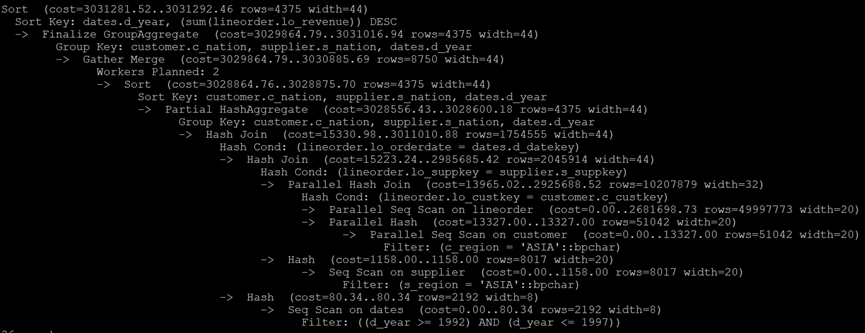
MySQL执行计划:
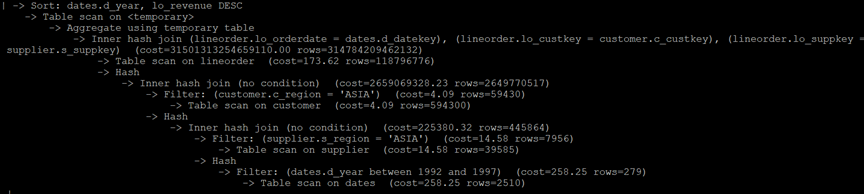
Q3.2
select c_city, s_city, year(d_datekey) as year, sum(lo_revenue) as lo_revenue
from lineorder
join dates on lo_orderdate = d_datekey
join customer on lo_custkey = c_custkey
join supplier on lo_suppkey = s_suppkey
where c_nation = 'UNITED STATES' and s_nation = 'UNITED STATES'
and year(d_datekey) between 1992 and 1997
group by c_city, s_city, year
order by year asc, lo_revenue desc;
PostgreSQL执行计划:
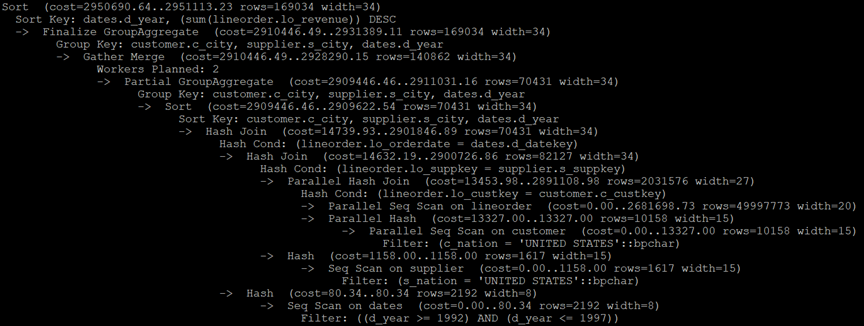
MySQL执行计划:
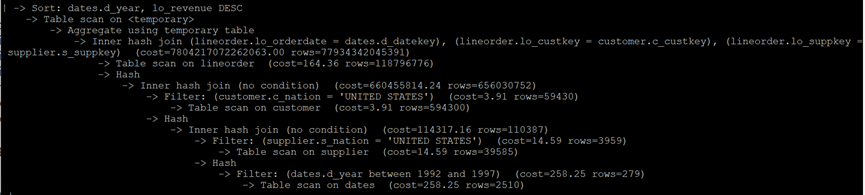
Q3.3
select c_city, s_city, year(d_datekey) as year, sum(lo_revenue) as lo_revenue
from lineorder
join dates on lo_orderdate = d_datekey
join customer on lo_custkey = c_custkey
join supplier on lo_suppkey = s_suppkey
where (c_city='UNITED KI1' or c_city='UNITED KI5')
and (s_city='UNITED KI1' or s_city='UNITED KI5')
and year(d_datekey) between 1992 and 1997
group by c_city, s_city, year
order by year asc, lo_revenue desc;
PostgreSQL执行计划:
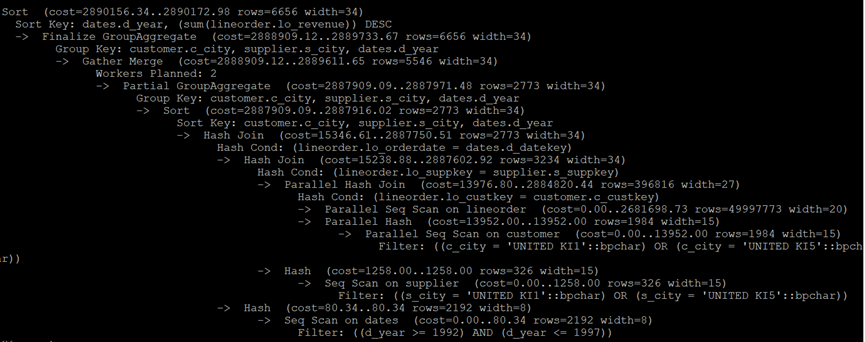
MySQL执行计划:
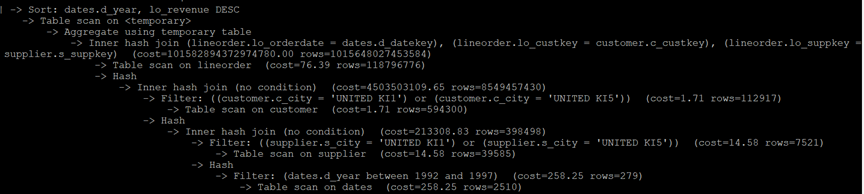
Q4.1
select year(d_datekey) as year, c_nation, sum(lo_revenue) - sum(lo_supplycost) as profit
from lineorder
join dates on lo_orderdate = d_datekey
join customer on lo_custkey = c_custkey
join supplier on lo_suppkey = s_suppkey
join part on lo_partkey = p_partkey
where c_region = 'AMERICA' and s_region = 'AMERICA' and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2')
group by year, c_nation
order by year, c_nation;
PostgreSQL执行计划:
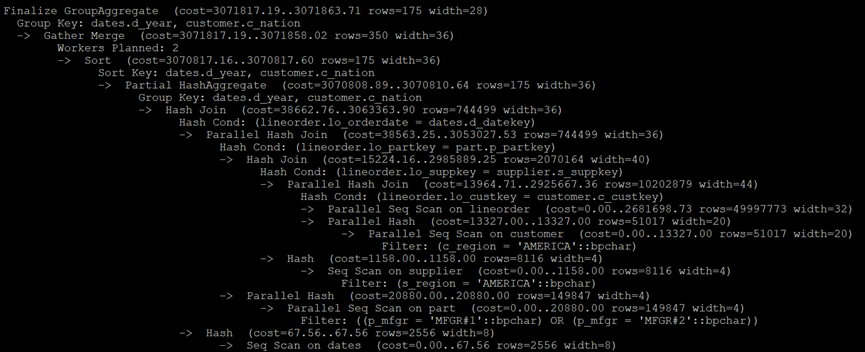
MySQL执行计划:
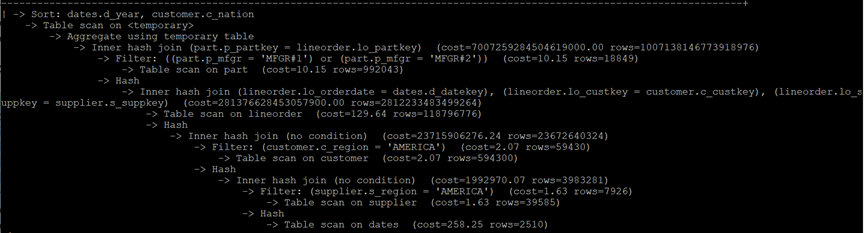
Q4.2
select year(d_datekey) as year, s_nation, p_category, sum(lo_revenue) - sum(lo_supplycost) as profit
from lineorder
join dates on lo_orderdate = d_datekey
join customer on lo_custkey = c_custkey
join supplier on lo_suppkey = s_suppkey
join part on lo_partkey = p_partkey
where c_region = 'AMERICA'and s_region = 'AMERICA'
and (year(d_datekey) = 1997 or year(d_datekey) = 1998)
and (p_mfgr = 'MFGR#1' or p_mfgr = 'MFGR#2')
group by year, s_nation, p_category
order by year, s_nation, p_category;
PostgreSQL执行计划:
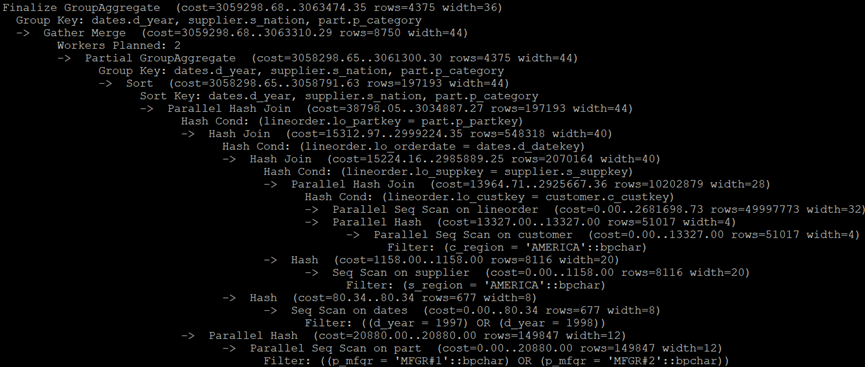
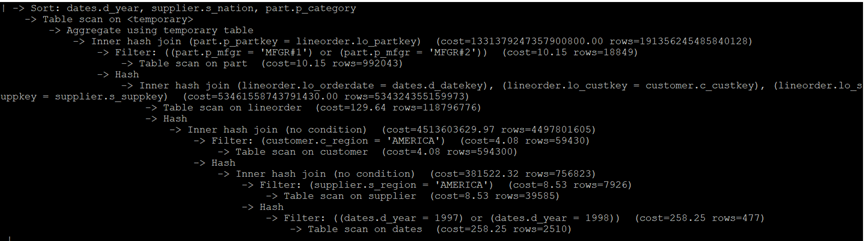
MySQL执行计划:
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
KunlunBase集群基本概念介绍
END
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析最新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www.kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
