




让用户更开心,让业务更成功,为社会创造更多价值,用科技让生活更美好,是科技企业发展的核心目标。我们暂且把该目标简单的表示为 Business KPIs。
过去十年,随着云计算的发展,云原生技术架构逐步被更多的科技企业采纳和应用,主要体现在持续交付(continues delivery)、微服务和容器化(containerization)、构建可观测系统(building observable system)等等方面。在这个过程中,在组织架构上,也发生了相应的一些变化,主要体现为传统架构中,规模庞大的集中化职能团队,逐步打散后重新组合为更小更敏捷、相互独立的闭环应用开发团队(application development team),其作为一个个独立的 feature team,就着某个目标,快速迭代和验证,和业务一起为努力达成 Business KPIs 增砖添瓦。在这个看似自然而然的转变背后,却需要有着强大的「配套技术支撑」。
那么在云原生时代,如何架构技术团队,搭建好该「配套技术支撑」呢?本文将会从以下几个方面来阐述。
首先要从企业发展目标出发,明确好技术团队承担的角色:
所以,最基本的,搭建云原生的「配套技术支撑」,就可以转化为以下三个具体问题:
如何支持业务更快的迭代;
如何保障业务平稳的运行;
如何通过软件工程方法论和实践(software engineering principles),持续提升自动化水平,以降低成本;
其次,技术团队要和业务建立有效的对话体系:
建立有效的对话体系,核心要把握以下两点:
1. 统一目标:技术团队和业务,目标是统一的,都是为了同样的 Business KPIs,在技术范畴内,解决「如何把用户需要的、对用户有用的功能,更快地提供给用户,并保障这些功能稳定的工作」。
2. 统一语言:统一了目标之后,要说双方都听得懂的话。从用户的视角出发,建立数字量化体系,就是一个不错的主意。譬如我举几个例子,来说明:
每个月内,每完成一笔购物的订单,在infra层面所花费的费用。// 用该指标可以有效的按月度量资源的使用效率。 CI/CD工作流每天能够支撑 200 次线上的发布迭代,且用户满意度高于8分。// 该指标可以有效度量迭代支撑效率。 电商交易系统,一个季度的服务不可用时长,不超过13分钟,其中「服务不可用」指无法完成正常交易的订单数量损失超过10%。// 用该指标可以有效的度量核心系统的季度稳定性。 终端用户访问网站,并返回正确数据的延时,其95分位小于500ms。// 用该指标可以有效的表示网站的访问体验。
最后,基于以上的目标和基本工作内容,一个云原生的技术团队架构可以抽象为以下8个要素:
三大团队:应用开发团队、平台团队、可靠性保障团队
两套指标体系:Business KPIs、Service Level Objectives
三个指导思想:Devops、GitOps、IaC
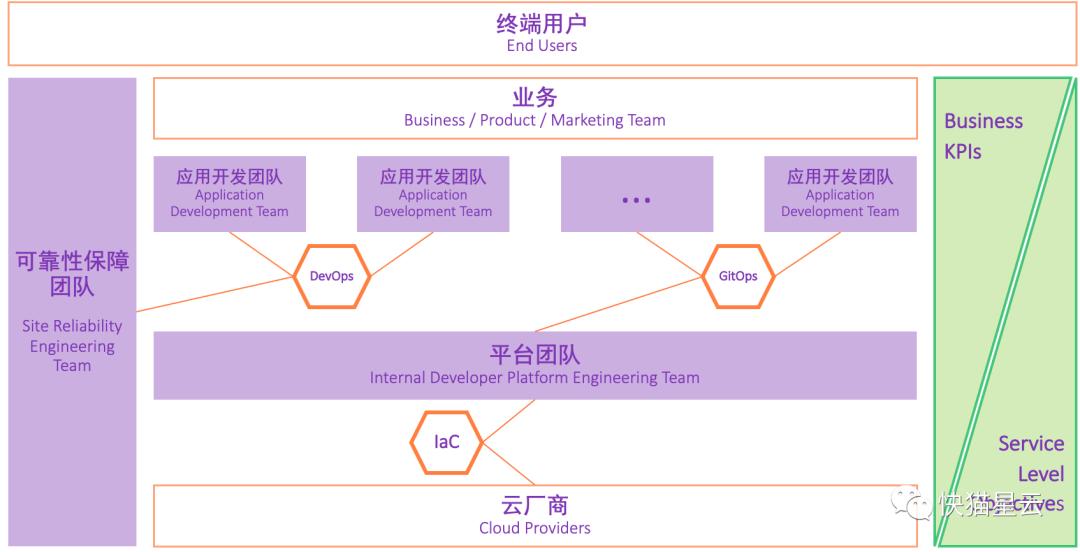
平台团队(Internal Developer Platform Engineering Team,简称IDP团队),旨在建立一个服务于「应用开发团队」的平台(简称IDP平台),通过软件工程的方法,帮助应用开发团队,加快应用的发布速度。IDP平台以产品的形式,提供给用户自助使用(self service)。此外,IDP平台既然是一个产品,那么就要考虑用户的需求、用户的满意度、用户的上手学习曲线、用户的教育等工作,这虽然会带来一定的工作量,但是长期来看,通过产品赋能研发团队,效率远远高于人工支持的效率。
可靠性保障团队(SRE),是一个横向团队,通过软件工程的方法,提供可靠性保障的工具和产品,协同「应用开发团队」、「平台团队」一起,构建可靠运行的系统。SRE 可提供的兵器库中有 SLO,有 monitoring,有 incident management,有 failure mitigation 等等。
应用开发团队(Application Development Team),是平台团队最主要的用户,在企业内部,会有很多这样的 feature team,应用开发团队的总人数也是最多的,和平台团队、SRE团队的人数比例可能会达到 20 比 1,或者50 比 1的水平。
Business KPIs,是业务和技术团队的最根本的共同目标,当然承担的比重不同,对于Business KPIs,自上而下不同团队承担的比重依次下降。
SLOs(Service Level Objectives),SLO 在 Google SRE Book 中有详细的阐述,是 SRE 兵器库中,最重要的兵器之一。SRE团队通过定义 SLO,以及围绕 SLO 搭建相关的稳定性度量和保障系统,搭建工作流,有效的拉齐了 SRE 团队和业务团队、应用开发团队、平台团队在服务可靠性保障工作上的认知。当然,对于 SLOs 的投入精力比重,在各团队中也是不一样的,自上而下,比重依次增加。
DevOps,旨在打破 Development 和 Operation 之间的壁垒,职能双方一起紧密配合构建高度自动化和高度可靠的复杂系统。具象来讲,DevOps可以看作是一种对 Site Reliability Engineering 的最佳实践集合。
GitOps,聚焦于应用发布(Application Delivery),缘起于解决针对 Kubernetes 集群管理和其上应用发布的问题。声明式的配置、版本化管理、高度 pipeline 自动化是 GitOps 的典型特征(GitOps 是 infrastructure as code 在 Kubernetes 生态下的一种演变)。GitOps 有助于保障配置变更的可审计、可重复、一致性。实际落地中来讲,GitOps 可以看作是 Platform Engineering 的最佳实践集合。
云原生组织的先行者:
Weave.works ,被认为创造了 GitOps的术语和理念。Continuous delivery for application teams and continuous control for platform teams. Automate Kubernetes with GitOps one pull request at a time. Terraform, 是 Infrastructure as Code 领域的事实标准。Terraform is an open-source infrastructure as code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. Terraform codifies cloud APIs into declarative configuration files. Flashcat, 提供了针对 SLOs 系统性落地的解决方案,并围绕 SLOs 构建了一套实时、智能、统一的故障应急协同平台,结合 SRE 的最佳实践和方法论,帮助企业技术人员高效协同,从大量报警和异常事件中快速定位关键问题,降低服务中断时间。
关于 Flashcat:
由于企业的 IT 技术分工更细,微服务使得系统的数量和相互依赖更多,服务的架构愈来愈复杂,各个技术团队,都只对自己所负责的系统熟悉,而当公司核心业务发生全局故障时,没有一个独立技术团队有能力、有足够的 Context,
可以为此次 Incident 的处理全权负责,从而拉长了故障止损的时间。
建立全面、实时的度量体系(Realtime Extend Service Level Objectives):从业务视角出发,建立自上而下、层层下钻的故障处理模型; 加强信息协同处理:将数据收集、数据分析的工作自动化和可视化; 最佳实践 + 数据 + 算法:实现特定场景的智能辅助决策;
点击阅读原文可以查看快猫星云|Flashcat 更多信息介绍。
参考资料:
IDP, https://internaldeveloperplatform.org/
SRE vs Platform Engineering, https://blog.getambassador.io/the-rise-of-cloud-native-engineering-organizations-1a244581bda5
Implementing Service Level Objectives, https://learning.oreilly.com/library/view/implementing-service-level/9781492076803/
weave.works, https://www.weave.works/technologies/gitops/
Terraform, https://www.terraform.io/
Flashcat, https://flashcat.cloud/
