




写在前面:注意在本文中的表是指普通表,而与之相关联的TOAST表在本文中的表述为 TOAST 表,注意两者不要搞混。另外本文的测试数据库版本是 PostgreSQL 14.2,列出的相关源码也是基于此版本对应的源码文件,其他版本可能有所不同
一、概述
TOAST(The Oversized-Attribute Storage Technique),超尺寸属性存储技术,又称行外存储技术
在PG中,页是数据在文件存储中的基本单位,默认的大小为8 KB。同时,PG不允许元组(即一行数据)跨页存储,那么对于超长数据,PG 就会启动 TOAST ,具体就是采用压缩和切片的方式。
主要作用:存储一个大字段的值
TOAST表不能单独创建,如果一张表中存在可变长数据类型,并且表包含了main,extended或external存储格式的字段时,系统会自动创建一个和普通表相关联且唯一的TOAST表。当数据超过TOAST_TUPLE_THRESHOLD(默认2KB)时,就会压缩数据,如果压缩完的数据也>2KB,则将会被拆分为更小的块,并存储在相关TOAST表中的多个物理行(行外存储)。每个原始字段值都被一个指针替换,根据这个指针可以找到行外存储的数据。
- 查看数据类型默认的存储策略:
查询 pg_type 系统表:
select typname,typstorage from pg_type where typstorage != 'x' order by typname;
- 对应存储类型的缩写:
源码 src/backend/commands/tablecmds.c storage_name函数
p : plain m : main e : external x : extended复制
TOAST_TUPLE_THRESHOLD定义在src/include/access/heaptoast.hTOAST_TUPLE_THRESHOLD = MaximumBytesPerTuple(TOAST_TUPLES_PER_PAGE) = MAXALIGN_DOWN((BLCKSZ - MAXALIGN(SizeOfPageHeaderData + (tuplesPerPage) * sizeof(ItemIdData))) / (tuplesPerPage))复制
- 检查是否需要TOAST存储的函数定义在src/backend/catalog/toasting.c
needs_toast_table函数中
PostgreSQL 中每个表字段有四种 TOAST 的策略:
-
PLAIN :避免压缩和行外存储。只有那些不需要 TOAST 策略就能存放的数据类型的默认策略,比如整数类型(INT,SMALLINT,BIGINT)、字符类型(CHAR)、布尔类型(BOOLEAN),而对于 text 这类要求存储长度超过页大小的类型,是不允许采用此策略的。
-
EXTENDED :允许压缩和行外存储。大多数可以使用TOAST机制的数据类型默认存储策略。一般会先压缩,如果还是太大,就会行外存储
-
EXTERNAL :允许行外存储,但不许压缩。类似字符串这种会对数据的一部分进行操作的字段,采用此策略可能获得更高的性能,因为不需要读取出整行数据再解压。代价是牺牲存储空间。
-
MAIN :允许压缩,但不许行外存储。不过实际上,为了保证过大数据的存储,行外存储在其它方式(例如压缩)都无法满足需求的情况下,作为最后手段还是会被启动。因此理解为:尽量不使用行外存储更贴切。
存储策略PLAIN、EXTENDED、EXTERNAL和MAIN在PostgreSQL源码中分别被简写为p、x、e和m。通过storage_name函数,分别获取个存储策略所对应的名字。
interger 默认策略为 plain ,而 text 为 extended
二、测试
下面我们来进行一些简单的测试方便大家更好的理解 ,相关的知识点也会在测试过程中讲述:
场景一:TOAST表只在有变长字段,并且存储为main,extended或external时才会创建。
-- 1. 存储格式是 main 会创建 toast 表 malrah_db=> create table toast_test1 (id numeric); CREATE TABLE malrah_db=> select relname,reltoastrelid from pg_class where relname='toast_test1'; relname | reltoastrelid -------------+--------------- toast_test1 | 32896 (1 row) malrah_db=> \d+ toast_test1 Table "public.toast_test1" Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description --------+---------+-----------+----------+---------+---------+-------------+--------------+------------- id | numeric | | | | main | | | Access method: heap -- 2. 存储格式是 plain 不会创建 toast 表 malrah_db=> create table toast_test2 (id int); CREATE TABLE malrah_db=> select relname,reltoastrelid from pg_class where relname='toast_test2'; relname | reltoastrelid -------------+--------------- toast_test2 | 0 (1 row) malrah_db=> \d+ toast_test2 Table "public.toast_test2" Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description --------+---------+-----------+----------+---------+---------+-------------+--------------+------------- id | integer | | | | plain | | | Access method: heap复制
场景二、TOAST 表
-- 1. 创建测试表 malrah_db=# create table tbl_article (id int,author name,title varchar(256),content text); CREATE TABLE --- 查看表结构 malrah_db=# \d+ tbl_article Table "public.tbl_article" Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description ---------+------------------------+-----------+----------+---------+----------+-------------+--------------+------------- id | integer | | | | plain | | | author | name | | | | plain | | | title | character varying(256) | | | | extended | | | content | text | | | | extended | | | Access method: heap --- 查看表的 oid=32926,相关联 toast 表的 oid=32929 malrah_db=# select relname,oid,relfilenode,reltoastrelid from pg_class where relname='tbl_article'; relname | oid | relfilenode | reltoastrelid -------------+-------+-------------+--------------- tbl_article | 32926 | 32926 | 32929 (1 row) --- 查看相关联 toast 表 malrah_db=# \dt pg_toast.pg_toast_32926 List of relations Schema | Name | Type | Owner ----------+----------------+-------------+-------- pg_toast | pg_toast_32926 | TOAST table | postgres (1 row) ---# 默认查看的对象在 PUBLIC schema下,而 toast 表在 pg_toast schema下 --# toast 表的命名:pg_toast_$(oid),其中 oid 是所属表的 oid(注意不是表的 relfilenode。所属表的文件名和 relfilenode 有关,而 toast 表的命名和所属表的 oid 有关,初始创建表时的 oid=relfilenode,而当表进行 truncate 等操作时,表的 relfilenode 会改变,因此表的数据文件也会改变) --- 查看相关联 toast 表的结构 malrah_db=# \d+ pg_toast.pg_toast_32926 TOAST table "pg_toast.pg_toast_32926" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain Owning table: "public.tbl_article" Indexes: "pg_toast_32926_index" PRIMARY KEY, btree (chunk_id, chunk_seq) Access method: heap ---# 有三个可见字段: ---# 1)chunk_id - 用来表示特定 TOAST 值的 OID ,可以理解为具有同样 chunk_id 值的所有行组成原表(这里的 tbl_artical )的 TOAST 字段的一行数据,普通表通过TOAST pointer把一个被TOAST的列关联到这里。 ---# 2)chunk_seq - chunk 的序列号,用来表示该行数据在整个数据中的位置。同一个chunk_id如果大于TOAST_MAX_CHUNK_SIZE,将被切片存储。这里存储切片后的序号。 ---# 3)chunk_data - 实际存储的数据 ---# 在创建 toast 表时会自动创建由(chunk_id, chunk_seq)为主键的名为 toast_name_index 的索引 -- 2. 插入测试数据 malrah_db=# insert into tbl_article select 1,'maleah','toast_test',repeat('This is a toast test table',3000); INSERT 0 1 --- 查看表的列大小:1226<2048 猜想:此时还未进行行外存储 malrah_db=# select pg_column_size(id),pg_column_size(author),pg_column_size(title),pg_column_size(content) from tbl_article; pg_column_size | pg_column_size | pg_column_size | pg_column_size ----------------+----------------+----------------+---------------- 4 | 64 | 11 | 929 (1 row) --- 查看表的大小 malrah_db=# select pg_relation_size(32926); pg_relation_size ------------------ 8192 (1 row) -- 查看 TOAST 表的大小:0 malrah_db=# select pg_relation_size(32929); pg_relation_size ------------------ 0 (1 row) ---# 验证猜想:当表的字段 <TOAST_TUPLE_THRESHOLD(2 KB)时,不会进行行外存储 -- 3. 更新字段 malrah_db=# update tbl_article set content = repeat(content,3) where id = 1 ; UPDATE 1 --- 查看表的列大小:2712>2048,猜想:进行行外存储 malrah_db=# select pg_column_size(id),pg_column_size(author),pg_column_size(title),pg_column_size(content) from tbl_article; pg_column_size | pg_column_size | pg_column_size | pg_column_size ----------------+----------------+----------------+---------------- 4 | 64 | 11 | 2712 (1 row) --- 查看表的大小 malrah_db=# select pg_relation_size(32926); pg_relation_size ------------------ 8192 (1 row) --- 查看 toast 表的大小 malrah_db=# select pg_relation_size(32929); pg_relation_size ------------------ 8192 (1 row) --- 查看表的 超长字段的长度 malrah_db=# select id,author,title,length(content) from tbl_article ; id | author | title | length ----+--------+------------+-------- 1 | maleah | toast_test | 234000 (1 row) --- 查看 toast 表:出现数据 malrah_db=# select chunk_id,chunk_seq,length(chunk_data) from pg_toast.pg_toast_32926; chunk_id | chunk_seq | length ----------+-----------+-------- 32931 | 0 | 1996 32931 | 1 | 716 (2 rows) malrah_db=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_32926 GROUP BY 1 ORDER BY 1; chunk_id | chunks | pg_size_pretty ----------+--------+---------------- 32931 | 2 | 2712 bytes (1 row) ---# 可以看到,直到 content 的长度为 234000 时(已远远超过 page 的大小 8KB),对应 TOAST 表中才有了 2 行数据,且长度都是略小于 2K。原因是在 extended 的策略下,先压缩,压缩后的数据大于 2024,使用行外存储技术,一行放不下,采用分片(多行)存储复制
场景三、修改存储策略
格式:
alter table table_name alter column {$column_name} set storage { PLAIN | MAIN | EXTERNAL | EXTENDED } ;
复制测试:
-- 将 content 的 TOAST 策略改为 EXTERNAL,以禁止压缩 alter table tbl_article alter content set storage external; -- 查看 tbl_article 表结构:策略改为 external malrah_db=# \d+ tbl_article Table "public.tbl_article" Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description ---------+------------------------+-----------+----------+---------+----------+-------------+--------------+------------- id | integer | | | | plain | | | author | name | | | | plain | | | title | character varying(256) | | | | extended | | | content | text | | | | external | | | Access method: heap --# 注:已有数据的存储策略不会被改变,只对新增数据行的策略生效 -- 新增数据 insert into tbl_article select 2,'maleah','toast_test_another',repeat('This is a toast test table',500); -- 查看表的字段长度 malrah_db=# select id,author,title,length(content) from tbl_article where id = 2; id | author | title | length ----+--------+--------------------+-------- 2 | maleah | toast_test_another | 13000 (1 row) -- 查看 TOAST 表 malrah_db=# select chunk_id,chunk_seq,length(chunk_data) from pg_toast.pg_toast_32926; chunk_id | chunk_seq | length ----------+-----------+-------- 32931 | 0 | 1996 32931 | 1 | 716 32932 | 0 | 1996 32932 | 1 | 1996 32932 | 6 | 1024 32932 | 2 | 1996 32932 | 3 | 1996 32932 | 4 | 1996 32932 | 5 | 1996 (9 rows) malrah_db=# SELECT chunk_id, COUNT(*) as chunks, sum(octet_length(chunk_data)::bigint) FROM pg_toast.pg_toast_32926 GROUP BY 1 ORDER BY 1; chunk_id | chunks | sum ----------+--------+------- 32931 | 2 | 2712 32932 | 7 | 13000 (2 rows) --# 可以看到,原表新增 content 字段的长度 = TOAST 表对应 chunk 的总长度,没有进行压缩复制
在进行修改存储策略的时候要注意:无法将一个不支持TOAST机制的数据类型(列)的存储策略修改为其他
malrah_db=# alter table tbl_article alter id set storage external; ERROR: column data type integer can only have storage PLAIN复制
小结:
- 如果策略允许压缩,则 TOAST 有限选择压缩
- 不管是否压缩,一旦数据超过 2KB 左右,就会启用行外存储
- 修改 TOAST 策略,不会影响现有数据的存储方式
TOAST 机制的实现,内部采用了 LZ 压缩算法
场景四、在超长字段上添加索引
-- 测试超长字段索引 malrah_db=# create index idx_content on tbl_article (content); ERROR: index row requires 13016 bytes, maximum size is 8191复制
索引无法在超长字段上创建,有两处函数会报这个错
src/backend/access/spgist/spgutils.c
src/backend/access/common/indextuple.c
/*
* Here we make sure that the size will fit in the field reserved for it
* in t_info.
*/
#define INDEX_SIZE_MASK 0x1FFF // 0x1FFF = (int)8191
if ((size & INDEX_SIZE_MASK) != size) // size = hoff + data_size。调用 heap_compute_data_size 函数计算 data_size
ereport(ERROR,
(errcode(ERRCODE_PROGRAM_LIMIT_EXCEEDED),
errmsg("index row requires %zu bytes, maximum size is %zu",
size, (Size) INDEX_SIZE_MASK)));
复制三、总结
1、相关查询
-- 根据原表查看相关 toast 表的 oid select relname,oid,reltoastrelid from pg_class where relname='table_name'; -- 查看指定原表相关联的 toast 表名 SELECT c1.relname, c2.relname AS toast_relname FROM pg_class c1 JOIN pg_class c2 ON c1.reltoastrelid = c2.oid WHERE c1.relname = 'tbl_article' AND c1.relkind = 'r'; relname | toast_relname -------------+---------------- tbl_article | pg_toast_32926 (1 row) -- 根据表的表名查看对应的 relfilenode [postgres@node1 ~]$ oid2name -d malrah_db -t pg_toast_32926 From database "malrah_db": Filenode Table Name -------------------------- 32929 pg_toast_32926 select oid,relname,relfilenode from pg_class where relname = 'pg_toast_32926' ; -- 查看 toast 表上的索引的 oid select * from pg_statio_all_indexes where relname = 'toast_table_name'; -- 玩了个剧没用的语句(我用的 WITH 和 INNER JOIN,也可以用 LIKE 模糊查询,定义个变量写到函数中,有兴趣的可以自行尝试下) with tmp as (select oid,relname,relfilenode from pg_class where oid = (select reltoastrelid from pg_class where relname = 'tbl_article')) select t.oid as 表oid , t.relname as 表名, t.relfilenode as 表文件名, toast.oid as toast表oid, toast.relname as toast表名, toast.relfilenode as toast表文件名, index.oid as toast表索引oid, index.relname as toast表索引名, index.relfilenode as toast表索引文件名 from (pg_class as t inner join (select * from tmp)as toast on t.reltoastrelid = toast.oid ) inner join (select i.oid,i.relname,i.relfilenode,tmp1.relname as toast_name from pg_class as i inner join (select * from pg_statio_all_indexes where relid = (select oid from tmp)) as tmp1 on i.oid = tmp1.indexrelid)as index on toast.relname = index.toast_name ; 表oid | 表名 | 表文件名 | toast表oid | toast表名 | toast表文件名 | toast表索引oid | toast表索引名 | toast表索引文件名 -------+-------------+----------+------------+----------------+---------------+----------------+----------------------+------------------- 32926 | tbl_article | 32940 | 32929 | pg_toast_32926 | 32941 | 32930 | pg_toast_32926_index | 32942 (1 row)复制
2、使用 TOAST 表的优缺点
1)优点
- UPDATE一个普通表时,当该表的TOAST表存储的列没有修改时,TOAST表不需要更新,这样更新效率得到提升
- 由于TOAST在物理存储上和普通表分开,所以当SELECT时没有查询被TOAST的列数据时,不需要把这些TOAST的PAGE加载到内存,从而加快了检索速度并且节约了使用空间。
- 在排序时,由于TOAST和普通表存储分开,当针对非TOAST字段排序时大大提高了排序速度。
2)不足
- 在超长字段上添加索引是不被允许的
- 超长字段的更新慢
3)注意事项
- 当变长字段上需要使用索引时,权衡CPU和存储的开销,考虑是否需要压缩或非压缩存储。(压缩节约磁盘空间,但是带来CPU的开销)
- 对于经常要查询或UPDATE的变长字段,如果字段长度不是太大,可以考虑使用MAIN存储。
- 在超长字段,或者将来会插入超长值的字段上建索引的话需要注意,因为索引最大不能超过三分之一的PAGE,所以超长字段上可能建索引不成功,或者有索引的情况下,超长字段插入值将不成功。解决办法一般可以使用MD5值来建,当然看你的需求了。
3、哪些tuple会触发TOAST?
当行的长度超过TOAST_TUPLE_THRESHOLD时,会调用toast_insert_or_update,即触发TOAST。

src/backend/access/heap/heapam.c
四、”坑“
DELETE、VACUUM、VACUUM FULL 和 TRUNCATE
实验步骤(控制变量):
--1. create table + 插入数据 insert into tbl_article select 2,'maleah','toast_test_another',repeat('This is a toast test table',500); --2. DELETE + VACUUM --3. drop table + create table + 插入数据 --3. delete + VACUUM FULL --4. drop table + create table + 插入数据 --5. TRUNCATE --# 由于两次重新创建表后只有 oid 不同,所以对下面展示图片中的某些地方做了些更改,能更方便看出区别复制



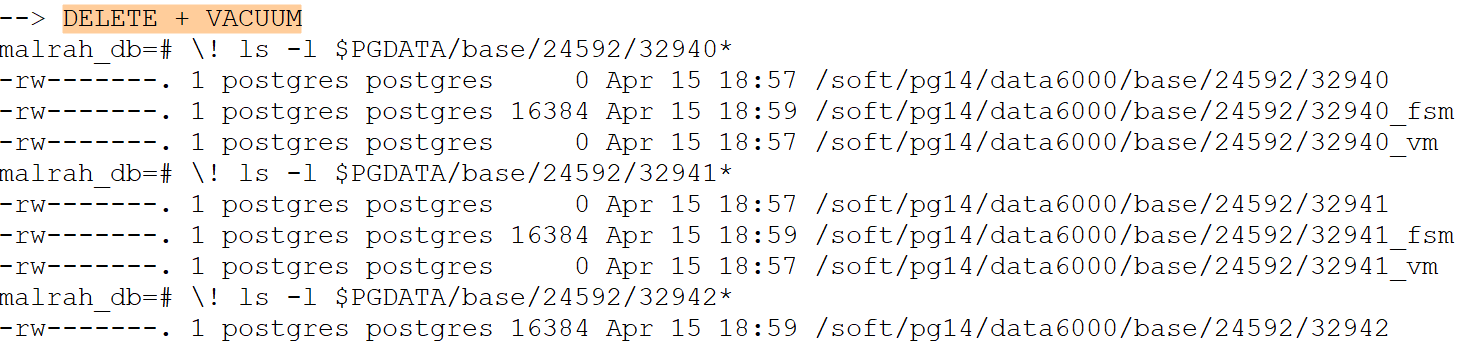
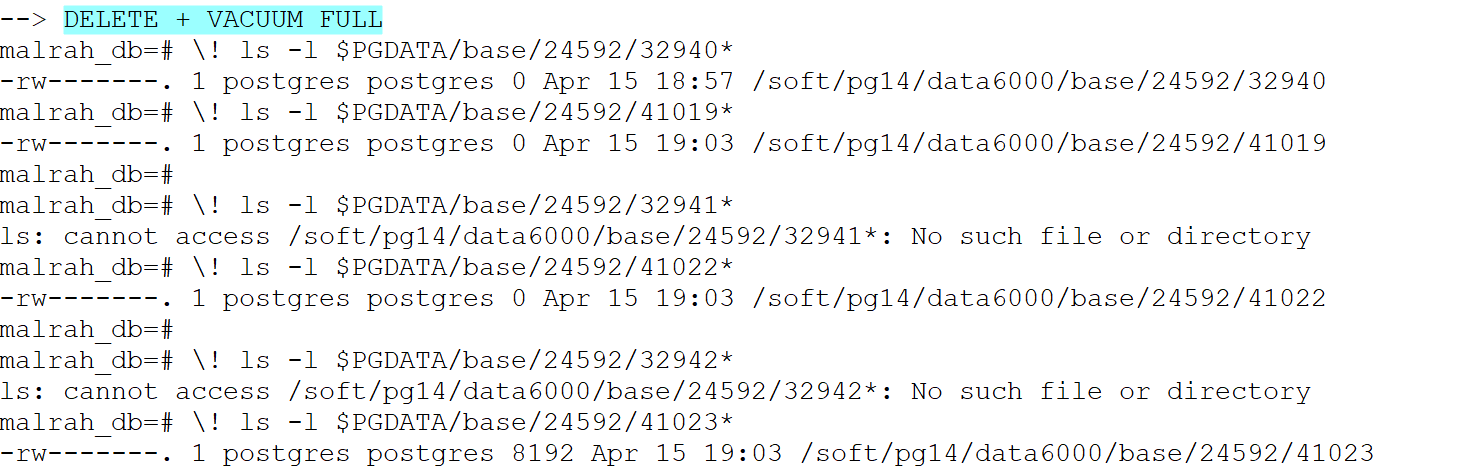
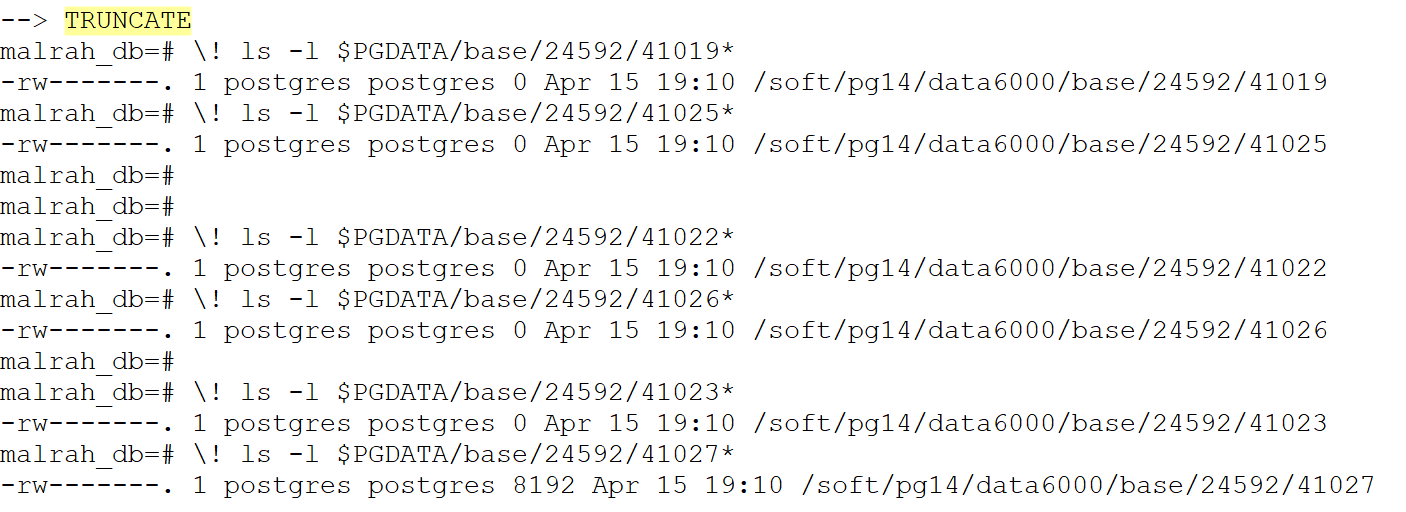
表格:
| delete+vacuum | delete + vacuum full | truncate | |
|---|---|---|---|
| 表oid | 不变 | 不变 | 不变 |
| 表文件名 | 不变 | 变 | 变 |
| 表main文件大小 | 8 --> 0 | 8 --> 0 | 8 --> 0 |
| toast表oid | 不变 | 不变 | 不变 |
| toast表文件名 | 不变 | 变(原文件不存在) | 变(原文件存在) |
| toast表main文件 | 16 --> 0 | 16 --> 0 | 16 --> 0 |
| toast表索引oid | 不变 | 不变 | 不变 |
| toast表索引文件名 | 不变 | 变(原文件不存在) | 变(原文件存在) |
| toast表索引main文件 | 16 --> 16 | 16 --> 8 | 16 --> 8 |
总结:
-
对象的 oid 是唯一标识符,无论进行上述哪种操作,对象的 oid 都不会改变
-
三种方式都会清理表数据,toast 表数据也被清理
-
vacuum 操作不会改变 relation 的 relfilnode,vacuum full 和 truncate 都会改变
-
delete + vacuum full 和 truncate 的不同之处,前者会把 toast 表相关的原文件删除,而 truncate 则不会
五、相关知识点
1、获取数据库对象的大小
在PostgreSQL中有几种方法可以获取数据库对象的大小:(下面这张图源自微信公众号PostgreSQL 学徒,灿灿大佬讲了很多学习PG不容错过的优质文章)
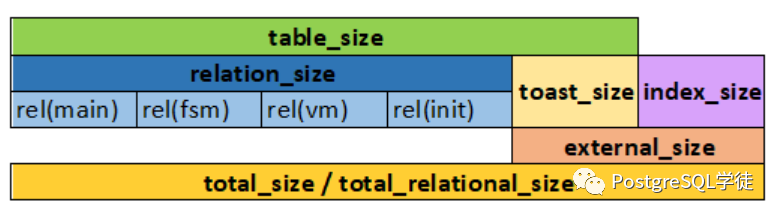
pg_table_size: 获取表的大小,包括 TOAST,但不包括索引pg_relation_size: 获取表的大小。一个参数是main主数据文件的大小,可以增加一个参数( fork text)指定返回某个分支文件的大小pg_total_relation_size:获取表的大小,包括索引和TOAST
另一个有用的功能是pg_size_pretty:用于以友好的格式显示 size。
-- 查看 TOAST 表的索引 malrah_db=# select * from pg_statio_all_indexes where relname = 'pg_toast_32926'; relid | indexrelid | schemaname | relname | indexrelname | idx_blks_read | idx_blks_hit -------+------------+------------+----------------+----------------------+---------------+-------------- 32929 | 32930 | pg_toast | pg_toast_32926 | pg_toast_32926_index | 2 | 19 (1 row) -- 查看 TOAST 表文件的大小 malrah_db=# \! ls -l $PGDATA/base/24592/32929* -rw-------. 1 postgres postgres 16384 Apr 14 14:29 /soft/pg14/data6000/base/24592/32929 -rw-------. 1 postgres postgres 24576 Apr 14 14:29 /soft/pg14/data6000/base/24592/32929_fsm -- 查看TOAST表索引文件的大小 malrah_db=# \! ls -l $PGDATA/base/24592/32930* -rw-------. 1 postgres postgres 16384 Apr 14 14:29 /soft/pg14/data6000/base/24592/32930复制
基于上面所述,TOAST 表的大小计算方式:
-
pg_relation_size各个分支文件大小相加-- 查看 TOAST 表主分支的大小 --- 一个参数默认返回主数据文件大小 malrah_db=# select pg_size_pretty(pg_relation_size(32929)); pg_size_pretty ---------------- 16 kB (1 row) --- 两个参数可以指定返回的参数文件大小 malrah_db=# select pg_size_pretty(pg_relation_size(32929,'main')); pg_size_pretty ---------------- 16 kB (1 row) -- 查看 TOAST 表fsm分支的大小 malrah_db=# select pg_size_pretty(pg_relation_size(32929,'fsm')); pg_size_pretty ---------------- 24 kB (1 row) -- 查看 TOAST 索引的大小 malrah_db=# select pg_size_pretty(pg_relation_size(32930)); pg_size_pretty ---------------- 16 kB (1 row) -- 使用 pg_indexes_size 函数查看索引的大小是0 malrah_db=# select pg_size_pretty(pg_indexes_size(32930)); pg_size_pretty ---------------- 0 bytes (1 row)复制 -
pg_table_size - pg_relation_sizemalrah_db=# select pg_size_pretty(pg_table_size(32926) - pg_relation_size(32926)); pg_size_pretty ---------------- 56 kB (1 row)复制
结论:
pg_table_size - pg_relation_size得出的 TOAST 表的大小还包括 TOAST表上的索引的 size
2、生成给定长度的随机字符串的函数
CREATE OR REPLACE FUNCTION generate_random_string( length INTEGER, characters TEXT default '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' ) RETURNS TEXT AS $$ DECLARE result TEXT := ''; BEGIN IF length < 1 then RAISE EXCEPTION 'Invalid length'; END IF; FOR __ IN 1..length LOOP result := result || substr(characters, floor(random() * length(characters))::int + 1, 1); end loop; RETURN result; END; $$ LANGUAGE plpgsql; -- 生成一个由 10 个随机字符组成的字符串: SELECT generate_random_string(10); -- 也可以提供一组字符来生成随机字符串。例如,生成一个由 10 个随机数字组成的字符串: SELECT generate_random_string ( 10 , '1234567890' );复制
参考
https://www.modb.pro/db/150078
https://github.com/digoal/blog/blob/master/201103/20110329_01.md
https://www.modb.pro/db/130782
写在最后:与 TOAST 相关的内容还有很多,有兴趣的可自行研究。在此可以提供发现的一个有趣现象:系统自动创建的 tosast 表的 oid 总是等于表的 oid + 3,有兴趣的可以上源码探寻原因。
评论

 0 点赞
0 点赞 0 点赞
0 点赞 0 点赞
0 点赞