




相对于PL/SQL Developer、Navicat、Oracle SQL Developer这类图形化SQL工具,sqlplus 显得简陋了一点,但它不依赖网络可以直接在服务器上执行。
对于需要长时间运行的任务,在服务器上执行有天然的优势,可以防止网络波动以及工具卡死崩溃。
但在实际执行过程中发现,sqlplus 也有自己的弱点。原本在PL/SQL Developer可以运行的SQL,在 sqlplus 中有可能会报错。
通过 @/tmp/mz.sql 执行含中文的SQL,报 SP2-0734 错误
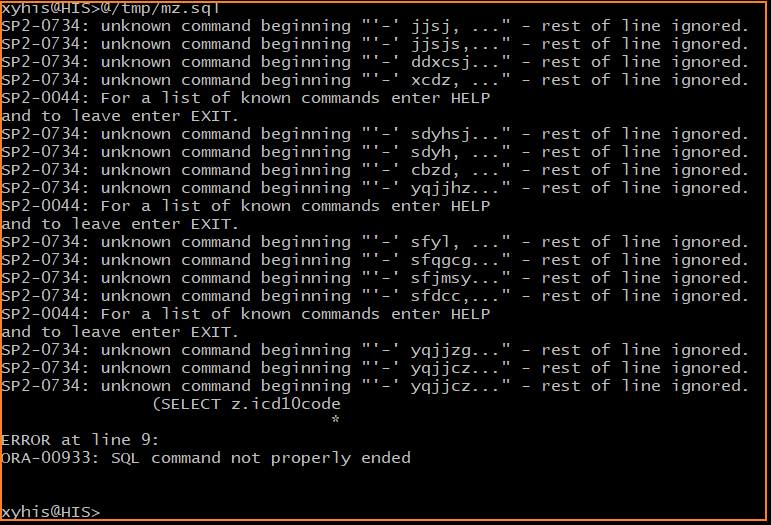
sqlplus 报的是 SP2-0734 的错,检查 SQL 后发现是因为原 SQL 中有空行

sqlplus 不能很好地处理空行,所有 sql 需要一次性写完,中间不能用空行分隔,在 sqlplus 中空行被认为是 sql 语句结束。
去掉空行后,语句可以执行,但遇到了其它问题。插入的数据中,如果是来自 SQL 代码中硬编码的中文字段,插入到数据库中后会出现乱码。
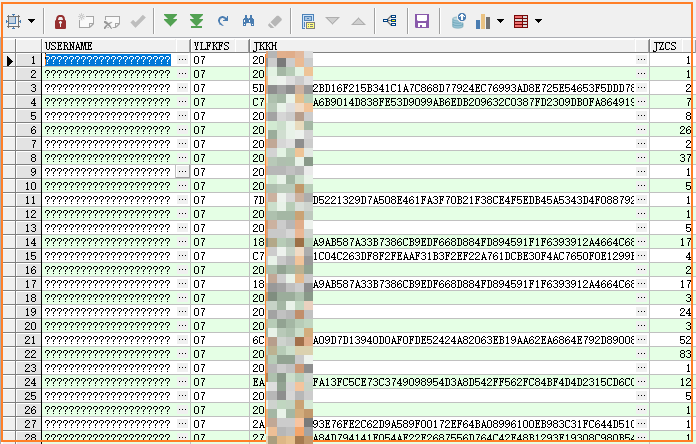
这是因为 sql 文件的编码格式与数据库编译不一致导致的,需要将 sqlplus 的编码与 sql 文件的编码都搞一致。
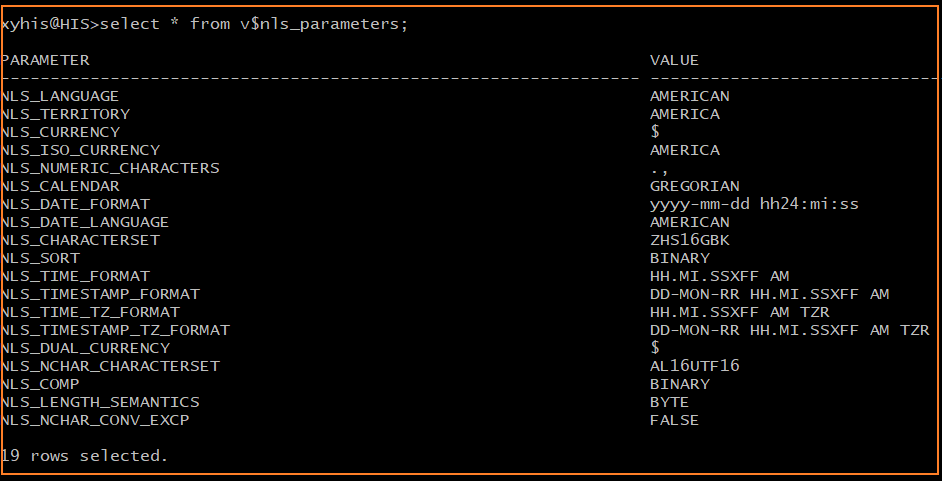
首先检查数据库的编码
select * from v$nls_parameters;复制
在启动 sqlplus 前设置 NLS_LANG 环境变量
export NLS_LANG='AMERICAN_AMERICA.ZHS16GBK'复制
设置规则为:
NLS_LANG=<Language>_<Territory>.<Characterset>
同时检查 sql 文本文件编码格式
[root@racdb1 tmp]# file mz.sqlmz.sql: UTF-8 Unicode text复制
通过 file 可以检查文本文件编码类型,然后对文本文件进行格式转换
iconv -f UTF-8 -t GBK mz.sql > mz1.sql复制
以上是将 UTF-8编码转为 GBK 编码。或者不用这么复杂,直接找一个支持改变编码的编辑器,将 sql 拷贝进编辑器中,然后另存为即可保存为正确编码。比如 vscode 支持对编码进行更改:

通过改变 sql 文本文件的编码,调整 sqlplus 的 NLS_LANG 环境变量,再次执行 sql,中文查询和数据插入都可正常执行。

如果不处理好编码问题,在 where 条件中的中文条件可能不会正常匹配。当前解决了 sqlplus 的识别和执行问题,但此时终端显示仍然是乱码。
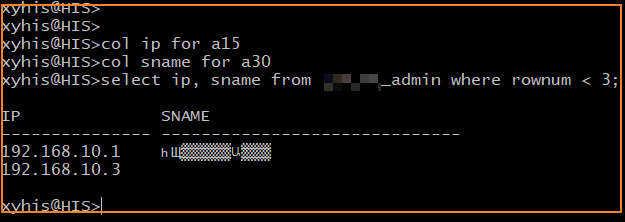
这是与终端程序的设置有关,原终端程序的编码设置为 UTF-8,我们将其改为与数据库一致。
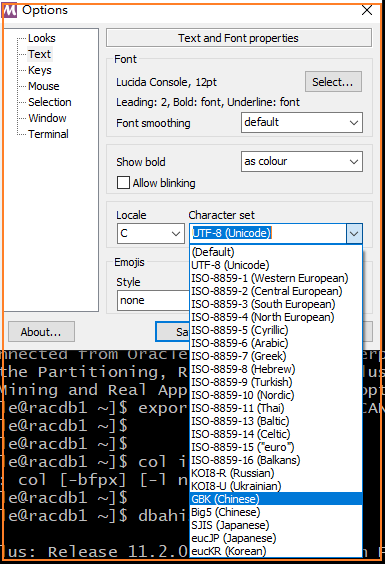
再次执行,中文已经可以正常显示了:
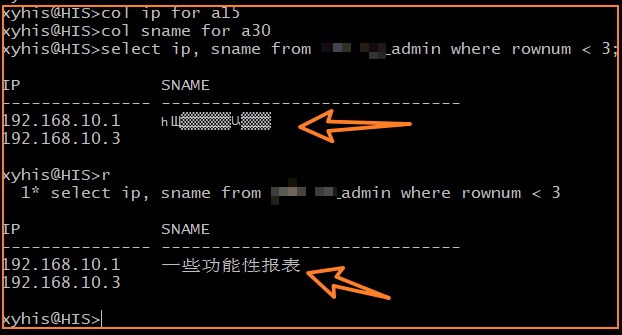
同样,通过 cat 查看 gkb 编码的文本文件,文本内容也可以正常显示了。




