




今天来看两个MySQL自带的性能分析工具——profiling、optimizer trace。
前段时间,我们学习了执行计划EXPLAIN,EXPLAIN是从MySQL怎样解析执行SQL的角度分析SQL优劣。而profiling是从SQL执行时资源使用情况角度来分析SQL。还有一个区别就是:EXPLAIN是SQL执行前生成的,不会真正执行SQL;而profiling是SQL执行后生成,SQL被真正执行后产生的结果。
下面就开始今天的内容。


profiling


profiling简介
查看profiling相关参数
show variables like '%profiling%';复制
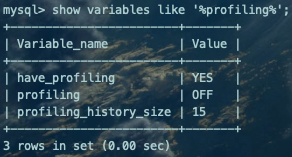
have_profiling:只读变量,用于控制是否由系统变量开启或禁用profiling。
profiling:开启或关闭SQL语句剖析功能的开关。
profiling_history_size:设置保留profiling的数目,默认值为15,范围为0至100,为0时将禁用profiling。
查看profile帮助:
help profile;复制
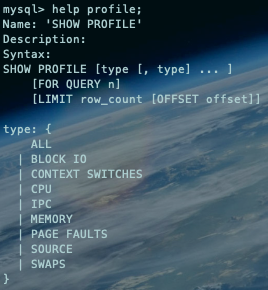
type:
ALL:显示所有的开销信息;
BLOCK IO:显示块IO相关开销;
CONTEXT SWITCHES:上下文切换相关开销;
CPU:显示CPU相关开销信息;
IPC:显示发送和接收相关开销信息;
MEMORY:显示内存相关开销信息;
PAGE FAULTS:显示页面错误相关开销信息;
SOURCE:显示和source_function、source_file、source_line相关的开销信息;
SWAPS:显示交换次数相关开销的信息。
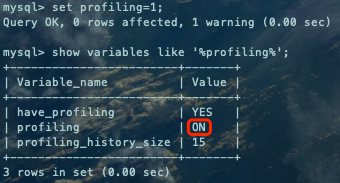
使用profiling
set profiling=1;show variables like '%profiling%';复制
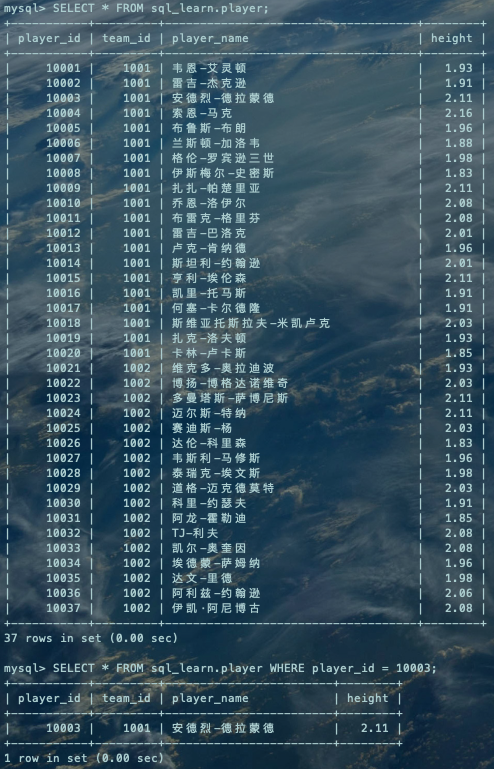
执行SQL:
SELECT * FROM sql_learn.player;SELECT * FROM sql_learn.player WHERE player_id = 10003;复制
show profiles;复制
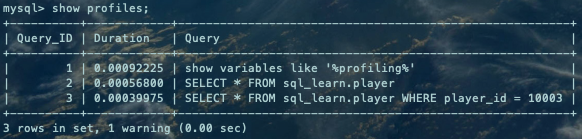
当前会话所有执行的SQL都会列出来。看到一个warning。
show warnings;复制

可以看到告警是说SHOW PROFILES命令在后面的版本中会被Performance Schema替换掉。
开启profiling后,我们可以通过show profile等方式查看,其实这些开销信息被记录到information_schema.profiling表中。注意:show profile之类的语句不会被profiling,即自身不会产生Profiling。我们在当前会话执行show profile,显示的结果是刚刚执行show warnings产生的相应开销。
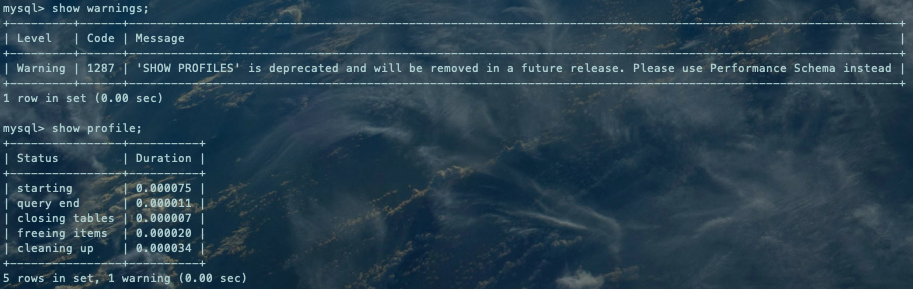
获取指定查询的开销(Druation列表示持续时间):
show profiles;show profile for query 2; --全表扫描show profile for query 3; --根据主键匹配结果集复制
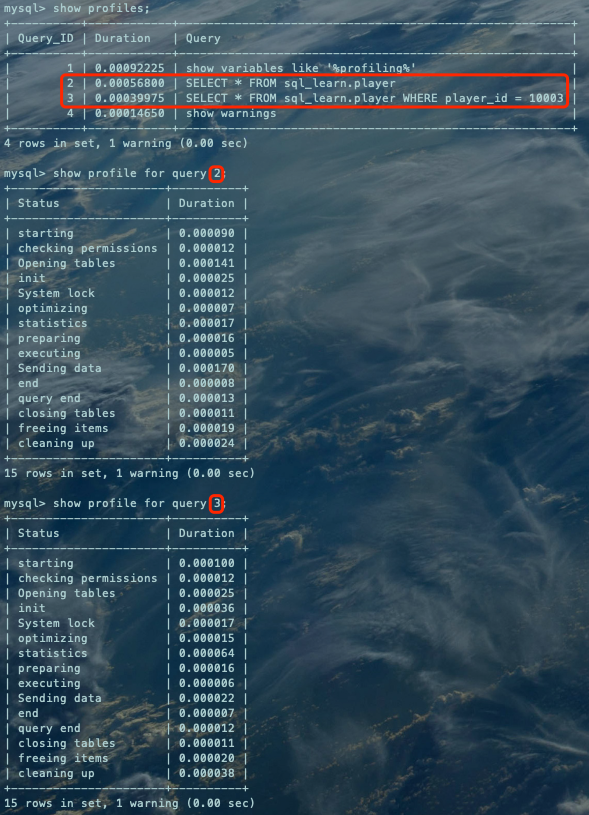
上图中纵向栏Status含义解读:
| 纵向栏名称 | 描述 |
|---|---|
| starting | 开始 |
| checking permissions | 检查是否有权限 |
| Opening tables | 打开表 |
| init | 初始化 |
| System lock | 等待系统级锁 |
| optimizing | 优化器 |
| statistics | 数据统计解析执行计划 |
| preparing | 执行前准备 |
| executing | 执行 |
| Sending data | 从server端发送数据到客户端,也有可能是接收存储引擎层返回的数据,再发送给客户端,数据量很大时这个值会较大(这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集+发送 数据”) |
| end | 结束 |
| query end | 表示语句执行完毕了,但是还有一些后续工作没做完时状态 |
| closing tables | 用完表,关闭该表,刷新到磁盘 |
| freeing items | 释放查询缓存里面的空间,如果是DML操作,相应的缓存里的记录就无效了,所以需要有这一步做处理 |
| cleaning up | 打扫“战场”,释放内存,释放持有的句柄 |
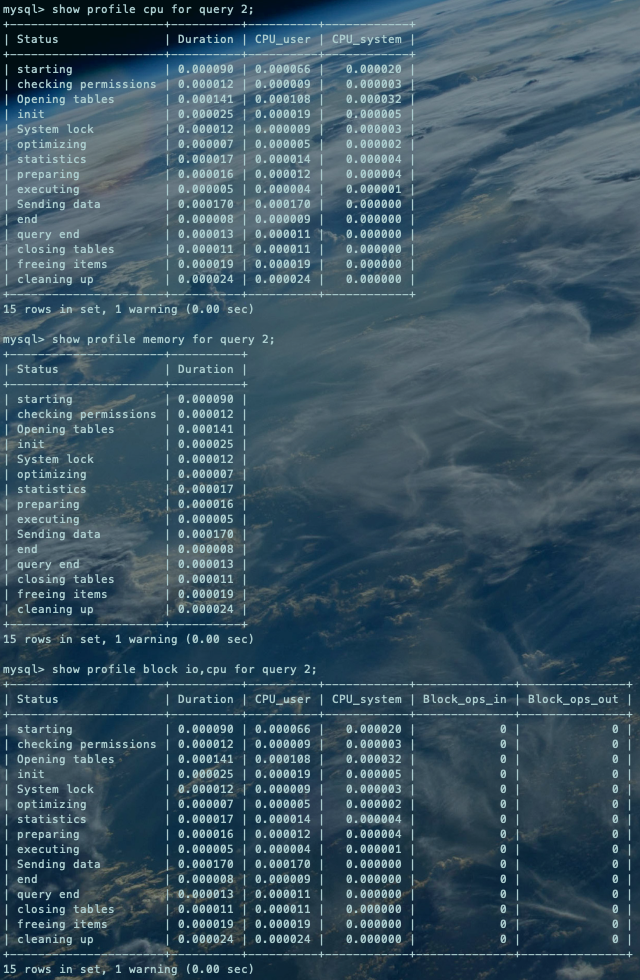
show profile cpu for query 2; --查看CPU部分的开销show profile memory for query 2; --查看MEMORY部分的开销show profile block io,cpu for query 2; --查看不同资源开销复制
我们也可以查看所有的开销:
show profile all for query 3;复制

| 横向栏名称 | 描述 |
|---|---|
| Status | 状态 |
| Duration | 状态总持续时间 |
| CPU_user | CPU用户 |
| CPU_system | CPU系统 |
| Context_voluntary | 上下文主动切换 |
| Context_involuntary | 上下文被动切换 |
| Block_ops_in | 阻塞的输入操作 |
| Block_ops_out | 阻塞的输出操作 |
| Messages_sent | 消息发出 |
| Messages_received | 消息接收 |
| Page_faults_major | 主分页错误 |
| Page_faults_minor | 次分页错误 |
| Swaps | 交换次数 |
| Source_function | 原函数(调用源码中的函数) |
| Source_file | 源文件(MySQL源码中对应的.cc文件) |
| Source_line | 源代码行(对应源码文件中的代码行数) |
optimizer trace
optimizer trace简介
查看optimizer trace相关参数
SHOW VARIABLES LIKE 'optimizer_trace';复制
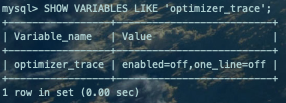
enabled:值为off,表示这个功能默认是关闭的。 one_line:值为off,这个参数的值是控制输出格式的,如果为on那么所有输出都将在一行中展示,不适合人阅读,所以我们就保持其默认值为off。
使用optimizer trace
SET optimizer_trace="enabled=on";复制

SHOW CREATE TABLE information_schema.OPTIMIZER_TRACE\G复制
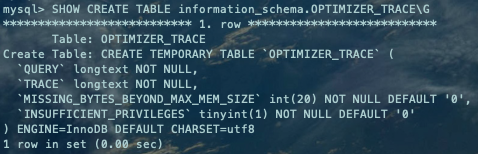
QUERY:查询的SQL语句。 TRACE:优化过程的JSON格式文本。 MISSING_BYTES_BEYOND_MAX_MEM_SIZE:由于优化过程可能会输出很多,如果超过某个限制时,多余的文本将不会被显示,这个字段展示了被忽略的文本字节数。 INSUFFICIENT_PRIVILEGES:是否没有权限查看优化过程,默认值是0,只有某些特殊情况下才会是1,我们暂时不关心这个字段的值。
# 1. 打开optimizer trace功能;SET optimizer_trace="enabled=on";# 2. 输入SQL查询语句;SELECT ...; # 3. 从OPTIMIZER_TRACE表中查看上一个查询的优化过程;SELECT * FROM information_schema.OPTIMIZER_TRACE;# 4. 可能你还要观察其他语句执行的优化过程,重复上边的第2、3步;...# 5. 当你停止查看语句的优化过程时,把optimizer trace功能关闭。SET optimizer_trace="enabled=off";复制
 )。
)。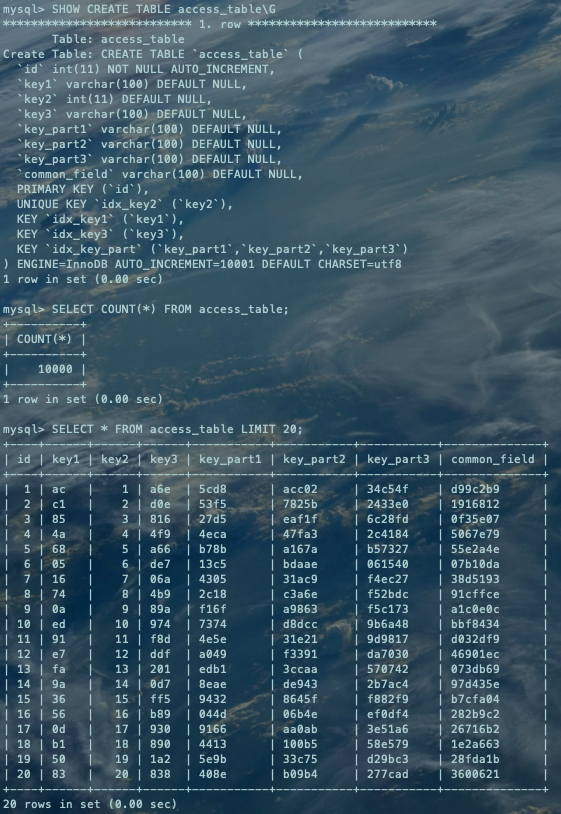
用一个搜索条件比较多的查询语句,执行计划如下:
DESC SELECT * FROM table_query_cost WHERE key1 > 'ce' AND key2 < 10000 AND key3 IN ('b88', '6cd', 'ac3') AND common_field = 'bb41383';复制

由上图可知,possible_keys可能使用到的索引有3个:uq_key2、idx_key1、idx_key3,但是优化器最终选择了key:idx_key3,而为什么不选择其他索引我们就需要otpimzer trace功能来查看优化器的选择过程:
# 1、打开optimizer_traceSET optimizer_trace="enabled=on";# 2、执行SQLSELECT * FROM table_query_cost WHERE key1 > 'ce' AND key2 < 10000 AND key3 IN ('b88', '6cd', 'ac3') AND common_field = 'bb41383';# 3、查看OPTIMIZER_TRACE表SELECT * FROM information_schema.OPTIMIZER_TRACE\G复制
输出内容有点多,我们直接将输出粘贴成代码并加以注释进行解释:
*************************** 1. row ***************************## 要分析的查询语句QUERY: SELECT * FROM table_query_cost WHERE key1 > 'ce' AND key2 < 10000 AND key3 IN ('b88', '6cd', 'ac3') AND common_field = 'bb41383'## 优化的具体过程TRACE: { "steps": [ { "join_preparation": { ## prepare阶段 "select#": 1, "steps": [ { "IN_uses_bisection": true }, { "expanded_query": "/* select#1 */ select `table_query_cost`.`id` AS `id`,`table_query_cost`.`key1` AS `key1`,`table_query_cost`.`key2` AS `key2`,`table_query_cost`.`key3` AS `key3`,`table_query_cost`.`key_part1` AS `key_part1`,`table_query_cost`.`key_part2` AS `key_part2`,`table_query_cost`.`key_part3` AS `key_part3`,`table_query_cost`.`common_field` AS `common_field` from `table_query_cost` where ((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))" } ] } }, { "join_optimization": { ## optimize阶段 "select#": 1, "steps": [ { "condition_processing": { ## 处理搜索条件 "condition": "WHERE", ## 原始搜索条件 "original_condition": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))", "steps": [ { ## 优化器改写:常量传递转换 "transformation": "equality_propagation", "resulting_condition": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))" }, { ## 优化器改写:常量传递转换 "transformation": "constant_propagation", "resulting_condition": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))" }, { ## 优化器改写:移除没用的条件 "transformation": "trivial_condition_removal", "resulting_condition": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))" } ] } }, { ## 替换虚拟生成列 "substitute_generated_columns": { } }, { ## 表的依赖信息 "table_dependencies": [ { "table": "`table_query_cost`", "row_may_be_null": false, "map_bit": 0, "depends_on_map_bits": [ ] } ] }, { "ref_optimizer_key_uses": [ ] }, { ## 预估不同单表访问方法的访问成本 "rows_estimation": [ { "table": "`table_query_cost`", "range_analysis": { "table_scan": { ## 全表扫描的行数以及成本 "rows": 9991, "cost": 2097.3 }, ## 分析可能使用到的索引 "potential_range_indexes": [ { "index": "PRIMARY", ## 主键不可用 "usable": false, "cause": "not_applicable" }, { "index": "uq_key2", ## uq_key2可能被使用 "usable": true, "key_parts": [ "key2" ] }, { "index": "idx_key1", ## idx_key1可能被使用 "usable": true, "key_parts": [ "key1", "id" ] }, { "index": "idx_key3", ## idx_key3可能被使用 "usable": true, "key_parts": [ "key3", "id" ] }, { "index": "idx_key_part", ## idx_key_part不可用 "usable": false, "cause": "not_applicable" } ], "setup_range_conditions": [ ], "group_index_range": { "chosen": false, "cause": "not_group_by_or_distinct" }, ## 分析各种可能使用的索引的成本 "analyzing_range_alternatives": { "range_scan_alternatives": [ { ## 使用uq_key2的成本分析 "index": "uq_key2", ## 使用uq_key2的范围区间 "ranges": [ "NULL < key2 < 10000" ], "index_dives_for_eq_ranges": true, ## 是否使用index dive,是 "rowid_ordered": false, ## 使用该索引获取的记录是否按照主键排序,否 "using_mrr": true, ## 是否使用mrr,是 "index_only": false, ## 是否是索引覆盖访问,否 "rows": 9999, ## 使用该索引获取的记录条数,9999 "cost": 3728.4, ## 使用该索引的成本,3728.4 "chosen": false, ## 是否选择该索引,否 "cause": "cost" ## 因为成本“cost”太大所以不选择该索引 }, { ## 使用idx_key1的成本分析 "index": "idx_key1", ## 使用idx_key1的范围区间 "ranges": [ "ce < key1" ], "index_dives_for_eq_ranges": true, ## 是否使用index dive,是 "rowid_ordered": false, ## 使用该索引获取的记录是否按照主键排序,否 "using_mrr": true, ## 是否使用mrr,是 "index_only": false, ## 是否是索引覆盖访问,否 "rows": 1959, ## 使用该索引获取的记录条数,1959 "cost": 1085.8, ## 使用该索引的成本,1085.8 "chosen": true ## 是否选择该索引,是 }, { ## 使用idx_key3的成本分析 "index": "idx_key3", ## 使用idx_key3的范围区间 "ranges": [ "6cd <= key3 <= 6cd", "ac3 <= key3 <= ac3", "b88 <= key3 <= b88" ], "index_dives_for_eq_ranges": true, ## 同上 "rowid_ordered": false, ## 同上 "using_mrr": true, ## 同上 "index_only": false, ## 同上 "rows": 9, ## 同上 "cost": 12.374, ## 同上 "chosen": true ## 同上 } ], ## 分析使用索引合并的成本 "analyzing_roworder_intersect": { "usable": false, "cause": "too_few_roworder_scans" } }, ## 对于上述单表查询table_query_cost最优的访问方法 "chosen_range_access_summary": { "range_access_plan": { "type": "range_scan", "index": "idx_key3", "rows": 9, "ranges": [ "6cd <= key3 <= 6cd", "ac3 <= key3 <= ac3", "b88 <= key3 <= b88" ] }, "rows_for_plan": 9, "cost_for_plan": 12.374, "chosen": true } } } ] }, { ## 分析各种可能的执行计划 ##(对多表查询这可能有很多种不同的方案,单表查询的方案上边已经分析过了,直接选取idx_key3就好) "considered_execution_plans": [ { "plan_prefix": [ ], "table": "`table_query_cost`", "best_access_path": { "considered_access_paths": [ { "rows_to_scan": 9, "access_type": "range", "range_details": { "used_index": "idx_key3" }, "resulting_rows": 9, "cost": 14.174, "chosen": true } ] }, "condition_filtering_pct": 100, "rows_for_plan": 9, "cost_for_plan": 14.174, "chosen": true } ] }, { ## 尝试给查询添加一些其他的查询条件 "attaching_conditions_to_tables": { "original_condition": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))", "attached_conditions_computation": [ ], "attached_conditions_summary": [ { "table": "`table_query_cost`", "attached": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`key3` in ('b88','6cd','ac3')) and (`table_query_cost`.`common_field` = 'bb41383'))" } ] } }, { ## 再稍稍的改进一下执行计划 "refine_plan": [ { "table": "`table_query_cost`", "pushed_index_condition": "(`table_query_cost`.`key3` in ('b88','6cd','ac3'))", "table_condition_attached": "((`table_query_cost`.`key1` > 'ce') and (`table_query_cost`.`key2` < 10000) and (`table_query_cost`.`common_field` = 'bb41383'))" } ] } ] } }, { "join_execution": { ## execute阶段 "select#": 1, "steps": [ ] } } ]}## 因优化过程文本太多而丢弃的文本字节大小,值为0时表示并没有丢弃MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0## 权限字段INSUFFICIENT_PRIVILEGES: 01 row in set (0.00 sec)复制
从上面的步骤中,优化过程大致分为三个阶段:
prepare阶段。
optimize阶段。
execute阶段。
基于成本的优化主要集中在optimize阶段:
对于单表查询来说:主要关注optimize阶段的"rows_estimation"(预估不同单表访问方法的访问成本)这个过程,这个过程深入分析了对单表查询的各种执行方案的成本。
对于多表连接查询来说:需要关注optimize阶段的"considered_execution_plans"(分析各种可能的执行计划及成本)这个过程,这个过程里会写明各种不同的连接方式所对应的成本。
优化器最终会选择成本最低的那种方案来作为最终的执行计划,也就是我们使用EXPLAIN语句所展现出的那种方案。
小结
 ,大家久等了。公众号还是要继续的,不能忘记:大道至简,贵在坚持 的初心。后面会尽量协调好自己的时间,争取周更。
,大家久等了。公众号还是要继续的,不能忘记:大道至简,贵在坚持 的初心。后面会尽量协调好自己的时间,争取周更。 每天进步一点点!~
每天进步一点点!~参考资料
小孩子4919《MySQL是怎样运行的:从根上理解MySQL》
https://blog.csdn.net/weixin_33549115/article/details/113280583
https://www.cnblogs.com/flzs/p/9974822.html

扫描二维码关注
获取更多精彩
GrowthDBA

end



