




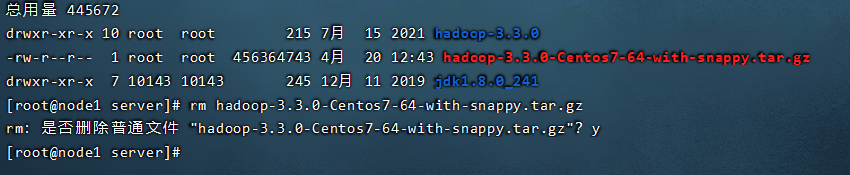
Step3:上传、解压Hadoop安装包
我们只需在node1上面安装hadoop就可以了,但是配置文件配置好之后,需要通过scp指令拷贝到其他主机,安装包hadoop-3.3.0-Centos7-64-with-snappy.tar.gz依然上传到/export/server目录下。
安装包下载 https://www.modb.pro/download/520649
cd /export/server
# 解压安装包
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
Step4:Hadoop安装包目录结构
目录结构说明
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C + +定义的,通常用于C + +程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
在这里我们需要重点关注四个目录:
| bin | etc | sbin | share |
|---|
- bin和sbin目录
bin目录里面都是一些hadoop 的管理脚本在里面,执行具体的管理操作,但是呢,所有的启动和关闭命令不在这里,所有的启动关闭命令,在sbin中。 - etc目录
这里是我们hadoop 的配置文件所在目录,等一下安装的时候,也需要修改里面的配置。 - share目录
这个share目录比较有意思,保存的是各个模块编译后的依赖,并且有官方自带的一些实例,我们可以直接执行去感受hadoop怎么使用。
配置文件概述
官网文档:https://hadoop.apache.org/docs/r3.3.0/
整个hadoop搭建起来,他的配置文件非常的多,但是不是每一个文件都需要去修改,需要了解的大致分为三类,接下来我们一个一个去梳理
| 类型 | 文件 | 备注 |
|---|---|---|
| 1 | hadoop-env.sh | |
| 2 | xxxx-site.xml | site表示的是用户定义的配置,会覆盖default中的默认配置 |
| hdfs-site.xmlhdfs | 文件系统模块配置 | |
| mapred-site.xml | MapReduce模块配置 | |
| yarn-site.xml | yarn模块配置 | |
| 3 | workers |
所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
5.1 编辑Hadoop配置文件
5.1.1 hadoop-env.sh配置
这里面主要做两件事,告诉我java在哪里,指定每个进程运行的一个用户名,直接用vim编辑器打开文件,在文件末尾添加下代码:
#文件最后添加
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5.2 编辑Hadoop配置文件
第二部分一共有四个xml格式的文件,因为hadoop一共有三个核心组件HDFS,YARN,MapReduce,分别对应一个配置文件,另外还有一个叫做core的核心模块,也对应一个配置文件。
5.2.1 core-site.xml配置
这个配置文件里面通常配置一些核心的配置,我们一起来看一下:
- 指定谁来做我们的文件系统,当然,默认支持的文件系统就是HDFS,现在还支持谷歌、阿里云,亚马逊等等。
- 接下来还要设置本地保存数据的路径
- 还有用户的代理
- 垃圾桶的保存时间
这块内容大家可以自己看一下,做一个了解,用vim编辑器打开core-site.xml
找到最下面的configuration之间,复制下面配置进去就可以了。
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
5.2.2 hdfs-site.xml配置
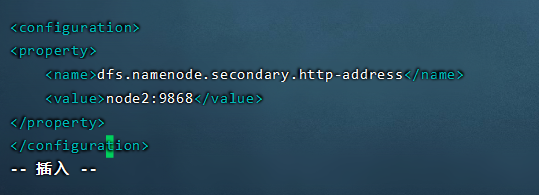
接下来我们看 hdfs-site.xml,这是我们的文件系统的核心配置,这里面只需要我们指定一下我们的Secondary namenode的工作机器位置信息就可以了。打开文件,找到最下面的configuration之间,复制下面配置进去就可以了。
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
5.2.3 mapred-site.xml配置
从名字上看我们差不多可以猜出来,这个就是mapReduce的一个配置文件,里面主要设定了MR的运行模式、历史服务器的地址、包括一些运行的权限,打开文件mapred-site.xml,找到最下面的configuration之间,复制下面配置进去就可以了。
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
5.2.4 yarn-site.xml配置
接下来我们看最后一个配置文件,yarn-site.xml,里面配置yarn的工作地址,对内存的限制等,这里需要把物理内存、虚拟内存的限制关闭掉,原因是我们虚拟机的内存比较小,资源比较穷,如果是真实生产环境中,这两个参数可以去掉,打开文件mapred-site.xml,找到最下面的configuration之间,复制下面配置进去就可以了。
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
5.3 编辑Hadoop配置文件
5.3.1 workers配置
从名字上我们就可以看出,这个配置的就是我们集群的小弟,干活的工人,他们位于机器的IP信息vim workers ,删掉里面的内容,复制下面配置进去就可以了。
node1 node2 node3

到此位置,我们就把hadoop的配置文件配置好了。
Step6:分发同步安装包
到目前为止,我们只做了一台机器的配置,接下来,我们要把配置文件分发到其他机器上去,使用scp指令:
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
Step7:配置Hadoop环境变量
我们想要随意的使用hadoop指令,还需要在我们的主机上添加环境变量
- 在node1上配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 将修改后的环境变量同步其他机器
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
- 重新加载环境变量验证是否生效(3台机器)
source /etc/profile
- 接下来我们就可以使用hadoop指令验证环境变量是否生效了
Step8:NameNode format(格式化操作)
接下来就是我们安装hadoop 的最后一步,如果这一步没有做好,那么之前的工作就前功尽弃了,接下来的工作就是格式化工作,大家看到格式化这个词比较毛,格式化以后啥都没了,其实这应该是一个翻译问题,这个词汇叫做format,与其说是格式化,不如说是初始化,因为在初始启动的时候,我们的文件系统等在物理层面上并不存在,他的一些状态、数据什么的都没有,就需要初始化操作。
但是注意,初始化操作只能进行一次,在我们首次搭建,首次启动之前执行。这里有个坑,千万不要执行多次,会导致集群之间的角色相互不认识,只能把我们的配置文件删除,数据目录删除,重新格式化,这样的问题,在我们的生产环境中,是绝对不能出现的。
执行下面的命令:
hdfs namenode -format
如何判断格式化成功,看下图,数据路径是我们之前配置的路径,自动生成元数据保存的路径等,不用管他
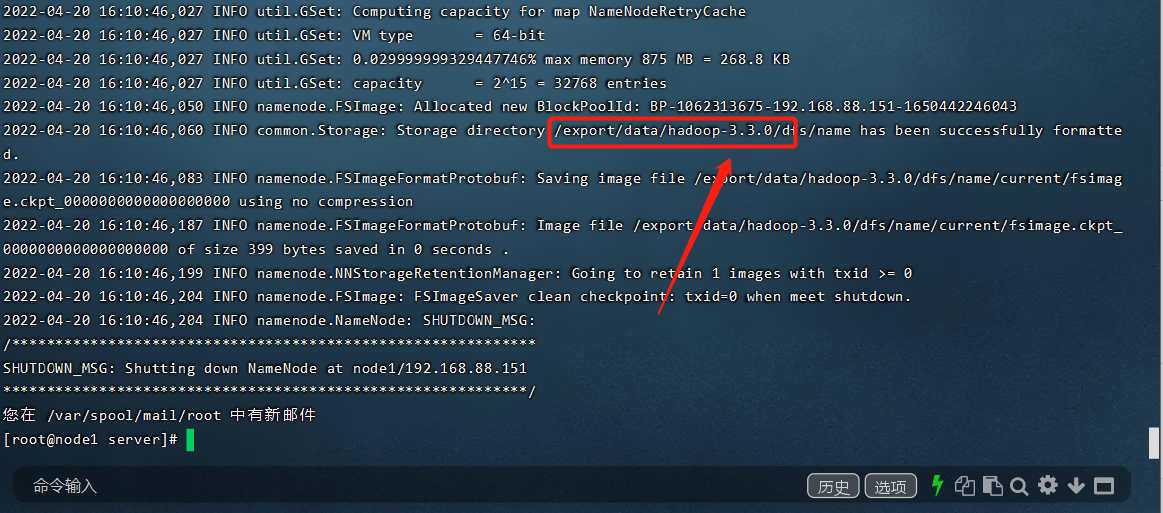
接下来我们就可以愉快的玩耍hadoop了。
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
