




hadoop集群启停命令
接下来我们一起看一下hadoop的启停命令,官方提供了两种启停方式,第一种方式叫做手动逐个进程启停,一听上去就很麻烦,不管你有多少台机器,不管有多少个进程,我们每次只能启动关闭一个进程,如果有1000机器这样启停,我们就费了。
但是它有它的好处,我就可以精准的控制每个进程的生命,避免一个动作叫做群起群停,假如我们工作环境有1000台服务器,其中一个出问题了,我们要关机维护一下,这时候我们没有必要把1000台都关机再启动,谁出问题,关谁维护就可以了。
手动逐个进程启停
每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。这样的启动方式对于我们的hdfs集群和yarn集群,他们命令不一样。
HDFS集群
hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenode
YARN集群
hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager
shell脚本一键启停
手动启动特别的麻烦,只用再特殊的情况下,所以官方提供了一键启动脚本,可以在node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和workers文件。
HDFS集群
start-dfs.sh
stop-dfs.sh
YARN集群
start-yarn.sh
stop-yarn.sh
Hadoop集群
start-all.sh
stop-all.sh
我们在之前的过程中配置好了免密登录,也修改了workers文件,我们就可以使用一键启停。
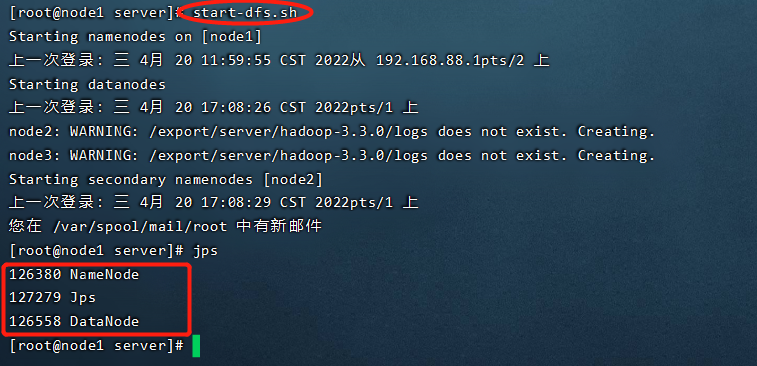
执行 start-dfs.sh
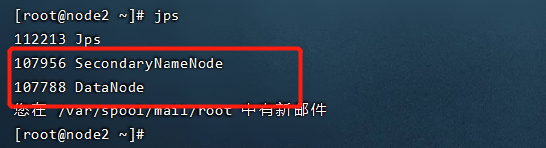
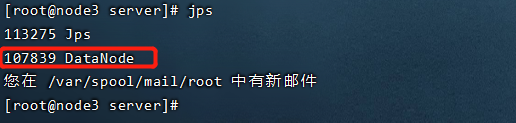
调用指令 jps查看Java进程
node1有两个进程:NameNode,DataNode
node2有两个进程:SecondaryNameNode,DataNode
node3上面有一个进程:DataNode
我们的HDFS集群就启动了,接下来我们启动yarn集群
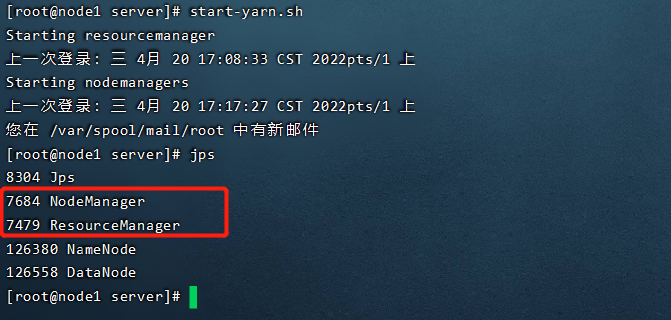
使用start-yarn.sh
调用指令 jps查看Java进程
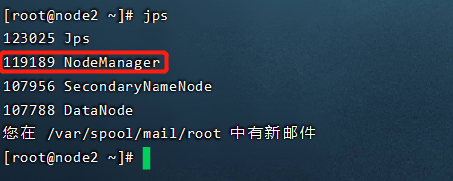
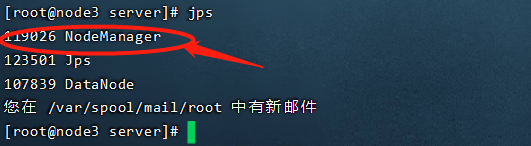
node1多了两个进程:NodeManager,ResourceManager
node2多了一个进程:NodeManager
node3多了一个进程:NodeManager
进程状态、日志查看
启动完毕之后可以使用jps命令查看进程是否启动成功
我们启动集群以后,接下来,就会涉及到一个问题,你怎么样保证你的集群启动是正常的,第一个,我们要使用jps命令查看是否成功,之前我们在配置的时候已经规划了每个机器上的进程。
日志查看
当然了,还有一个现象,就是你会发现有一个进程,一开始查看它的时候它存在,过一会就没了,叫做进程的闪退,那就说明是哪里配置出错了,这时候,我们排错的唯一依据是什么呢,就是看我们的启动日志。hadoop的启动日志写的非常详细。针对每个进程,都有他的启动日志。
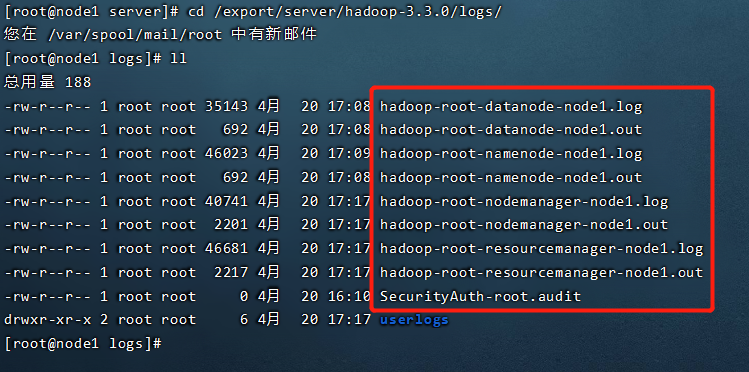
Hadoop启动日志路径
cd /export/server/hadoop-3.3.0/logs/
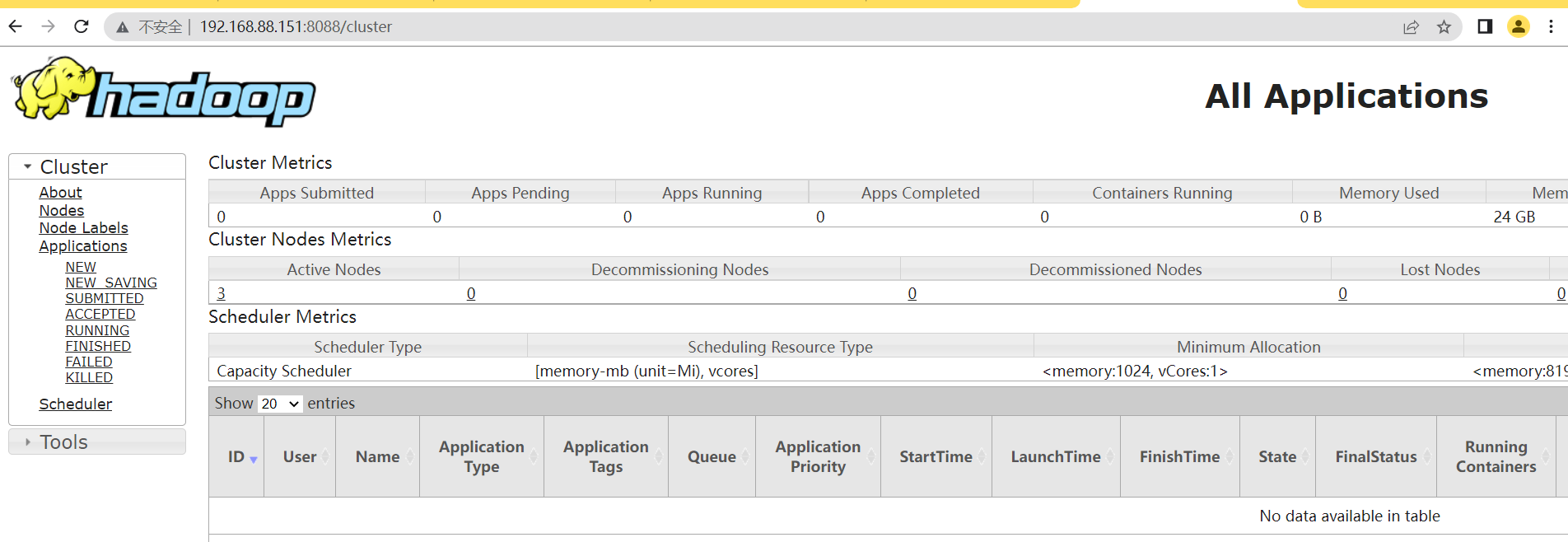
hadoop两个集群的Web UI
毕竟如果都是黑窗口,操作起来非常的不友好,所以官方提供了两个页面.
HDFS集群
地址:http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
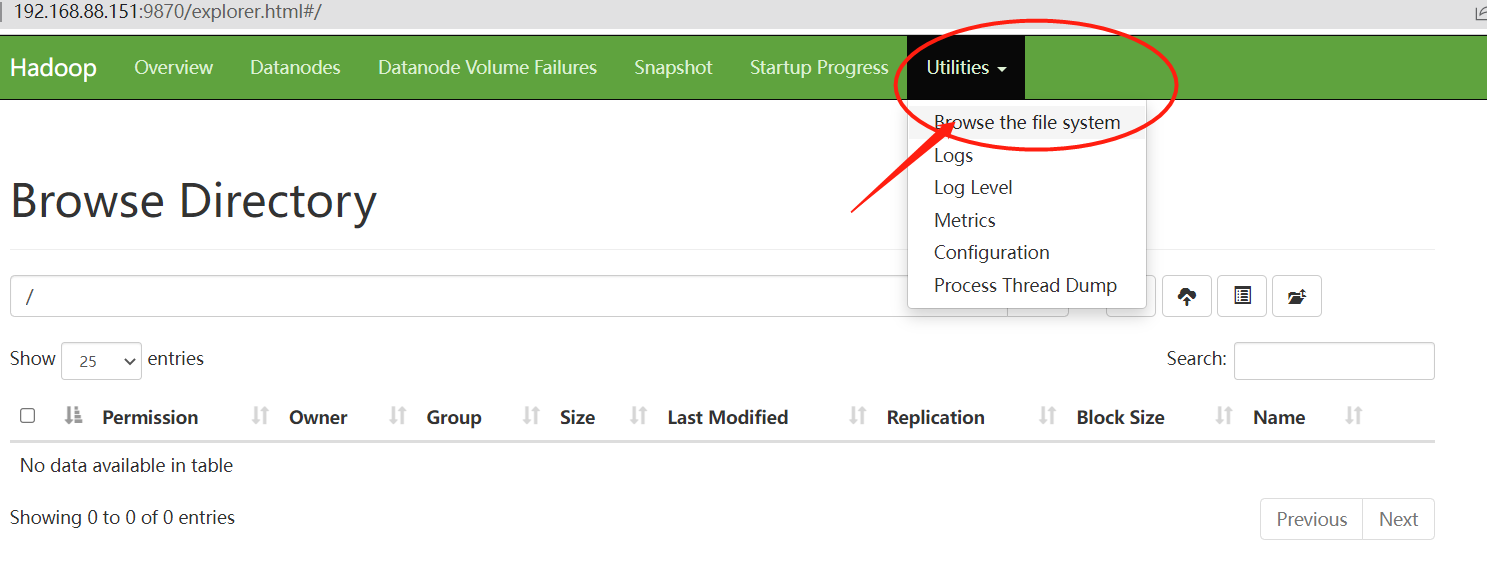
在这个页面我们可以看到集群的主要信息,有多少空间,剩余多少空间,总共存活几个角色等等,但是作为文件系统,最主要的是提供我们的文件浏览功能。这个页面给我们提供了根目录,我们可以操作上传文件等。
YARN集群
当然了,Yarn集群也给我们提供了页面
地址:http://resourcemanager_host:8088
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
这里会显示当前我们有哪些程序正在执行,不仅仅是mapReduce,包括我们的大数据程序比如Spark,Flink等等,这可以帮助我们监控我们程序的资源,包括哪些程序正在跑,跑多长时间,显示hadoop的集群状态等等。
HDFS 初体验
接下来我们一起感受下hadoop各个组件都有什么样的功能,有什么样的特点,比如,HDFS是一个分布式文件系统,他和传统的文件系统有什么区别。
文件系统说白了就是用来文件上传下载的官方提供了很多种方式,比如可以使用它自带的命令进行操作,也可以通过他的web页面进行相关的操作 。
shell命令操作
hadoop fs -mkdir /test # 创建目录
hadoop fs -put zookeeper.out/test # 上传文件
hadoop fs -ls / # 显示目录
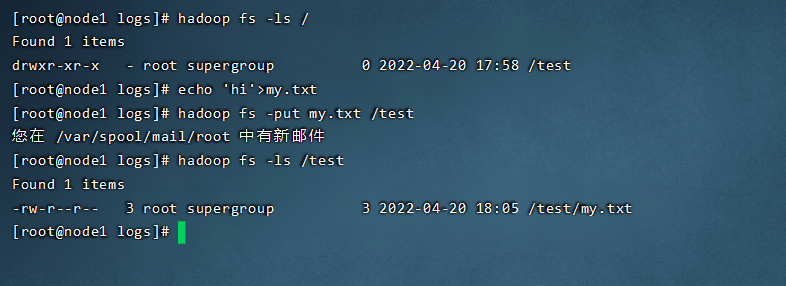
我们可以试着创建一个my.txt文件,然后上传到hdfs文件系统。发现hdfs命令和linux命令非常相似,实际上,hadoop开发的时候就模仿了linux的指令。但是貌似上传效率并不高,等待时间很长。
Web UI页面操作
除了使用命令创建文件,我们还可以在UI界面进行操作,创建文件夹,上传等操作.
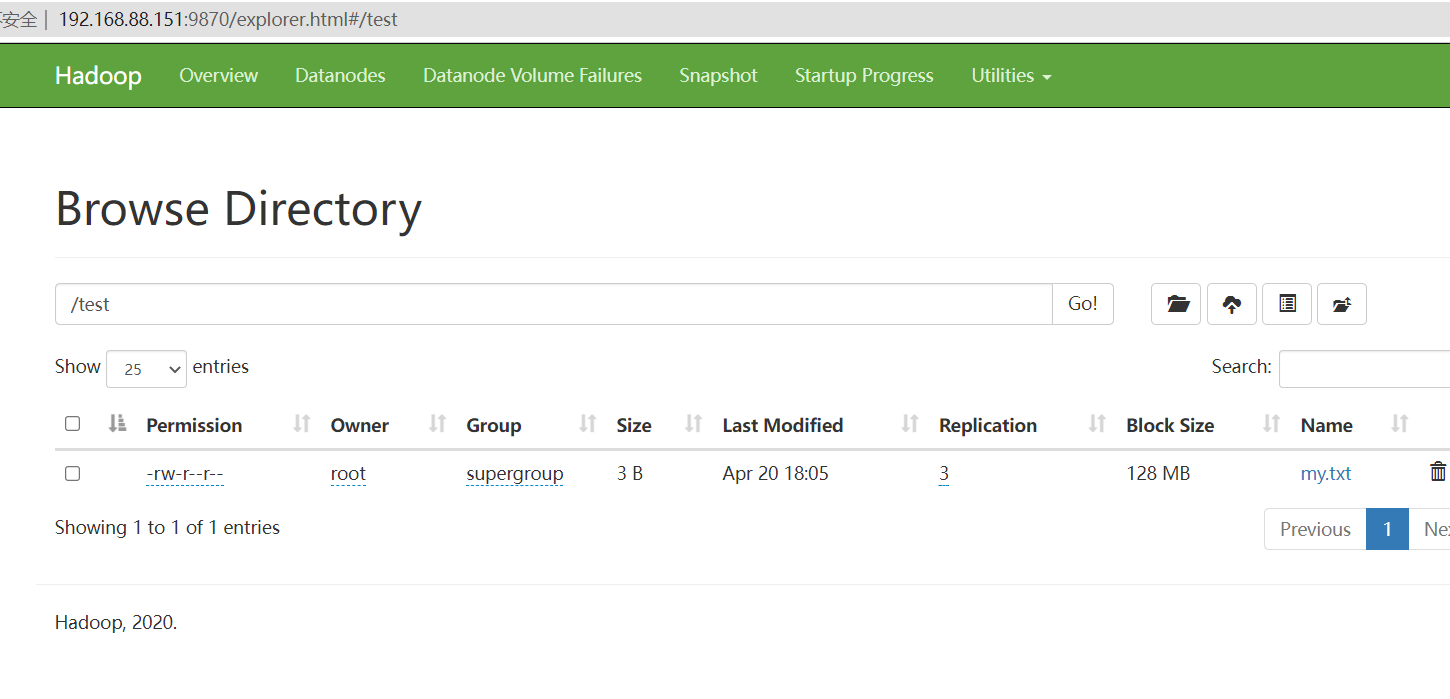
思考的问题
1.HDFS本质就是一个文件系统
2.有目录树结构和Linux类似,分文件、文件夹
3.为什么上传一个小文件也这么慢?
MapReduce+YARN初体验
接下来我们来体验一下MapReduce和YARN组件,为什么要把它们放在一起呢,因为他俩一个是要执行的程序,一个是我们的资源管理系统,我们可以执行Hadoop官方自带的MapReduce案例,评估圆周率π的值。里面具体怎么计算的,我们不用关心,我们重点关心一下MR的执行过程
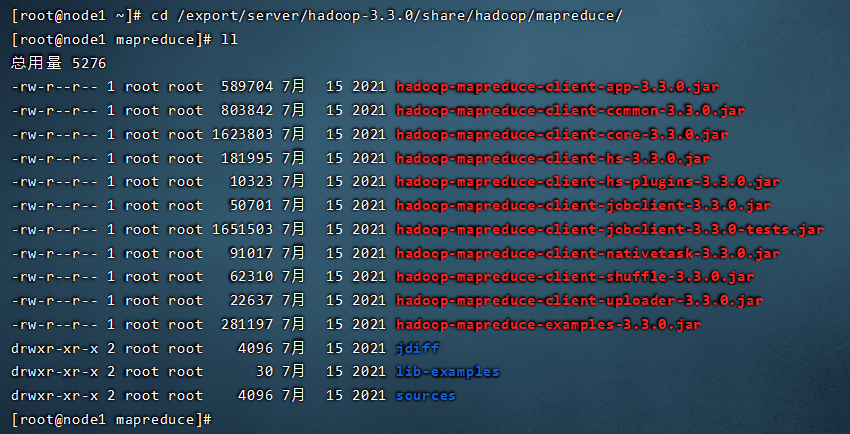
,首先找到我们的安装包目录下的share目录,这里面放着一些官方的示例。
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
在这个目录下我们可以找到hadoop-mapreduce-examples-3.3.0.jar这个示例,hadoop提供的示例很强大,我们一起来运行计算一下圆周率。至于参数怎么提交,后面讲。
示例:计算圆周率
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 4
我们可以重点看一下运行日志第一行,正在连接 ResourceManager, 大家想一下,我作为MR程序,我找YARN干什么呢?因为YARN是管资源的,程序运行要资源,就得找YARN。
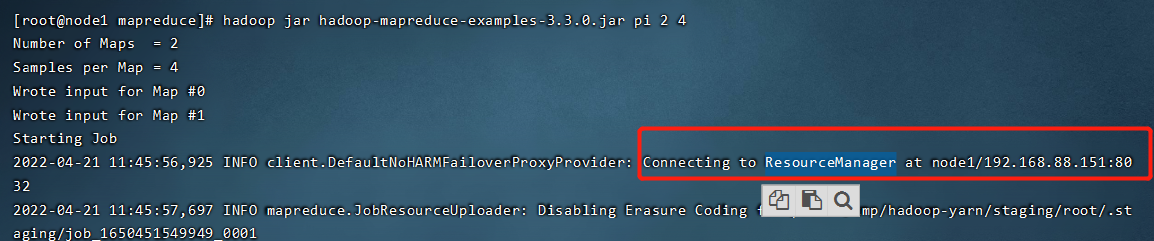
我们接着往下看,会发现,MapReduce好像是两个单词的缩写。Map和Reduce
从执行的进度来看,好像是先执行的map,后执行的reduce

执行完之后,我们可以回到YARN的页面看一下,刷新就会看到一条执行结果,什么时候开始,什么时候结束,执行的是哪个任务,运行了多长时间等等。
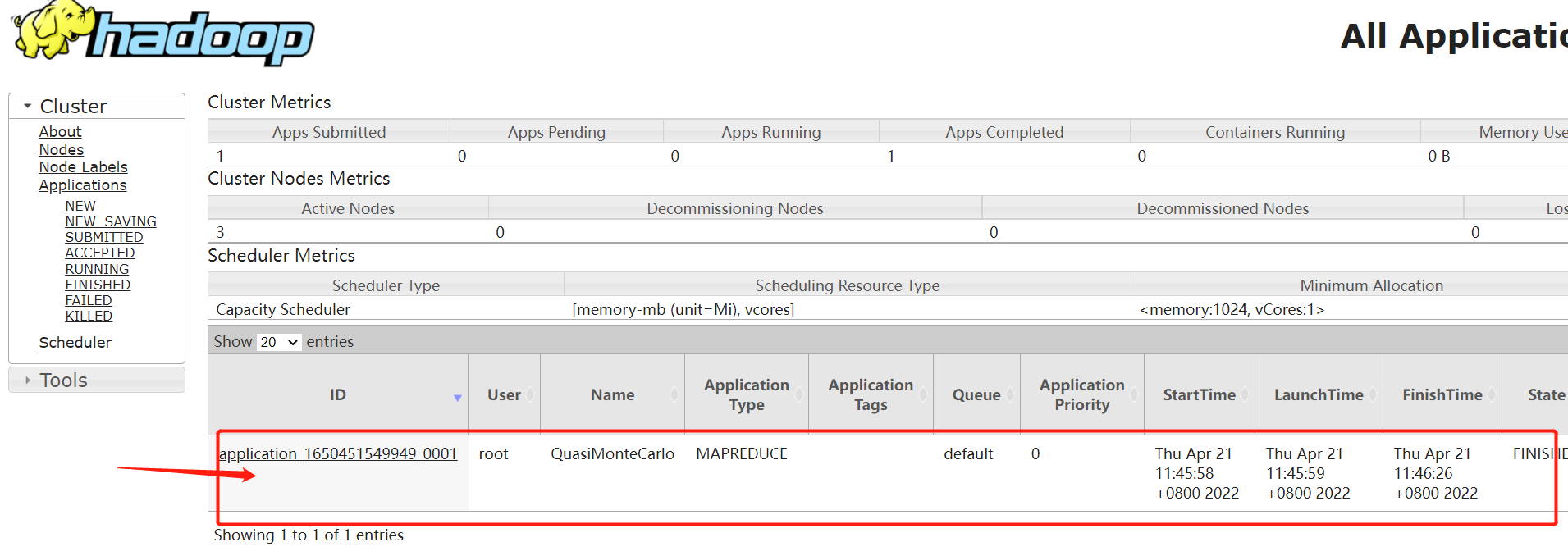
示例:统计文件里每个单词出现的次数
看完计算圆周率的案例后,我们可以按照之前的方法,创建一个小文件,上传到我们的hdfs系统上,然后调用hadoop-mapreduce-examples-3.3.0.jar来测试一下。
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /输入路径 /输出路径
这时候我们发现程序又在执行了,还是链接ResourceManager找Yarn要资源, 在经过map,接着是reduce,最后执行成功,但是这个执行时间非常的长,为什么呢?
思考的问题
1.执行MapReduce的时候,为什么首先请求YARN?
2.MapReduce看上去好像是两个阶段?先Map,再Reduce?
3.处理小数据的时候,MapReduce速度快吗?杀鸡用牛刀?
后面接着聊
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
