




什么是文件系统、分布式文件系统
针对hadoop这款软件的学习,我们通常可以从HDFS这个模块入手,hdfs模块就解决海量数据存储的问题。在大数据的众多问题当中,如果连数据存储问题都没有解决掉,又谈什么各种的分析和计算呢,那么我们一起来看一下,HDFS系统及文件系统有哪些知识,哪些特性,都解决什么问题。
文件系统定义
针对文件系统定义,首先,文件系统本身是一种方法,可以用来存储和组织数据,我们的数据其实底层都是放在我们的硬盘磁盘设备上,但是作为用户,我们不需要关心这么底层,因为文件系统都会给我们准备一个抽象的目录树结构。
比如windows系统就可以看到磁盘上有哪些文件,有哪些子文件夹,有哪些文件,用户只要对这些抽象的概念进行增删改查,到底底层是怎么维护这些数据的,它具体存在哪个位置上,这些都有我们的文件系统帮我们完成,文件系统让用户访问文件、查找文件变的更加容易。
- 文件系统是一种存储和组织数据的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户对文件访问和查找变得容易;
- 文件系统使用树形目录的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘哪里,只需要记住这个文件的所属目录和文件名即可;
- 文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。
传统常见的文件系统
所谓传统常见的文件系统更多指的的单机的文件系统,也就是底层不会横跨多台机器实现。比如windows操作系统上的文件系统、Linux上的文件系统、FTP文件系统等等。
这些文件系统的共同特征包括:
- 带有抽象的目录树结构,树都是从/根目录开始往下蔓延;
- 树中节点分为两类:目录和文件;
- 从根目录开始,节点路径具有唯一性。
数据、元数据
在文件系统中,有两个概念非常重要,一个叫做数据,一个叫做元数据。我们单独提出来讲。
数据
数据指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
元数据
元数据(metadata)是一个新鲜的概念,又称之为解释性数据,记录数据的数据;描述性数据,说白了,他会记录数据的属性、状态、位置信息
- 元数据用来描述数据。
- 比如说,针对文件系统的元数据,一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
数据存储遇到的问题
从上面看来,文件系统没有什么问题,那为什么会出现分布式文件系统呢?原因就是我们当下的时代面临着数据大爆炸,传统的单机版的文件系统,还能支撑吗?传统的文件存储系统会面临哪些挑战呢?
其实,最大的挑战就是一台机器放不下怎么办。接下来我们数据一下目前传统文件系统遇到的问题。
成本高
当我们的一台机器数据存满了之后,我们本能反应是什么呢,就是内存不够加内存,硬盘不够加硬盘,但是这种不断的升级扩容成本很高的,你把一台服务器打造成超级服务器,你的花多少钱呢,这可能就是指数增长了。
无法高效率计算
遇到的第二个问题就是我们传统的文件系统,无法支撑高效率的计算分析,传统上面,存储是存储,程序是程序,当你需要计算的时候,先把数据读到内存,现在的问题是,你的数据达到硬盘都放不下了,就不考虑计算的问题,就移动过来需不需要时间。
我们就考虑能不能让我们的数据不动,而把我们的程序发过去执行呢,但是问题时,现在的数据属于不同的技术厂商实现,无法有机统一整合在一起,怎么感知我要运行的数据在哪里,传统文件系统没有这个功能。
性能低
数据多了之后,高并发场景很多,单节点I/O性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景。
可扩展性差
无法实现快速部署和弹性扩展,动态扩容、缩容成本高,技术实现难度大。我们传统的文件系统面临大数据时候非常非常大的挑战。
思考
当遇到海量数据存储的场景,传统的文件系统如何解决海量数据的存储问题?
一款能够支撑海量数据存储的系统需要追求什么?吞吐量?性能?安全?效率?
如果让你设计一款存储系统软件来支撑海量数据存储,如何设计?
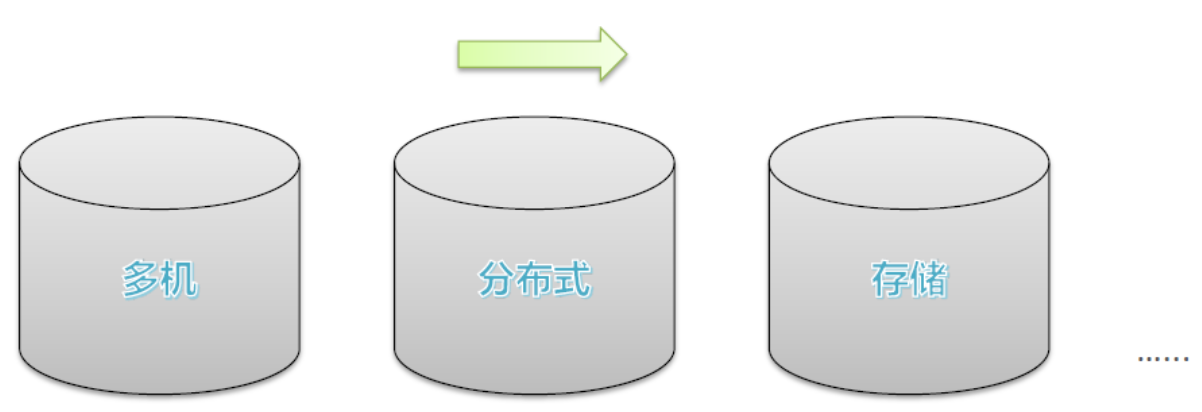
答案就是,用多台机器解决,就叫做分布式
分布式存储系统的核心属性及功能含义
分布式存储系统核心属性
- 分布式存储
- 元数据记录
- 分块存储
- 副本机制
分布式存储的优点
问题:数据量大,单机存储遇到瓶颈,存不下怎么办?
解决:方案有两种,
- 单机纵向扩展:磁盘不够加磁盘,把电脑打造成超级计算机,但是有上限瓶颈限制

- 多机横向扩展:机器不够加机器,理论上无限扩展
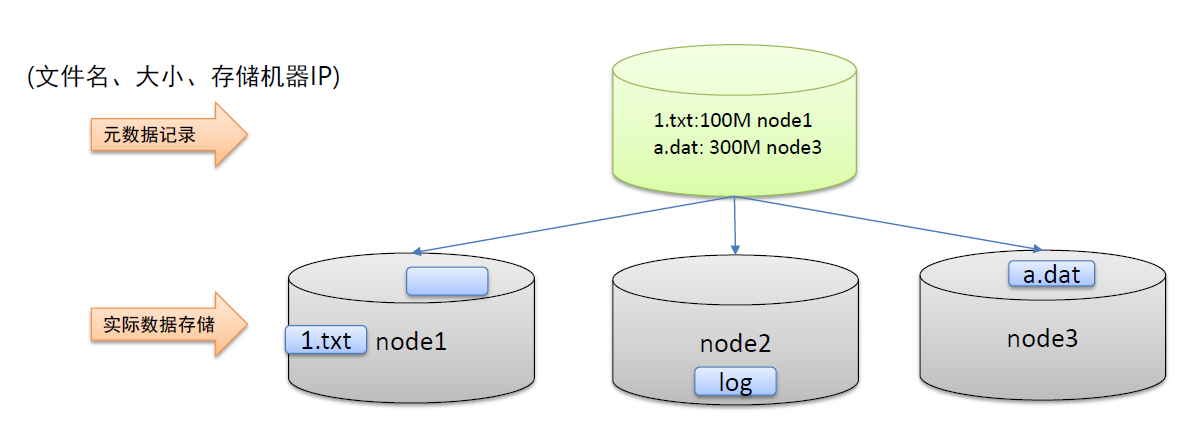
元数据记录的功能
问题:文件分布在不同机器上,找不到怎么办
有朋友就会说,我一台一台的去翻,我一定能找到,那如果是1000台,10000台,运气好第一台就可以找得到,运气不好,翻到1000台,黄花菜都凉了。

解决:其实我们可以通过一台服务器, 记录一些信息,比如把文件切成了几块,文件多大,每块放在那台机器上了,这种记录数据的数据,就是元数据,通过这样,我们只需要查找元数据,就可以精准的找到数据存放在哪里。就好比去图书馆一样。
用户先查找元数据
再定位文件位置
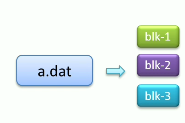
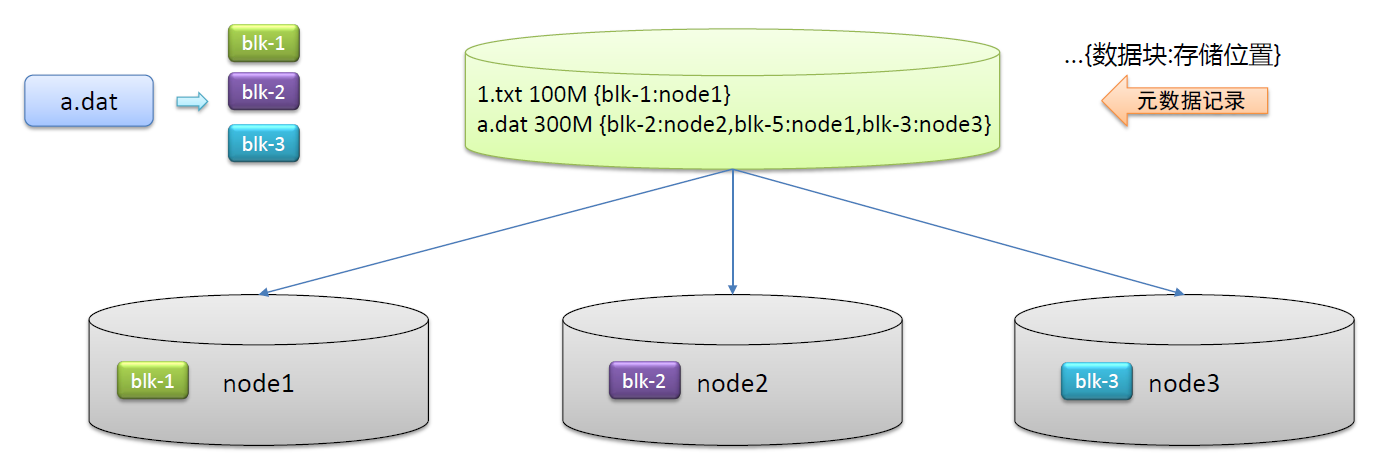
分块存储好处
问题:文件过大导致单机存不下、上传下载效率低
解决:分块存储在不同机器,针对块并行操作提高效率
把文件切成小块,元数据记录就要升级,记录具体有几块,每块多大,存在那。
每个小块就可以同时操作,提高操作效率。
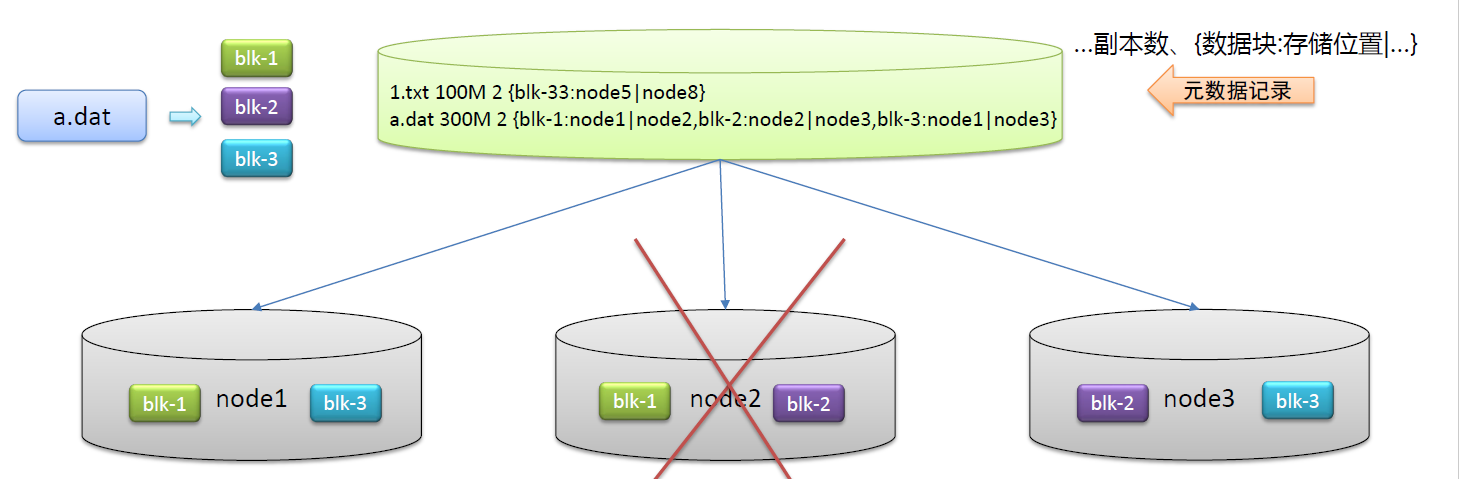
副本机制的作用
问题:硬件故障难以避免,数据易丢失
解决:不同机器设置备份,冗余存储,保障数据安全
我们可以在不同节点备份数据,当其中一个节点挂掉,可以从其他节点恢复过来。
灵魂四问
- 分布式存储的优点是什么?无限扩展支撑海量数据存储
- 元数据记录的功能是什么?快速定位文件位置便于查找
- 文件分块存储好处是什么?针对块并行操作提高效率
- 设置副本备份的作用是什么?冗余存储保障数据安全
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
