





实验环境
- Kafka 中的数据来自于捕获的 PostgreSQL 14.2 的变更数据,参考文章:在Docker环境上使用Debezium捕获PostgreSQL 14.2中的变更数据到Kafka
- 准备 Kafka Connect JDBC Connector(连接器),本实验使用的版本是 10.4.1,下载地址:https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
- 准备 Oracle jdbc 驱动,Kafka Connect JDBC Connector 里面包含了 Oracle jdbc 驱动(ojdbc8-19.7.0.0.jar),如果想使用新版的驱动,也可以自行下载,下载地址:https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/
启动 Oracle 19C 数据库,创建一个测试用户
参考文章:使用Docker装一个Oracle 19C的单机测试环境
# sqlplus sys/oracle@192.168.0.40:1521/pdbtt as sysdba
SQL> create user inventory identified by inventory;
SQL> grant connect,resource,create view to inventory;
SQL> grant unlimited tablespace to inventory;
配置 JDBC Sink Connector
上传驱动和JDBC连接器
将下载的 Oracle JDBC 驱动和 Kafka Connect JDBC Connector(连接器) 上传服务器并复制到 connect 容器中
[root@docker ~]# ls -lrt
-rw-r--r--. 1 root root 4458107 Apr 17 22:12 ojdbc8-19.14.0.0.jar
-rw-r--r--. 1 root root 20208429 Apr 17 22:12 confluentinc-kafka-connect-jdbc-10.4.1.zip
# 上传 Oracle JDBC 驱动,如果使用 Kafka Connect JDBC Connector 自带的驱动可以忽略此处
docker cp ojdbc8-19.14.0.0.jar connect:/kafka/libs
# 上传 Kafka Connect JDBC Connector
unzip confluentinc-kafka-connect-jdbc-10.4.1.zip
chown -R 1001:1001 confluentinc-kafka-connect-jdbc-10.4.1
docker cp confluentinc-kafka-connect-jdbc-10.4.1 connect:/kafka/connect
# 重启 Kafka Connect 连接器
docker restart connect
查看现有连接器信息
- 安装 jq,用于格式化 JSON 格式
yum install -y wget wget https://mirrors.aliyun.com/epel/epel-release-latest-7.noarch.rpm rpm -ivh epel-release-latest-7.noarch.rpm yum install -y jq
- 查看当前存在哪些连接器
curl -s localhost:8083/connectors/ | jq

- 查看连接器的具体信息
curl -s localhost:8083/connectors/snapshot-mode-initial | jq
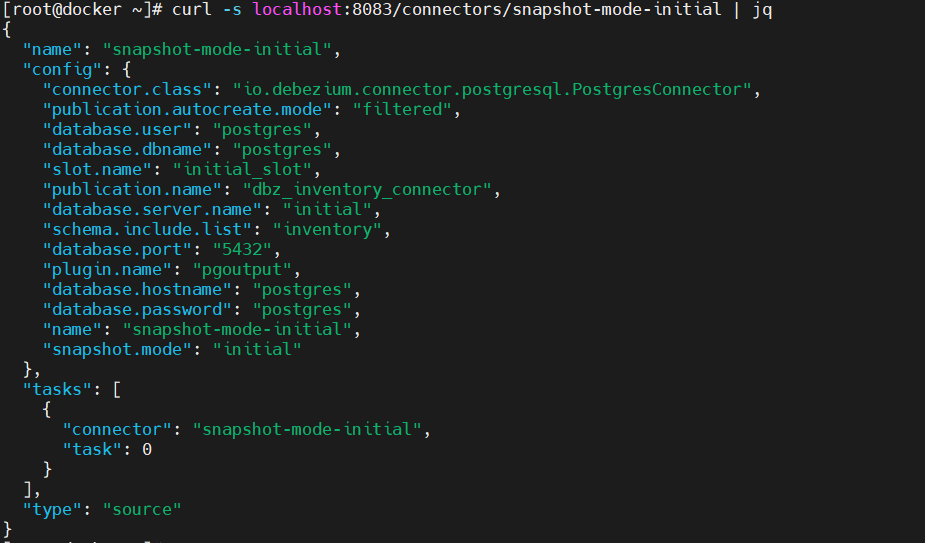
配置连接目标端 Oracle 19C PDB 的连接器
- 查看下目标端 Oracle 容器的IP地址
[root@docker ~]# docker inspect ora19c |grep IPAddress
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.2",
"IPAddress": "172.17.0.2",
- 编辑一个 JSON 文件,配置连接器信息
JDBC Sink Connector Configuration Properties: https://docs.confluent.io/kafka-connect-jdbc/current/sink-connector/sink_config_options.html#sink-config-options
[root@docker ~]# vi oracle-jdbc-sink.json
{
"name": "oracle-jdbc-sink",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:oracle:thin:@//172.17.0.2:1521/pdbtt",
"connection.user": "inventory",
"connection.password": "inventory",
"tasks.max": "1",
"topics": "initial.inventory.orders",
"table.name.format": "orders",
"dialect.name": "OracleDatabaseDialect",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"auto.create": "true",
"auto.evolve": "true"
}
}
- 向 Kafka 连接器注册 JDBC Sink Connector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" 192.168.0.40:8083/connectors/ -d @oracle-jdbc-sink.json
查看已注册的连机器信息
# 当前已注册的连接器
curl -s localhost:8083/connectors/ | jq
# 连接器的具体信息
curl -s localhost:8083/connectors/oracle-jdbc-sink | jq
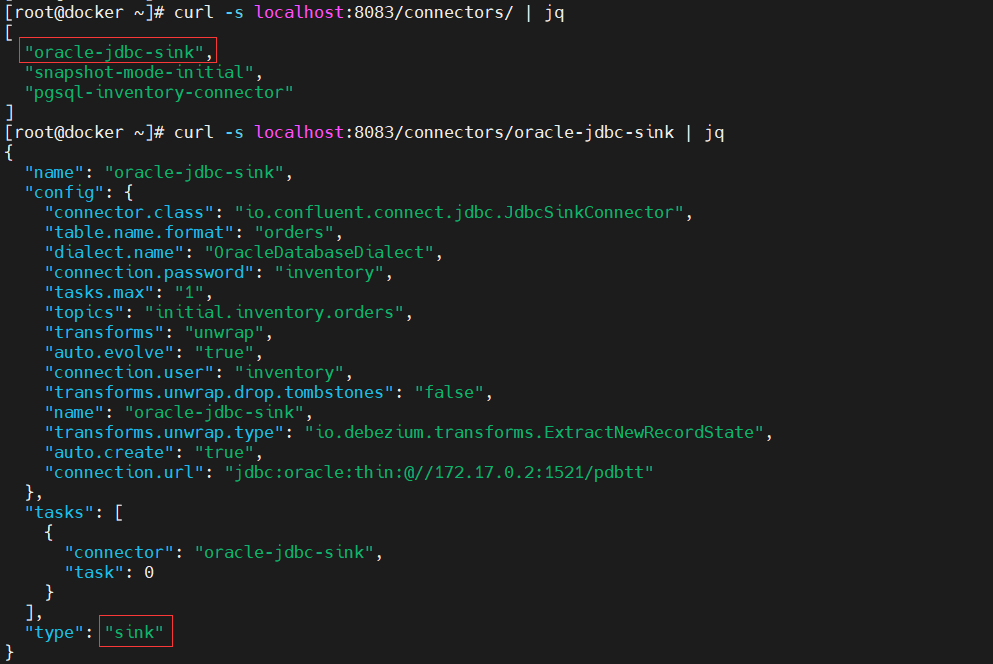
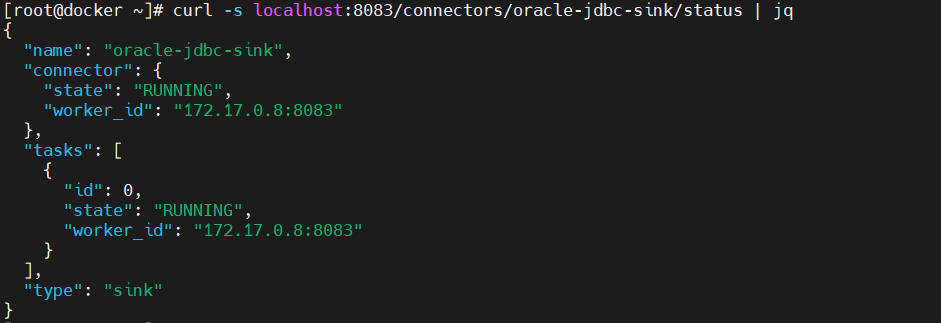
- 查看连接器的运行状态
curl -s localhost:8083/connectors/oracle-jdbc-sink/status | jq
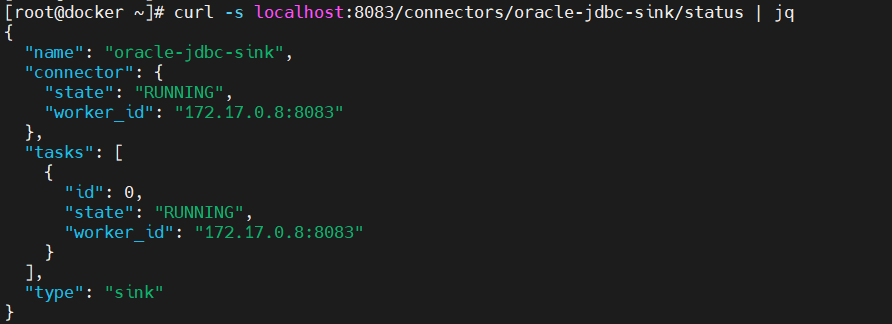
遇到第一个问题,但是这个问题是由方法解决的,后面再说吧
- 向 Kafka 连接器注册 JDBC Sink Connector 之后,连接器会自动连接到 Oracle PDB 上建表插入数据,但是自动建的表名上带有双引号,强制将表名转为了小写。

- 查看 Oracle PDB 表中的数据
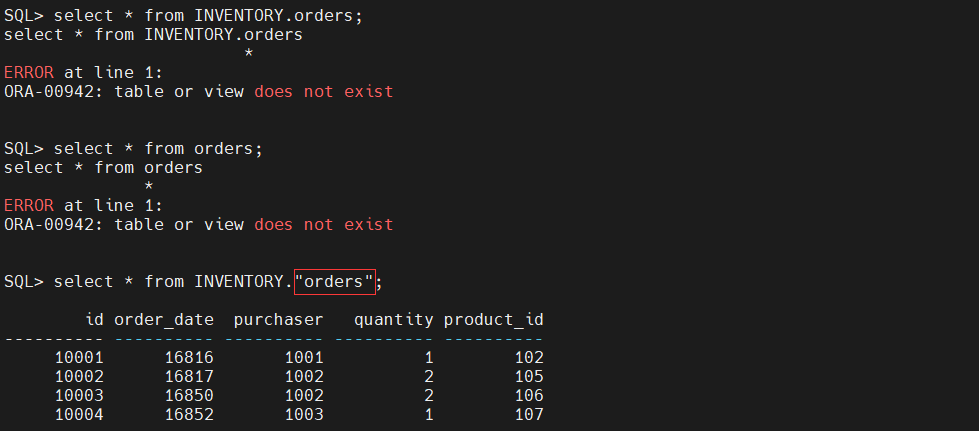
验证目标端的数据
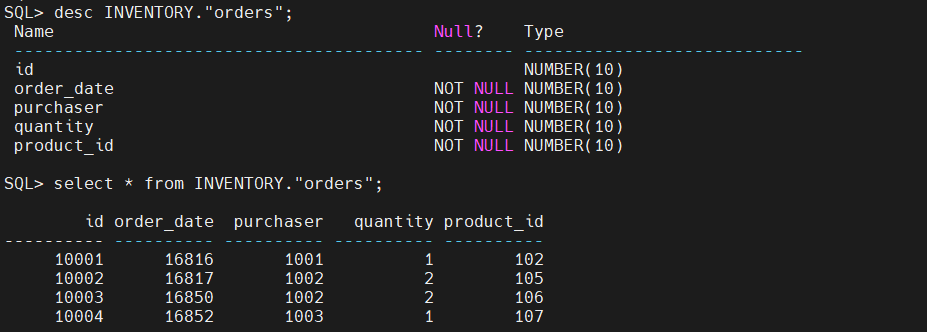
Oracle 端模拟业务
- INSERT
postgres=# select * from inventory.orders;
id | order_date | purchaser | quantity | product_id
-------+------------+-----------+----------+------------
10001 | 2016-01-16 | 1001 | 1 | 102
10002 | 2016-01-17 | 1002 | 2 | 105
10003 | 2016-02-19 | 1002 | 2 | 106
10004 | 2016-02-21 | 1003 | 1 | 107
(4 rows)
postgres=# insert into inventory.orders values (11001,now(),1003,1,102);
INSERT 0 1
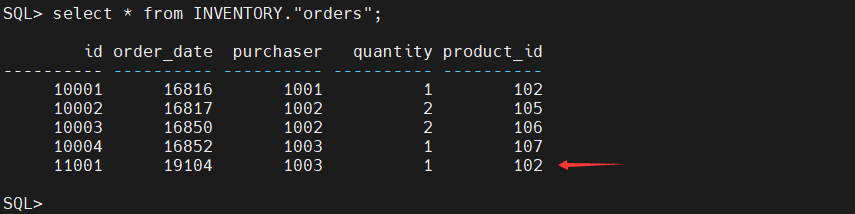
- UPDATE
postgres=# select * from inventory.orders;
id | order_date | purchaser | quantity | product_id
-------+------------+-----------+----------+------------
10001 | 2016-01-16 | 1001 | 1 | 102
10002 | 2016-01-17 | 1002 | 2 | 105
10003 | 2016-02-19 | 1002 | 2 | 106
10004 | 2016-02-21 | 1003 | 1 | 107
11001 | 2022-04-22 | 1003 | 1 | 102
(5 rows)
postgres=# update inventory.orders set quantity=2 where id=11001;
UPDATE 1

- DELETE
postgres=# select * from inventory.orders;
id | order_date | purchaser | quantity | product_id
-------+------------+-----------+----------+------------
10001 | 2016-01-16 | 1001 | 1 | 102
10002 | 2016-01-17 | 1002 | 2 | 105
10003 | 2016-02-19 | 1002 | 2 | 106
10004 | 2016-02-21 | 1003 | 1 | 107
11001 | 2022-04-22 | 1003 | 2 | 102
(5 rows)
postgres=# delete from inventory.orders where id = 11001;
DELETE 1
遇到第二个问题,不同步 DELETE 操作
-
源端 PostgreSQL 执行 DELETE 操作,发现目标端 Oracle 没有同步执行 DELETE 操作,查看 Kafka Connect 日志发现这是有参数限制的呀
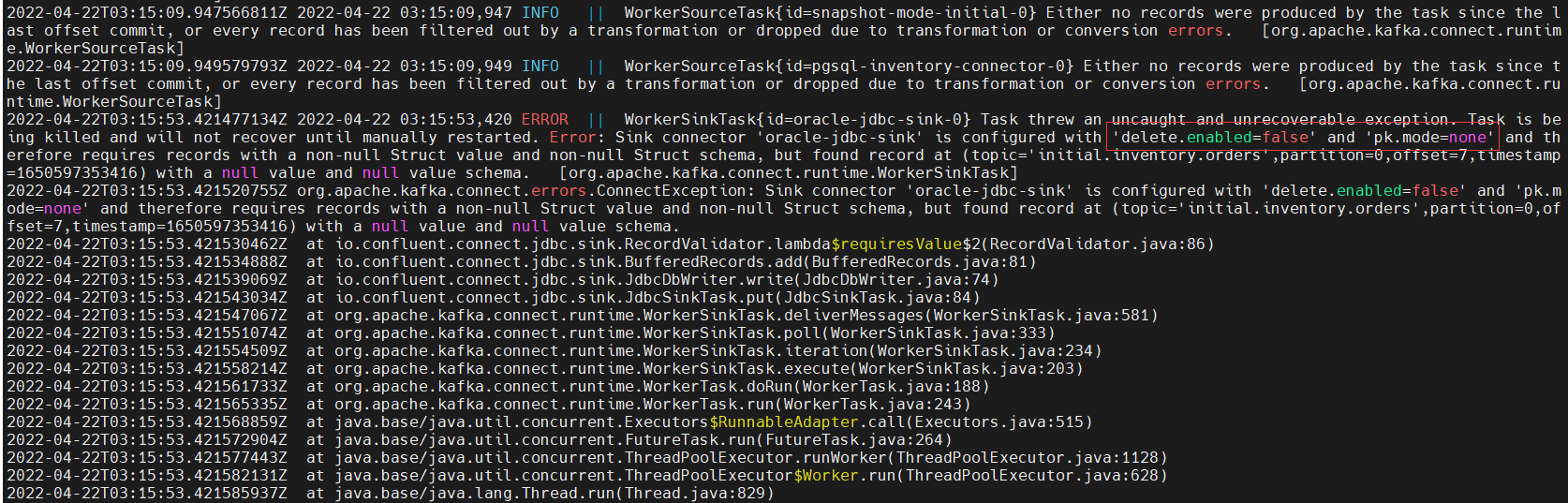
tasks 也失败了
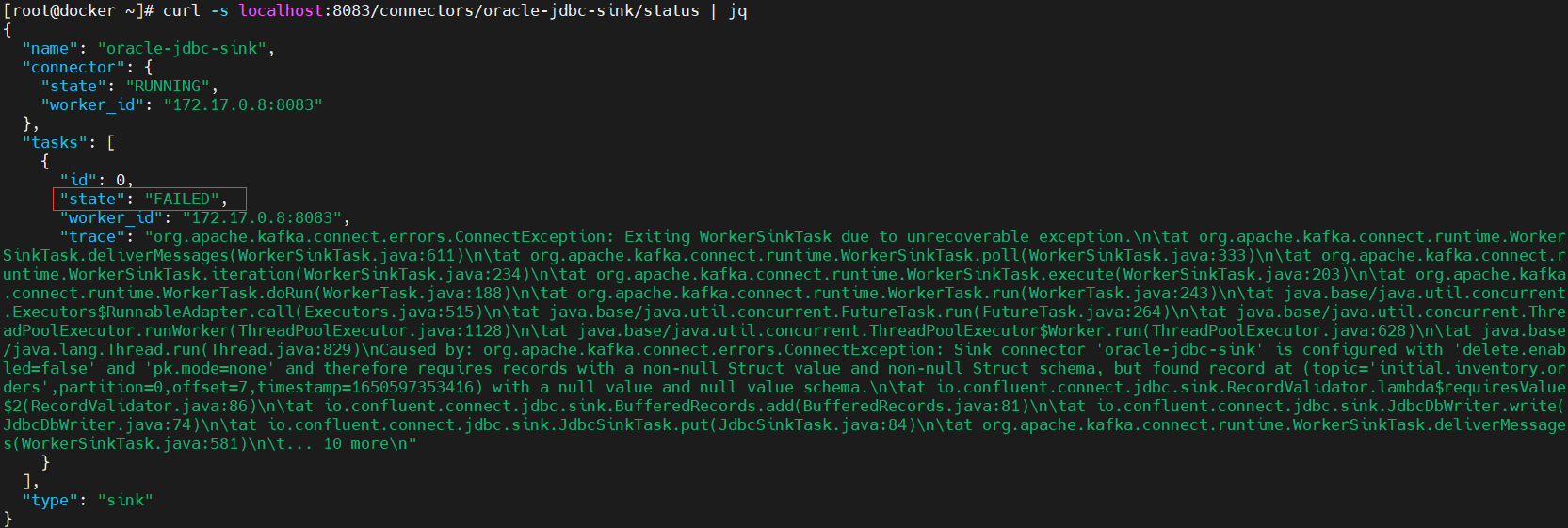
-
更新 sink 连接器,配置 delete.enabled 和 pk.mode
[root@docker ~]# vi oracle-jdbc-sink_update.json
{
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:oracle:thin:@//172.17.0.2:1521/pdbtt",
"connection.user": "inventory",
"connection.password": "inventory",
"tasks.max": "1",
"topics": "initial.inventory.orders",
"table.name.format": "orders",
"dialect.name": "OracleDatabaseDialect",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"auto.create": "true",
"auto.evolve": "true",
"delete.enabled": "true",
"pk.mode": "record_key"
}
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/oracle-jdbc-sink/config -d @oracle-jdbc-sink_update.json
tasks 恢复正常
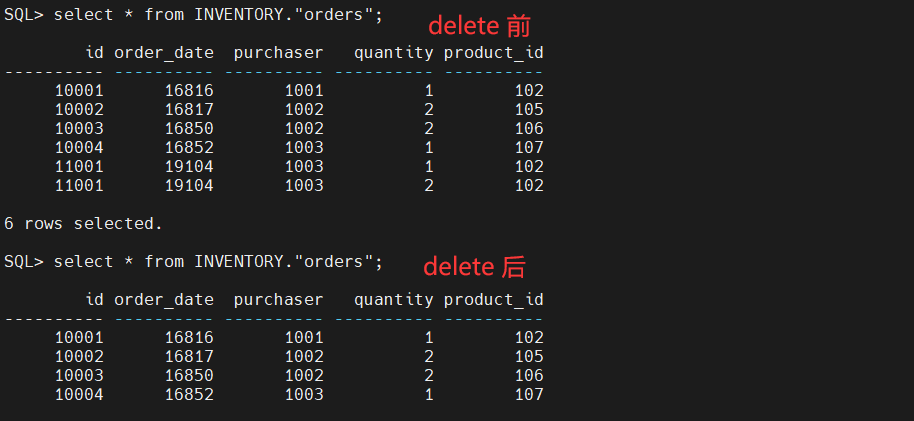
DELETE 操作也同步到目标端
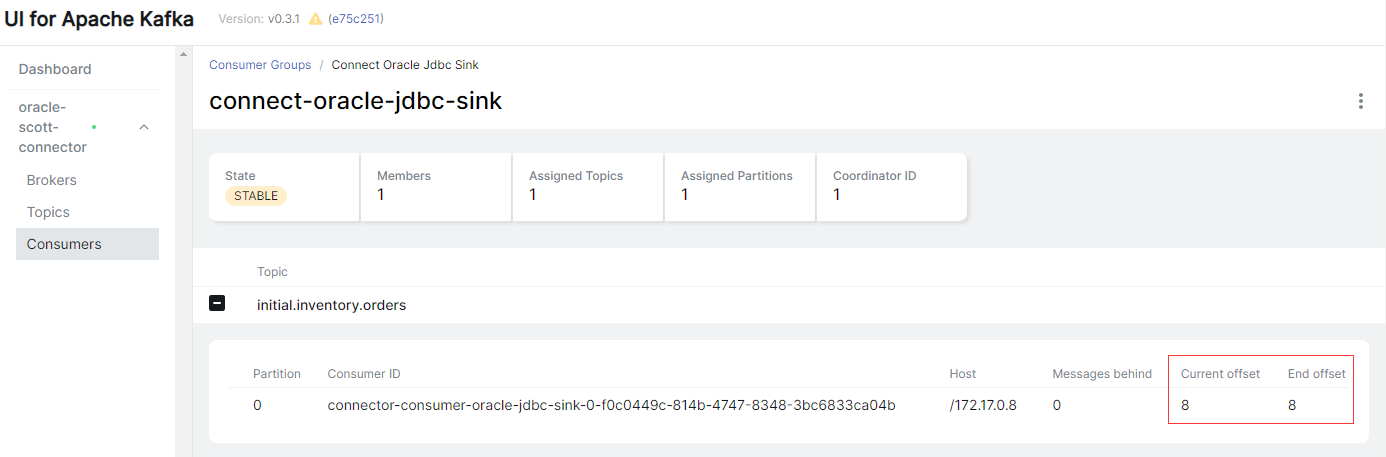
查看消费者组
最后修改时间:2022-04-27 16:18:06
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
