




整体概述
hdfs系统用起来简单方便,但是作为分布式系统,他的重要特性,我们要把握清楚,主要特性如下图
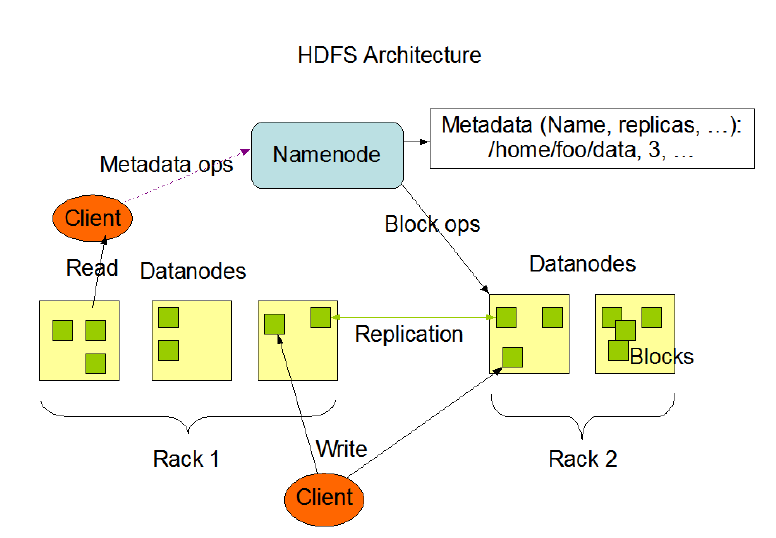
- 主从架构:图中有一个NameNode主节点,带着5个DataNode小弟,图中的rack,代表着机柜。
- 分块存储:图中绿色的小方块block,代表着数据,他是分块存储机制
- 副本机制:小方块和小方块之间,会有一个replixation,也就是副本
- 元数据记录:元数据在namenode上记录了大文件的名称,分了几块,存在哪里等
- 抽象统一的目录树结构(namespace):看起来和linux文件系统一样
(1)主从架构
一个大哥,带领各个小弟去干活,大哥就是master,小弟就是slave,各司其职,共同配合。
- HDFS集群是标准的master/slave主从架构集群。
- 一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
- Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
- 官方架构图中是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上。
(2)分块存储
这里的分块,是真的把文件给切开了,一个大蛋糕,切成小块放冰箱。
- HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。
- 块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。
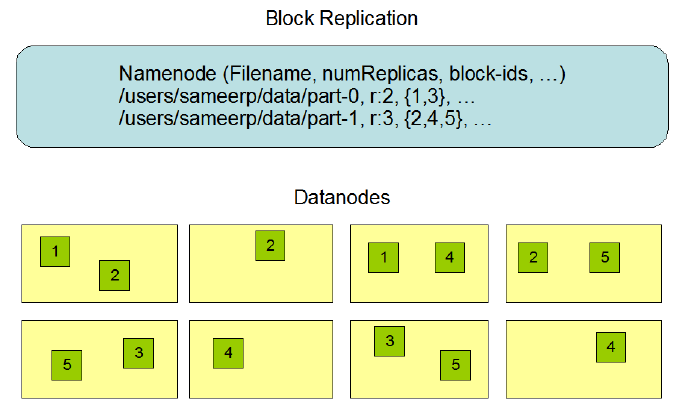
(3)副本机制
蛋糕切开保存以后,为了防止发霉,要创建副本,存进不同的冰箱,默认创建额外2个副本,加自己一共三个。
- 文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
- 副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本,参数位于hdfs-default.xml中。
(4)元数据管理
在HDFS中,Namenode管理的元数据matadata具有两种类型:
- 文件自身属性信息:
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。

- 文件块位置映射信息:
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
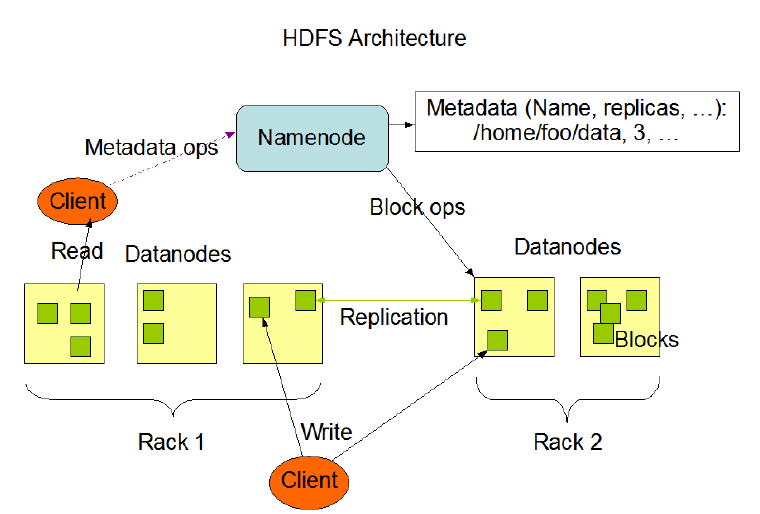
(5)namespace
层次结构由大哥维护
- HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
- Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
- HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
(6)数据块存储
具体的数据块由小弟存储
- 文件的各个block的具体存储管理由DataNode节点承担。
- 每一个block都可以在多个DataNode上存储。
HDFS shell操作
接下来一起来看一下,怎么样使用hdfs的shell命令去操作我们的文件。以及当中这些参数路径写不写有什么区别,我们想搞清楚几个概念。
- 命令行界面(英语:command-line interface,缩写:CLI),是指用户通过键盘输入指令,计算机接收到指令后,予以执行一种人际交互方式。
- Hadoop提供了文件系统的shell命令行客户端: hadoop fs [具体的参数]
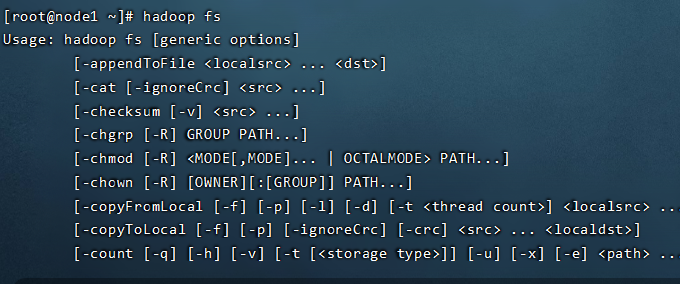
文件系统协议
因为hadoop支持hdfs文件系统,支持goole等多种文件系统,我们在操作的时候怎么区别操作的是那种文件系统,取决于他的前缀协议怎么写的。
- HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file:///)、分布式文件系统(hdfs://nn:8020)等
- 具体操作的是什么文件系统取决于命令中文件路径URL中的前缀协议。
- 如果没有指定前缀,则将会读取环境变量中的fs.defaultFS属性,以该属性值作为默认文件系统。
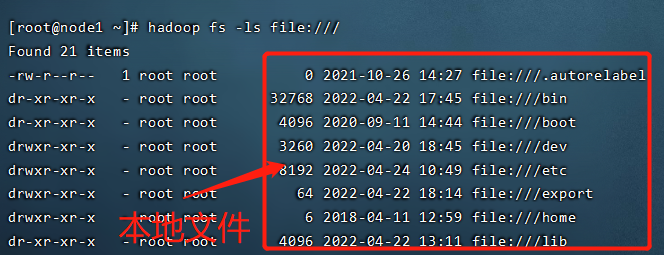
hadoop fs -ls file:/// #操作本地文件系统
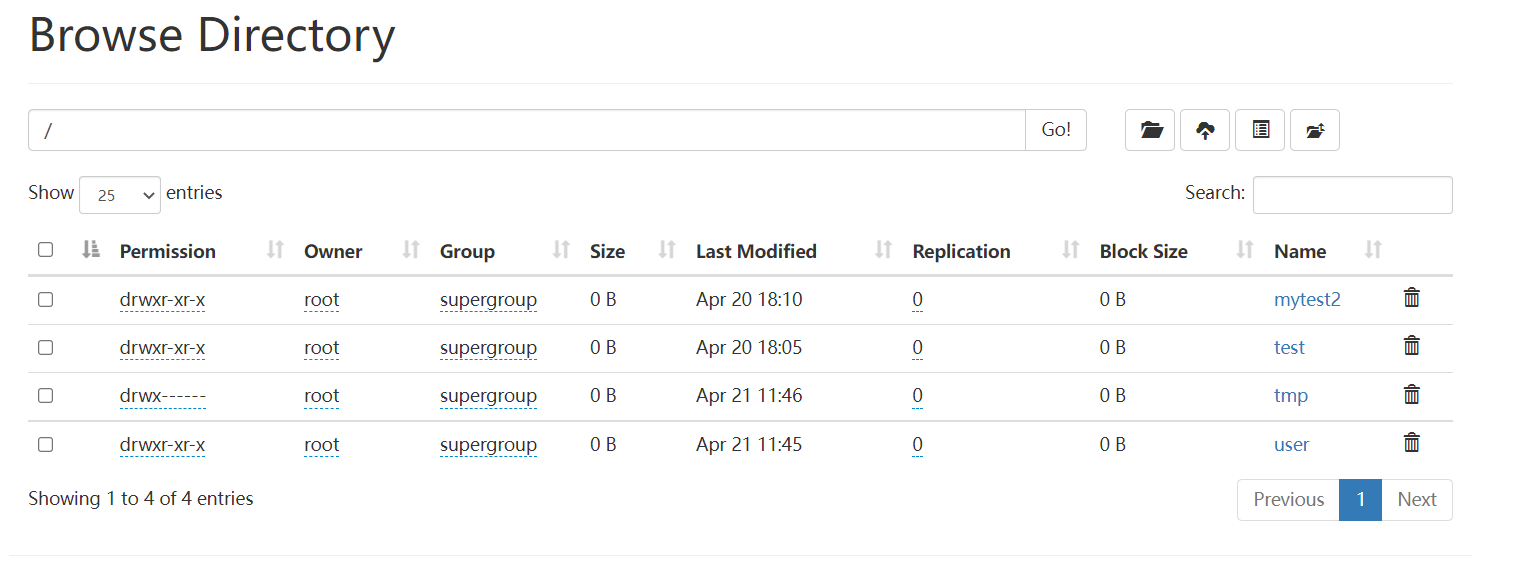
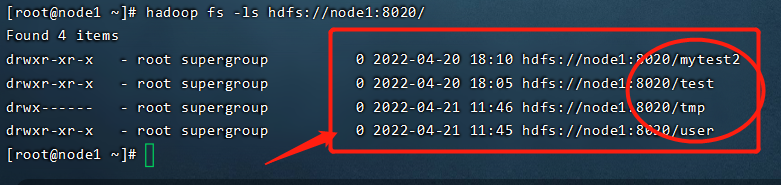
hadoop fs -ls hdfs://node1:8020/ #操作HDFS分布式文件系统
hadoop fs -ls / #直接根目录,没有指定协议将加载读取fs.defaultFS值
cat core-site.xml
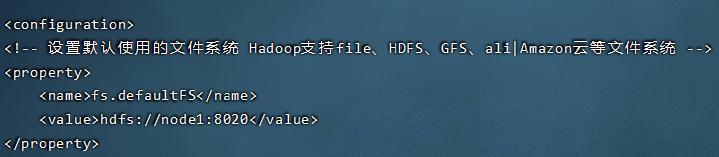
区别
hadoop发展到现在,出现了好多版本,好多指令,官方最终引导使用最新版
- hadoop dfs 只能操作HDFS文件系统(包括与Local FS间的操作),不过已经Deprecated;

- hdfs dfs 只能操作HDFS文件系统相关(包括与Local FS间的操作),常用;

- hadoop fs 可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广;
目前版本来看,官方最终推荐使用的是hadoop fs。当然hdfs dfs在市面上的使用也比较多。
参数说明
HDFS文件系统的操作命令很多和Linux类似,因此学习成本相对较低。
可以通过hadoop fs -help命令来查看每个命令的详细用法。
HDFS shell命令行常用操作
创建目录
hadoop fs -mkdir [-p]
- path 为待创建的目录
- -p选项的行为与Unix mkdir -p非常相似,它会沿着路径创建父目录。
hadoop fs -mkdir /test2
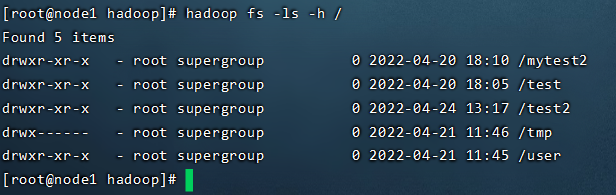
查看指定目录下内容
hadoop fs -ls [-h] [-R] [
- path 指定目录路径
- -h 人性化显示文件size
- -R 递归查看指定目录及其子目录
hadoop fs -ls -h /
上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p]
- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限。
- localsrc 本地文件系统(客户端所在机器)
- dst 目标文件系统(HDFS)
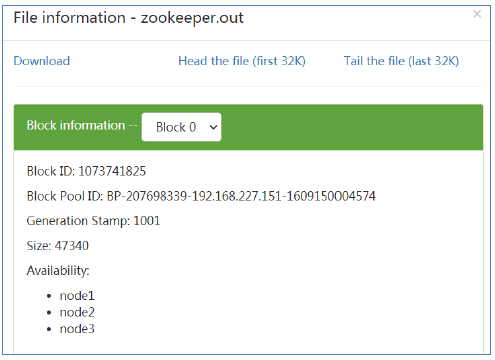
hadoop fs -put zookeeper.out /test hadoop fs -put file:///etc/profile hdfs://node1:8020/test
查看HDFS文件内容
hadoop fs -cat
读取指定文件全部内容,显示在标准输出控制台。
注意:对于大文件内容读取,慎重。
hadoop fs -cat /test/zookeeper.out
下载HDFS文件
hadoop fs -get [-f] [-p]
下载文件到本地文件系统指定目录,localdst必须是目录
- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限。
[root@node2 ~]# mkdir test [root@node2 ~]# cd test/ [root@node2 test]# ll total 0 [root@node2 test]# hadoop fs -get /test/zookeeper.out ./ [root@node2 test]# ll total 20-rw-r--r--1 root root 18213 Aug 18 17:54 zookeeper.out
拷贝HDFS文件
hadoop fs -cp [-f]
- -f 覆盖目标文件(已存在下)
[root@node3 ~]# hadoop fs -cp /small/1.txt /test [root@node3 ~]# hadoop fs -cp /small/1.txt /test/666.txt #重命令 [root@node3 ~]# hadoop fs -ls / testFound 4 items -rw-r--r--3 root supergroup 2 2021-08-18 17:58 /test/1.txt -rw-r--r--3 root supergroup 2 2021-08-18 17:59 /test/666.txt
追加数据到HDFS文件中
hadoop fs -appendToFile
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果
#追加内容到文件尾部appendToFile
[root@node3 ~]# echo 1 >> 1.txt
[root@node3 ~]# echo 2 >> 2.txt
[root@node3 ~]# echo 3 >> 3.txt
[root@node3 ~]# hadoop fs -put 1.txt /
[root@node3 ~]# hadoop fs -cat /1.txt1
[root@node3 ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt
[root@node3 ~]# hadoop fs -cat /1.txt123
HDFS数据移动操作
hadoop fs -mv
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
HDFS shell其他命令
命令官方指导文档
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
友情提示
常见的操作自己最好能够记住,其他操作可以根据需要查询文档使用。
命令属于多用多会,孰能生巧,不用就忘。
1.HDFS作为文件存储系统,实际开发中,我们需要做什么?
2.HDFS会有复杂的代码编程操作吗?
3.谁会更频繁的来读写HDFS上数据?
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
