




HDFS集群角色与职责
HDFS作为分布式软件,他的最大的魅力就在于,整个软件当中,是有不同的觉得存在的,而且角色会有不同的职责,接下来我们一起梳理下hdfs当中,有哪些角色,职责是什么
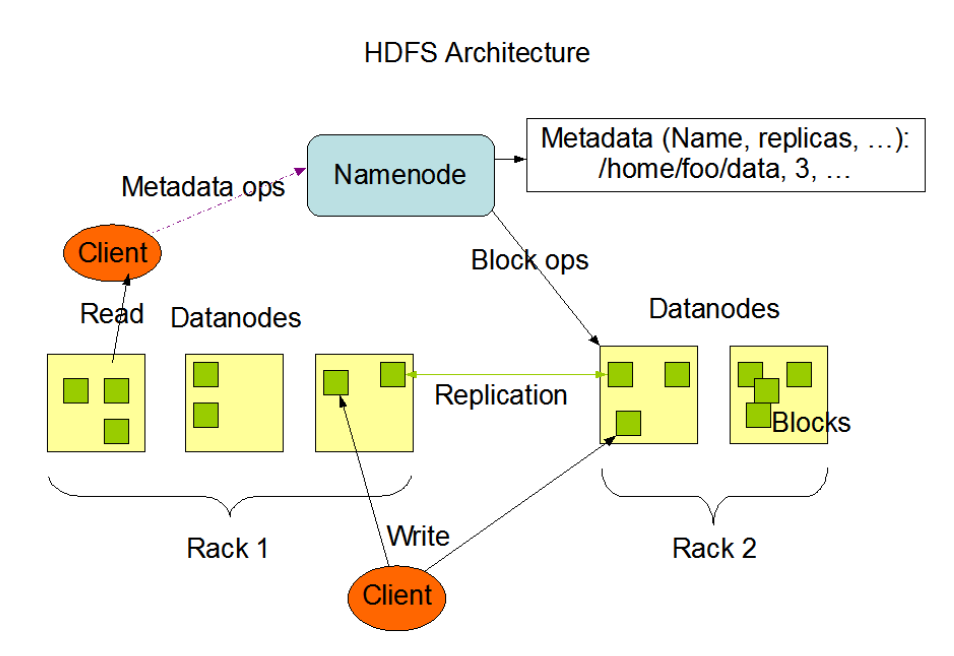
官方架构图
官方提供的构架图中有很多元素,我们重点关注角色,有一个NameNode,管理着我们的的matedata,有多个dataNode在不同的机架上,管理着数据块。
主角色:namenode
- NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
- NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
- 基于此,NameNode成为了访问HDFS的唯一入口。
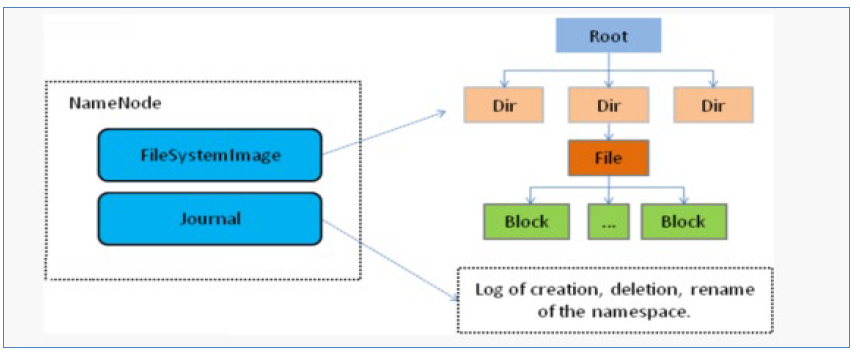
- NameNode内部通过内存和磁盘文件两种方式管理元数据。
- 其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log(Journal)编辑日志。
从角色:datanode
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
- DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。
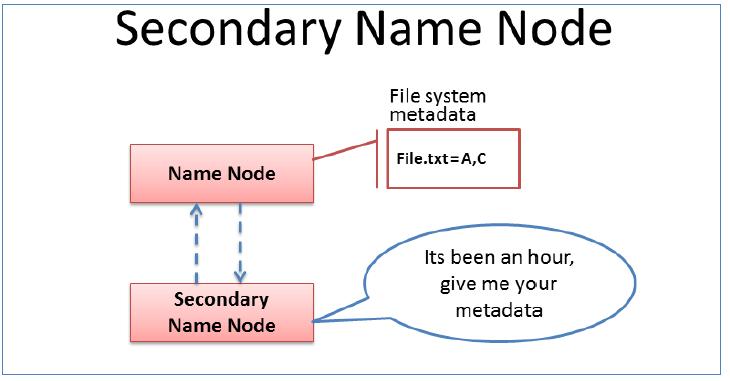
主角色辅助角色:secondarynamenode
- Secondary NameNode充当NameNode的辅助节点,但不能替代NameNode。
- 主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。
nameNode职责
- NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
- NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
- NameNode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从DataNode重建。
- NameNode是hadoop集群中的单点故障。一旦namenode故障,整个集群就无法正常工作了。
- NameNode所在机器通常会配置有大量内存(RAM)。
dataNode职责
- DataNode负责最终数据块block的存储。是集群的从角色,也称为Slave。
- DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
- 当某个DataNode关闭时,不会影响数据的可用性。NameNode将安排由其他DataNode管理的块进行副本复制。
- DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中。
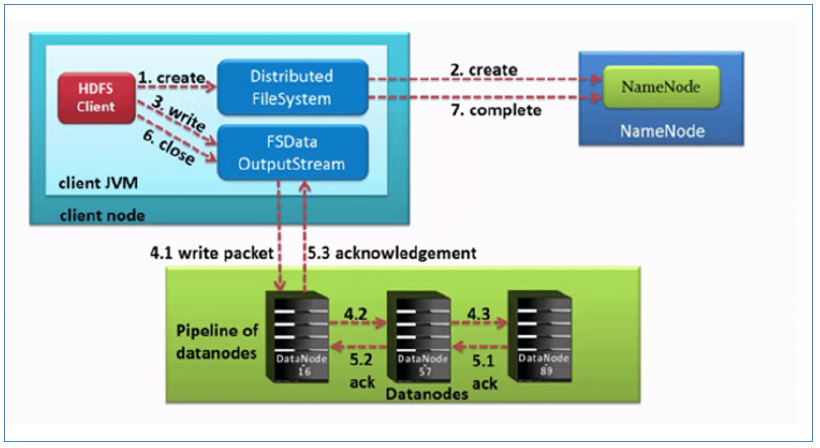
写数据完整流程图
核心概念–Pipeline管道
- Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
- 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
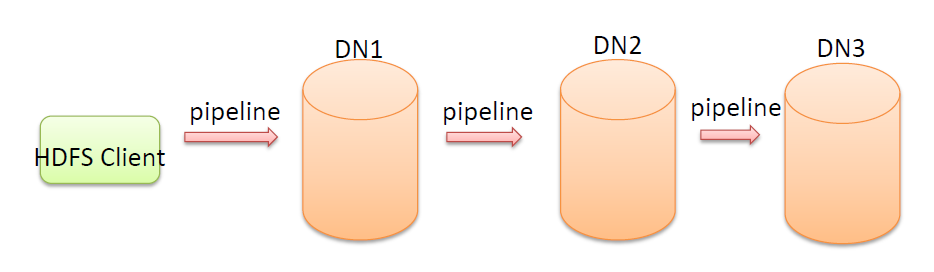
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
- 因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
- 在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
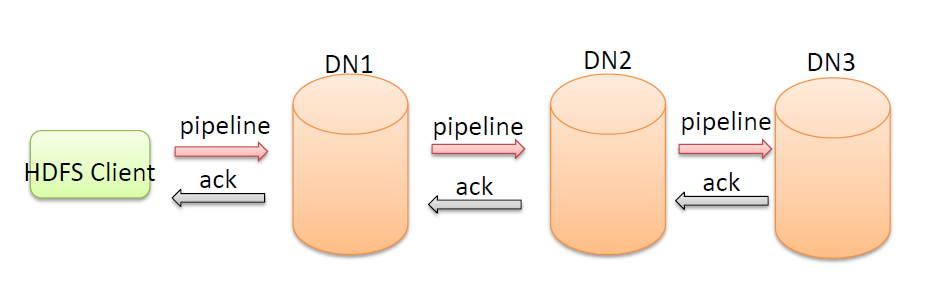
核心概念–ACK应答响应
传输过程中数据丢了怎么办?
- ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
- 在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
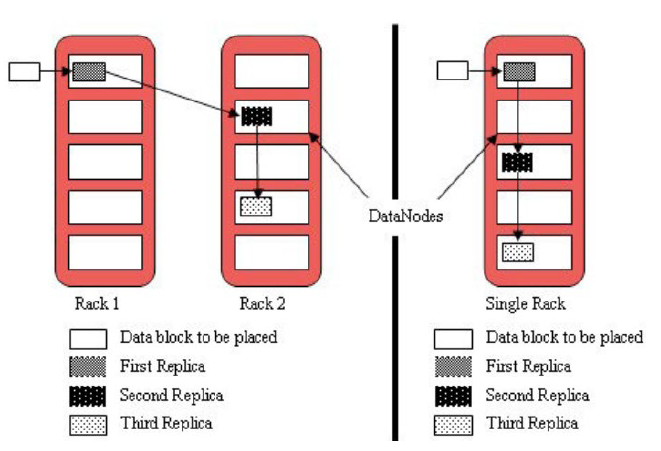
核心概念–默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定
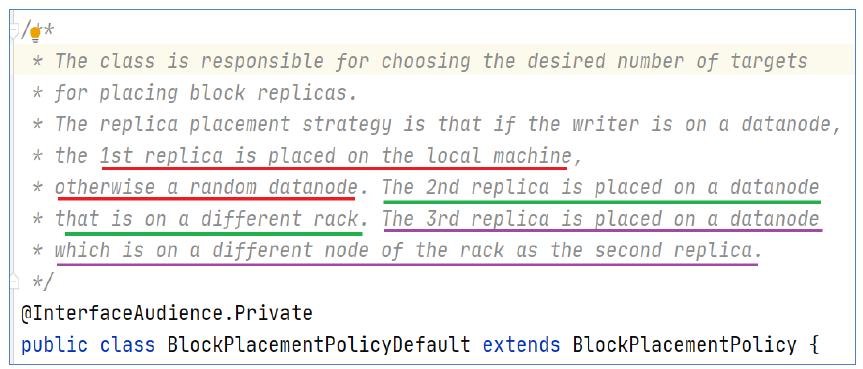

默认存放机制:
- 第一块副本:优先客户端本地,否则随机
- 第二块副本:不同于第一块副本的不同机架。
- 第三块副本:第二块副本相同机架不同机器。
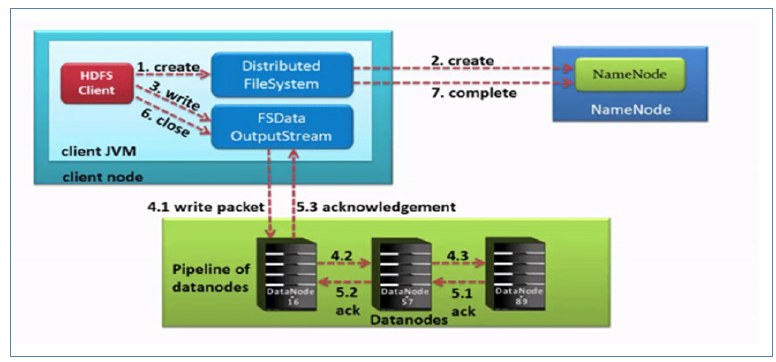
写流程(上传文件)
- HDFS客户端创建对象实例DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法。
- 调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。 - 客户端通过FSDataOutputStream输出流开始写入数据。
- 客户端写入数据时,将数据分成一个个数据包(packet 默认64k),内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。 - 传输的反方向上,会通过ACK机制校验数据包传输是否成功;
- 客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
- DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。 - 最小复制是由参数dfs.namenode.replication.min指定,默认是1.
HDFS读数据流程(下载文件)
读数据完整流程图
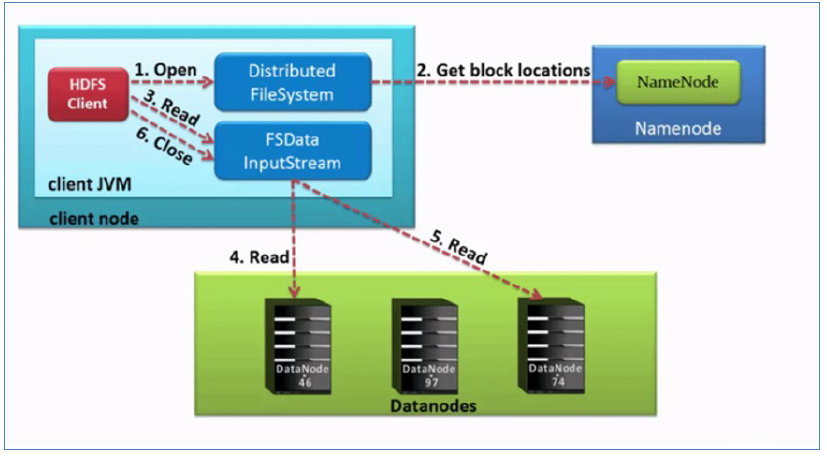
- HDFS客户端创建对象实例DistributedFileSystem,调用该对象的open()方法来打开希望读取的文件。
- DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取)信息。
对于每个块,namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的,与客户端的网络拓扑距离近的排序靠前。 - DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
- 客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件中第一个块的最近的DataNode。数据从DataNode流回客户端,结果客户端可以在流上重复调用read()。
- 当该块结束时,FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。 - 一旦客户端完成读取,就对FSDataInputStream调用close()方法。
传送门
(一) 初探Hadpoop
(二) hadoop发行版本及构架的变迁
(三) hadoop安装部署集群介绍
(四) hadoop安装部署-基础环境搭建
(五) hadoop安装部署-配置文件详解
(六) hadoop集群启停命令、Web UI
(七) hadoop-HDFS文件系统基础
(八) Hadoop-HDFS起源发展及设计目标
(九) Hadoop-HDFS重要特性、shell操作
(十) Hadoop-HDFS工作流程与机制
(十一) 如何理解Hadoop MapReduce思想
(十二) map阶段和Reduce阶段执行过程
待更新
最后修改时间:2022-05-09 08:44:39
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
文章被以下合辑收录
评论
相关阅读
顺丰科技:从 Presto 到 Doris 湖仓构架升级,提速 3 倍,降本 48%
SelectDB
26次阅读
2025-05-09 16:54:18
DolphinScheduler开发者必看!IDEA本地调试实战指南
海豚调度
23次阅读
2025-04-23 14:34:01
复杂业务隔离需求下的 NebulaGraph 集群迁移与版本升级全攻略
NebulaGraph 技术社区
14次阅读
2025-04-28 10:22:03
Flink自研特性: yarn application运行模式租户权限与yarn本地化资源可见性整合实践总结
大数据从业者
11次阅读
2025-05-07 10:06:03



