




原文链接:https://postgrespro.com/blog/pgsql/5969262
原文作者:Egor Rogov
你好! 我将开始另一个关于PostgreSQL内部的系列文章。 本文将重点讨论查询计划和执行机制。
这个专题包含以下内容:
- 查询执行阶段(本文)
- 统计信息
- 顺序扫描
- 索引扫描
- 嵌套连接
- 哈希连接
- 排序连接
简单查询协议
PostgreSQL的CS架构的基本目的有两个:
- 客户端发送sql查询到服务端,并且响应接收整个执行结果。
- 服务端接收到的查询需要经过几个阶段。
解析
首先,查询文本会被解析,以便服务器准确的理解需要做什么。
语法分析器和解析器
语法分析器负责识别查询语句中的词位,比如SQL关键字、字符串和数值等。解析器负责由语法分析器分出来的词位组成的结果在语法上是有效的。语法分析器和解析器使用标准的工具Bison和Flex来执行。
示例:
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
复制在这个步骤,会在内存中生成一个解析树。如下图是简化版的结构,树的不同节点会标记为查询的不同部分。
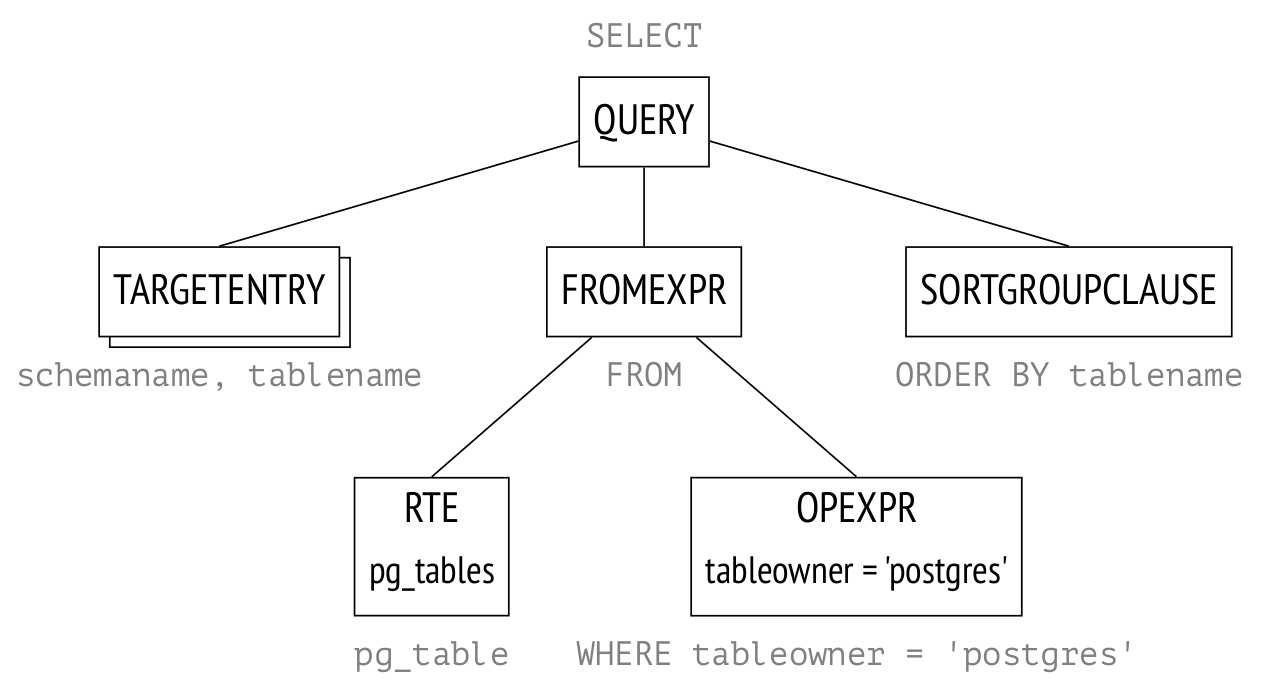
RTE是一个模糊的缩写,表示“范围表项”。在PostgreSQL源代码中的名称“范围表”指的是表、子查询、连接结果——换句话说,就是SQL语句操作的任何记录集。
语义分析
语义分析器确认查询语句所涉及的表和其他对象在数据库中是否存在和是否有权限去访问。语义分析器所需要的所有信息都存在系统目录中。
语义分析器接收来自解析器生成的解析树,并补充对特定数据库对象、数据类型信息等的引用。
如果参数debug_print_parse设置为ON,完整的解析树会在服务器的消息日志里,尽管这样没什么实际意义。
查询重写
接下来,查询可以被转换(重写)了。
查询重写有多个目的。其中一个是查询中出现的视图的查询替换解析树中的视图为子树。
示例中的pg_tables表是一个视图,在经过查询重写之后解析树是如下形式:
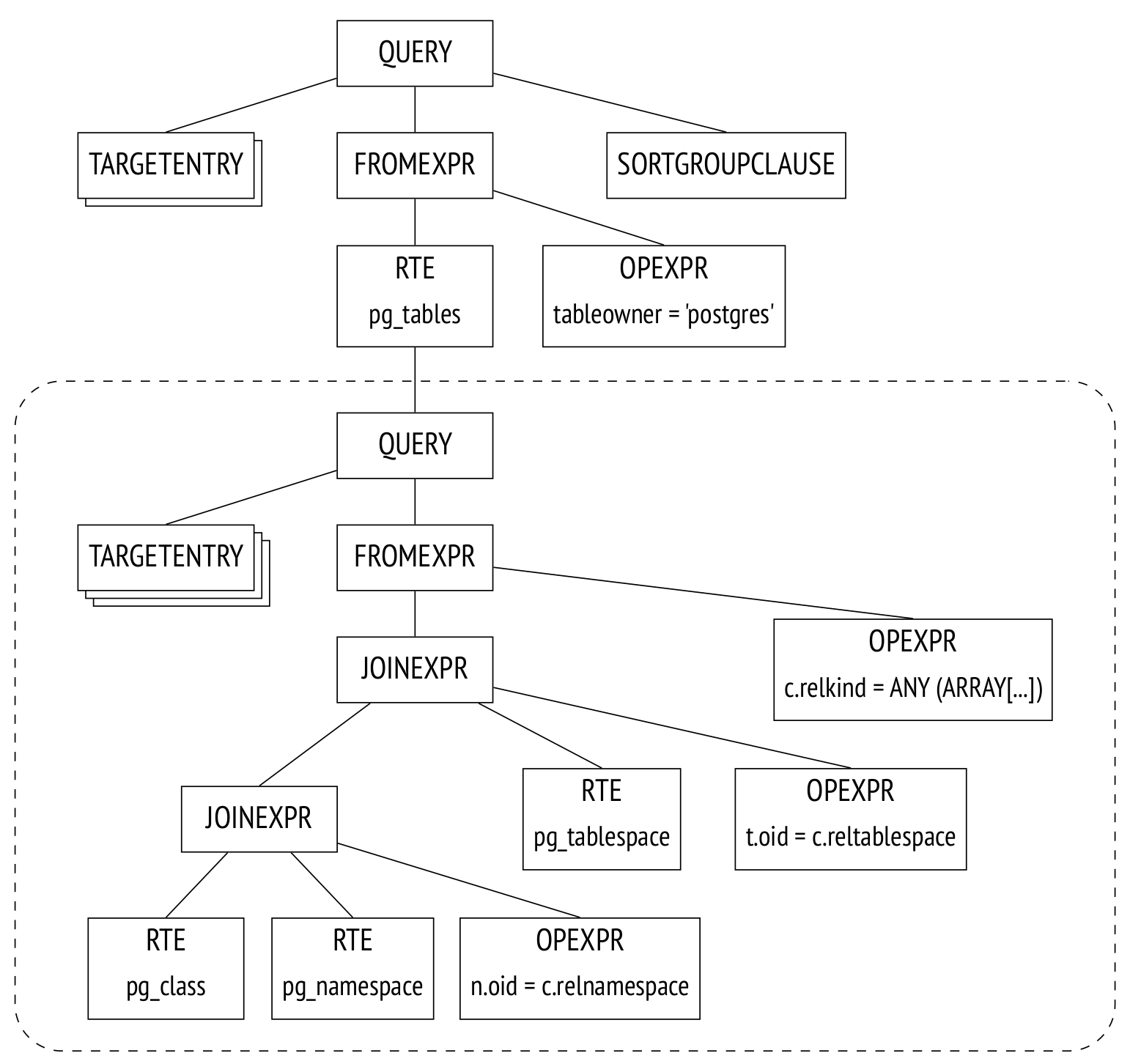
这个解析树相当于如下的查询(尽管所有的操作都在树上,而不是查询文本):
SELECT schemaname, tablename
FROM (
-- pg_tables
SELECT n.nspname AS schemaname,
c.relname AS tablename,
pg_get_userbyid(c.relowner) AS tableowner,
...
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = c.reltablespace
WHERE c.relkind = ANY (ARRAY['r'::char, 'p'::char])
)
WHERE tableowner = 'postgres'
ORDER BY tablename;
复制解析树反映了查询的语法结构,但不代表执行的顺序。
行级别的安全在转换阶段实施。
查询转换的另一个例子是版本14中用于递归查询的SEARCH和CYCLE子句的实现。
PostgreSQL支持自定义转换,用户可以使用重写系统规则来实现。
该规则系统是Postgres的主要特征之一 这些规则得到了项目基础的支持,并在早期开发期间被反复重新设计。 这是一个功能强大的机制,但是难于理解和调试。 甚至有人提议将这些规则从PostgreSQL中完全删除,但是没有得到普遍的支持。 在大多数情况下,使用触发器比使用规则更安全、更方便。
如果参数debug_print_rewrite是打开的,则转换后的完整解析树将显示在服务器消息日志中。
确定执行计划
SQL是一种声明性语言:查询指定检索什么,而不是如何检索。
任何查询都可以以多种方式执行。 解析树中的每个操作都有多个执行选项。 例如,您可以通过读取整个表并丢弃不需要的行来从表中检索特定的记录,或者您可以使用索引来查找与查询匹配的行。 数据集总是成对连接的。 连接顺序的变化会导致许多执行选项。 然后有各种方法将两组行连接在一起。 例如,您可以逐个检查第一个集合中的行,并在另一个集合中查找匹配的行,或者您可以先对两个集合排序,然后将它们合并在一起。 不同的方法在某些情况下性能更好,而在另一些情况下性能更差。
最优方案的执行速度可能比非最优方案快几个数量级。 这就是为什么优化已解析查询的计划器是系统中最复杂的元素之一。
计划树
执行计划也可以表示为树,但其节点是数据上的物理操作,而不是逻辑操作。
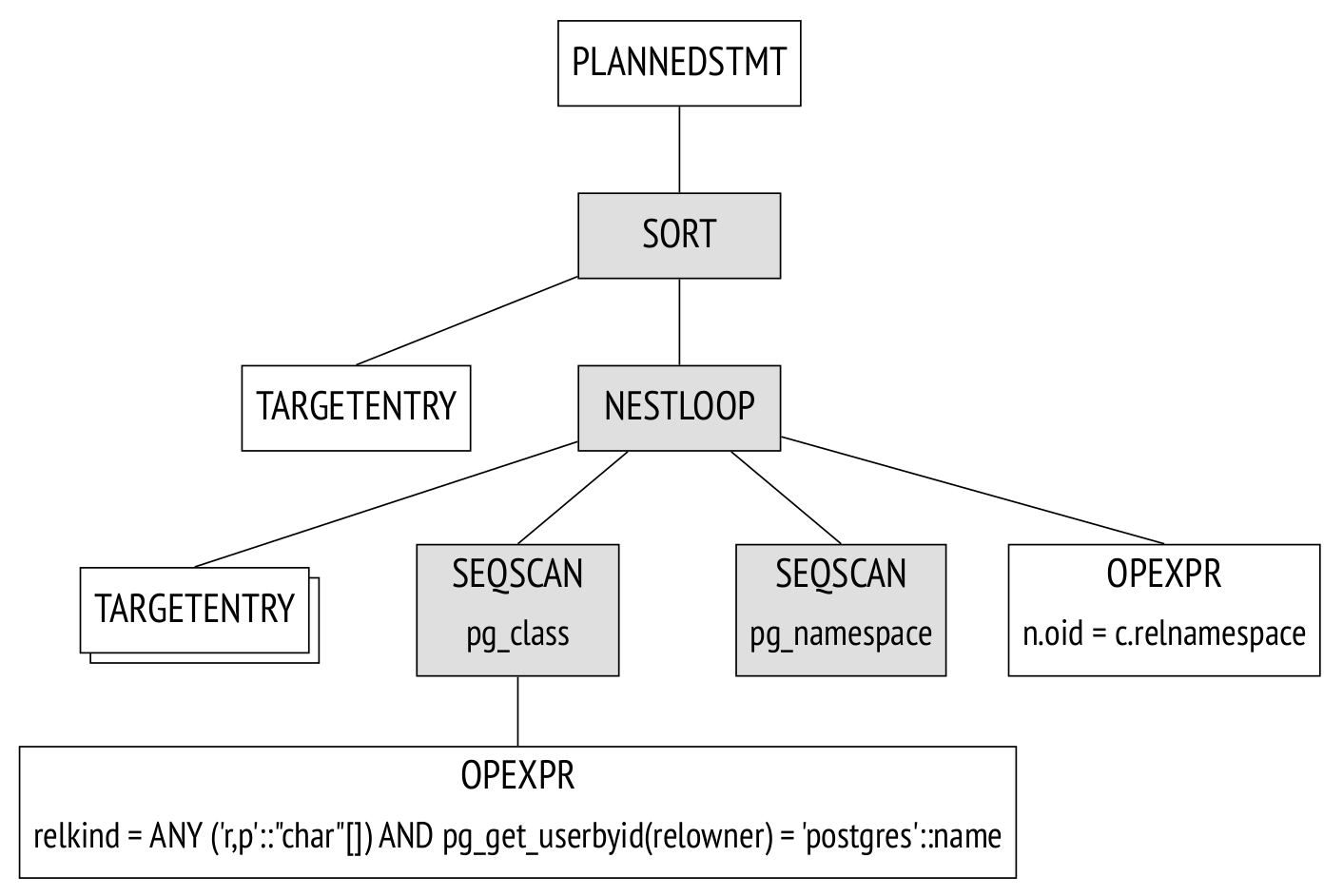
如果参数debug_print_plan是打开的,则完整的计划树将显示在服务器消息日志中。 通过这种方式查看是非常不实际的,因为日志非常混乱。 一个更方便的选择是使用EXPLAIN命令:
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
−> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
−> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_g...
−> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 wid...
(7 rows)
复制图中显示了树的主要节点。 在EXPLAIN输出中,同样的节点用箭头标记。
Seq Scan节点表示表读取操作,而Nested Loop节点表示连接操作。 这里有两点值得注意:
- 其中一个初始表从计划树中删除了,因为规划器发现它不需要处理查询,因此删除了它。
- 每个节点旁边都有一个估计的要处理的行数和处理的成本。
搜索计划
为了找到最优的计划,PostgreSQL使用了基于成本的查询优化器。 优化器执行各种可用的执行计划,并估计所需的资源数量,如I/O操作和CPU周期。 这个计算出来的估计,转换成任意的单位,被称为计划成本。 选择结果成本最低的计划执行。
问题是,随着连接数量的增加,可能计划的数量呈指数级增长,即使是相对简单的查询,也不可能逐个筛选所有计划。 因此,使用动态规划和启发式算法来限制搜索范围。 这允许在合理的时间内精确地解决查询中更多表的问题,但所选择的计划不能保证是真正最优的,因为规划器使用简化的数学模型,可能使用不精确的初始数据。
顺序连接
查询可以以特定的方式进行结构化,以显著减少搜索范围(冒着失去找到最佳计划的机会的风险):
- 通用表达式通常与主查询分开优化。 从版本12开始,这可以通过MATERIALIZE子句强制实现。
- 非sql函数的查询与主查询是分开优化的。 (SQL函数在某些情况下可以内联到主查询中。)
- join_collapse_limit参数与显式JOIN子句一起使用,以及from_collapse_limit参数与子查询一起使用,可以定义某些连接的顺序,具体取决于查询语法。
最后还需要说一下的事,对于下面这种没有显示连接的FROM中的表:
SELECT ...
FROM a, b, c, d, e
WHERE ...
复制这个查询的解析树是这样的:
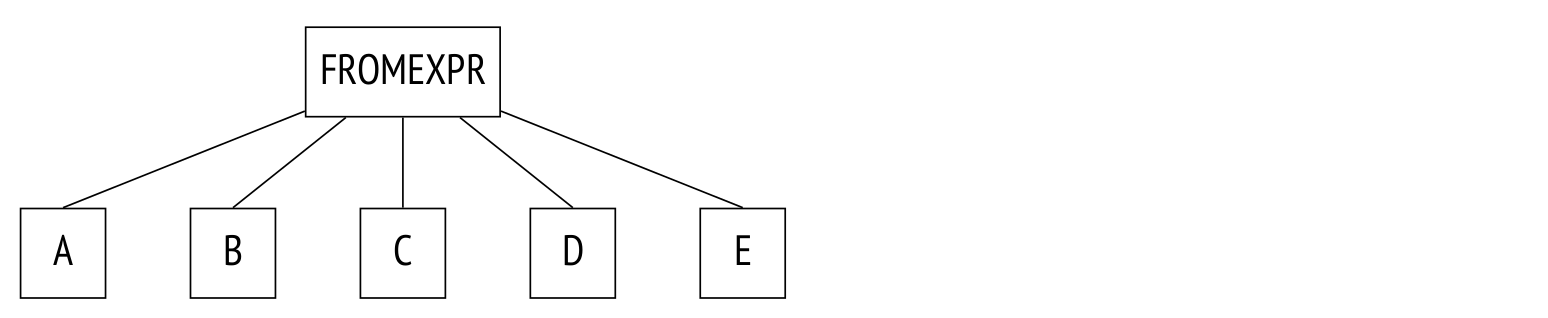
在这个查询中,规划器将考虑所有的连接顺序。
在下一个示例中,一些连接是由JOIN子句显式定义的:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
复制解析树反映了这一点:
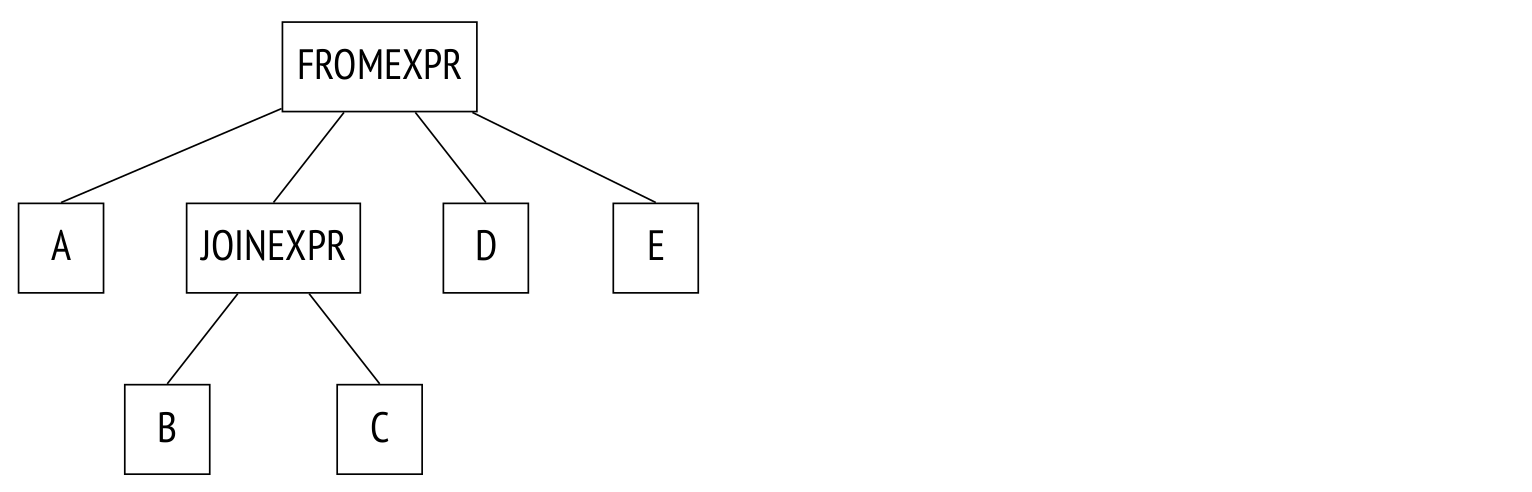
规划器折叠连接树,有效地将其转换为前面示例中的树。 该算法递归地遍历树,并用其组件的平面列表替换每个JOINEXPR节点。
但是,只有当生成的扁平列表包含的元素不超过join_collapse_limit(默认为8)时,才会出现这种“扁平化”。 在上面的示例中,如果join_collapse_limit设置为5或更少,JOINEXPR节点将不会被折叠。 对计划者来说,这意味着两件事:
- 表B必须与表C连接(反之亦然,对中的连接顺序不受限制)。
- 表A、D、E和B到C的连接可以以任何顺序连接。
如果join_collapse_limit设置为1,则将保留任何显式的JOIN顺序。
注意,无论join_collapse_limit如何,FULL OUTER JOIN操作永远不会折叠。
参数from_collapse_limit(默认也是8)以类似的方式限制子查询的扁平化。 子查询与连接似乎没有太多的共同点,但当涉及到解析树级别时,相似性就很明显了。
示例如下:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...
复制这是树:
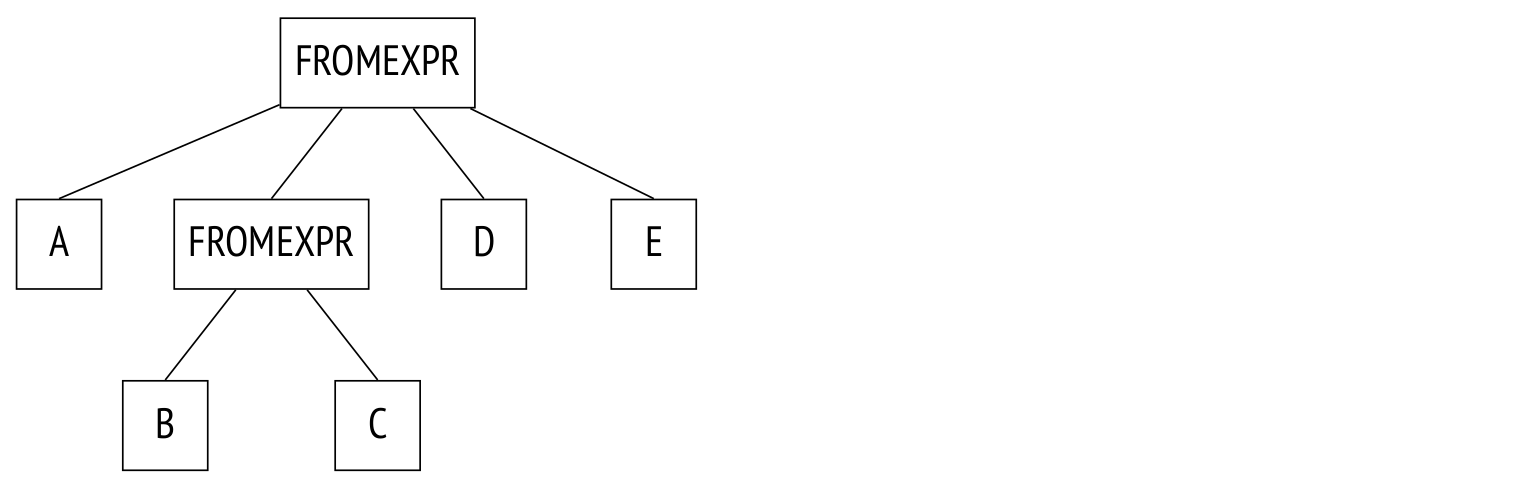
这里唯一的区别是,JOINEXPR节点被FROMEXPR替换(因此参数名称为FROM)。
遗传搜索
当扁平化的树最终拥有太多的同级节点(表或连接结果)时,规划时间可能会飙升,因为每个节点都需要单独的优化。 如果参数geqo是开启的(默认为开启),当同级节点数达到geqo_threshold(默认为12)时,PostgreSQL将切换到遗传搜索。
遗传搜索比动态规划方法快得多,但它不能保证找到最佳的可能计划。 这个算法有许多可调整的选项,但这是另一篇文章的主题。
选择最好的计划
最佳计划的定义因预期用途而异。 当需要一个完整的输出时(例如,生成一个报告),计划必须优化匹配查询的所有行的检索。 另一方面,如果您只想要前几个匹配的行(例如显示在屏幕上),那么最佳计划可能完全不同。
PostgreSQL通过计算两个成本组件来解决这个问题。 在执行计划的输出中,它们会显示在“cost”后面:
Sort (cost=21.03..21.04 rows=1 width=128)复制
第一个组成部分,启动成本,是为节点执行做准备的成本; 第二个部分,总成本,表示节点执行的总成本。
在选择计划时,规划器首先检查游标是否正在使用(可以使用DECLARE命令设置游标,也可以在PL/pgSQL中显式声明游标)。 如果不是,规划器假设需要全部输出,并选择总成本最小的计划。
否则,如果使用游标,规划器将选择一个最优检索行数等于匹配行的总数cursor_tuple_fraction(默认为0.1)的计划。 或者,更具体地说,一个cost最低的计划
启动成本+ cursor_tuple_fraction ×(总成本−启动成本
成本核算过程
为了估计一个计划成本,它的每个节点都必须单独估计。 节点成本取决于节点类型(从表中读取数据的成本远低于对表进行排序的成本)和处理的数据量(通常,数据越多,成本越高)。 虽然节点类型马上就知道了,但要评估数据量,我们首先需要估计节点的基数(输入行数)和选择性(剩余用于输出的行数)。 为此,我们需要数据统计:表大小、跨列的数据分布。
因此,优化依赖于准确的统计数据,这些数据由自动分析过程收集并保持最新。
如果准确估计了每个计划节点的基数,则计算出的总成本通常与实际成本相匹配。 常见的规划器偏差通常是基数和选择性估计错误的结果。 这些错误是由不准确的、过时的或不可用的统计数据,以及(在较小程度上)计划者所基于的内在不完善的模型造成的。
基数评估
基数评估递归执行。 节点基数使用两个值计算:
- 节点子节点的基数,或输入行数。
- 节点的选择性,或输出行与输入行的比例。
基数是这两个值的乘积。
选择性是0到1之间的数字。 接近0的选择性值称为高选择性,接近1的值称为低选择性。 这是因为高选择性会消除较高比例的行,而低选择性值会降低阈值,因此会丢弃更少的行。
首先处理具有数据访问方法的叶节点。 这就是表大小等统计信息发挥作用的地方。
应用于表的条件的选择性取决于条件类型。 在其最简单的形式中,选择性可以是一个恒定的值,但是规划器试图使用所有可用的信息来产生最准确的估计。 以最简单条件的选择性估计为基础,用布尔运算构建的复杂条件可以通过以下简单的公式进一步计算:
selx and y = selx sely selx or y = 1−(1−selx)(1−sely) = selx + sely − selx sely.复制
在这些公式中,x和y被认为是独立的。 如果它们相互关联,公式仍在使用,但估计将不那么准确。
对于连接的基数估计,计算两个值:笛卡尔乘积的基数(两个数据集的基数的乘积)和连接条件的选择性,后者又取决于条件类型。
其他节点类型(如排序或聚合节点)的基数也是类似计算的。
请注意,在较低节点中的基数计算错误将向上传播,导致不准确的成本估计,最终导致次优计划。 更糟糕的是,规划器只有表上的统计数据,而没有连接结果上的统计数据。
成本评估
成本估算过程也是递归的。 子树的开销由子节点的开销加上父节点的开销组成。
节点成本计算是基于它所执行操作的数学模型,已经评估的基数作为输入,该过程计算启动成本和总成本。
有些操作不需要任何准备,可以立即开始执行。 对于这些操作,启动成本为零。
其他操作可能有前提条件。 例如,排序节点通常需要其子节点的所有数据才能开始操作。 这些节点的启动成本是非零的。 必须支付此成本,即使下一个节点(或客户机)只需要输出一行。
成本是策划者的最佳评估,任何计划上的错误都会影响成本与实际执行时间的相关性。 成本评估的主要目的是允许规划者在相同的条件下比较相同查询的不同执行计划。 在其他情况下,通过成本来比较查询(更糟糕的是,不同的查询)是毫无意义的,也是错误的。 例如,考虑一个由于统计数据不准确而被低估的成本。 更新统计数据——成本可能会改变,但估算会更准确,计划最终也会完善。
执行
根据计划执行优化的查询。
在后端内存中创建一个名为portal的对象。 portal在执行查询时存储查询的状态。 这个状态表示为树,在结构上与计划树相同。
树的节点充当装配线,彼此请求和传递。

从根节点开始执行,根节点(示例中的排序节点SORT)从子节点请求数据,当它接收到所有请求的数据时,它执行排序操作,然后将数据向上传递给客户端。
一些节点(如NESTLOOP节点)连接来自不同来源的数据,该节点从两个子节点请求数据。 在接收到符合联接条件的两行后,节点立即将结果行传递给父节点(与排序不同,后者必须在处理之前接收所有行)。 然后,该节点停止,直到其父节点请求另一行。 因此,如果只需要部分结果(例如,由LIMIT设置),则不会完全执行操作。
两个SEQSCAN页是表扫描。 根据父节点的请求,叶节点从表中读取下一行并返回它。
这个节点和其他一些节点根本不存储行,而是直接交付并立即忘记它们。 其他节点,比如排序,可能需要一次存储大量的数据。 为了处理这个问题,在后端内存中分配了一个work_mem内存块。 它的默认大小是保守的4MB限制; 当内存耗尽时,多余的数据被发送到磁盘上的临时文件。
一个计划可能包含有存储需求的多个节点,因此它可能分配几个内存块,每个块的大小为work_mem。 查询进程可能占用的总内存大小没有限制。
扩展查询协议
使用简单的查询协议,任何命令,即使是一次又一次地重复,也要经历上述所有阶段:
- 解析
- 转换
- 规划
- 执行
但是没有理由一遍又一遍地解析同一个查询。 如果查询只是常量不同,也没有理由重新解析它们:解析树将是相同的。
简单查询协议的另一个麻烦是,客户端接收完整的输出,不管输出有多长。
使用SQL命令可以解决这两个问题:对于第一个问题准备一个查询并执行它,对于第二个问题声明一个游标并FETCH所需的行。 但是,客户机将不得不处理新对象的命名,而服务器将需要解析额外的命令。
扩展的查询协议允许在协议命令级别对单独的执行阶段进行精确控制
准备
在准备期间,像往常一样解析和转换查询,但解析树存储在后端内存中。
PostgreSQL没有一个全局缓存用于解析查询。 即使一个进程之前已经解析过该查询,其他进程也必须再次解析它。 然而,这种设计也有好处。 在高负载下,全局内存缓存很容易因为锁而成为瓶颈。 一个客户端发送多个小命令可能会影响整个实例的性能。 在PostgreSQL中,查询解析很便宜,并且与其他进程隔离开来。
可以用附加参数准备查询,下面是一个使用SQL命令的示例(同样,这与协议命令级别的准备是不同的,但最终效果是相同的):
PREPARE plane(text) AS
SELECT * FROM aircrafts WHERE aircraft_code = $1;
复制本系列文章中的大多数示例将使用演示数据库“Airlines”。
该视图显示所有已命名的预处理语句:
SELECT name, statement, parameter_types
FROM pg_prepared_statements \gx
−[ RECORD 1 ]−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
name | plane
statement | PREPARE plane(text) AS +
| SELECT * FROM aircrafts WHERE aircraft_code = $1;
parameter_types | {text}
复制视图没有列出任何未命名的语句(使用扩展协议或PL/pgSQL的语句)。 它也没有列出来自其他会话的准备语句:访问另一个会话的内存是不可能的。
参数绑定
在执行准备好的查询之前,将绑定当前参数值。
EXECUTE plane('733');
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Boeing 737−300 | 4200
(1 row)
复制与字面值表达式的连接相比,预处理语句的一个优点是防止任何类型的SQL注入,因为参数值不会影响已经构建的解析树。 预处理的语句在没有达到相同的安全级别的情况下将会对来自不可信来源的所有值进行大量的溢出。
计划和执行
当执行准备好的语句时,首先使用提供的参数规划查询,然后将选择的计划发送执行。
实际参数值对规划器很重要,因为不同参数集的最优方案也可能不同。 例如,当寻找高级航班预订时,使用索引扫描(index scan),因为规划器期望匹配的行不多:
CREATE INDEX ON bookings(total_amount);
EXPLAIN SELECT * FROM bookings WHERE total_amount > 1000000;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (cost=86.38..9227.74 rows=4380 wid...
Recheck Cond: (total_amount > '1000000'::numeric)
−> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00....
Index Cond: (total_amount > '1000000'::numeric)
(4 rows)
复制然而,下一个条件完全符合所有的预订。 索引扫描在这里是没用的,而是执行顺序扫描(Seq scan):
EXPLAIN SELECT * FROM bookings WHERE total_amount > 100;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on bookings (cost=0.00..39835.88 rows=2111110 width=21)
Filter: (total_amount > '100'::numeric)
(2 rows)
复制在某些情况下,规划器除了存储解析树之外还存储查询计划,以避免在解析树出现时再次进行规划。 这种没有参数值的计划被称为通用计划,与使用给定参数值生成的自定义计划相反。 通用计划的一个明显的用例是没有参数的语句。
对于前4次运行,带参数的预处理语句总是根据实际参数值进行优化。 然后计算平均计划成本。 在第五次及以后的运行中,如果通用计划比定制计划(每次都必须重新构建)的平均成本更低,规划器将从此存储并使用通用计划,然后再进行进一步的优化。
plane预处理语句已经执行过一次了。 在接下来的两次执行中,仍然使用定制计划,如查询计划中的参数值所示:
EXECUTE plane('763');
EXECUTE plane('773');
EXPLAIN EXECUTE plane('319');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '319'::text)
(2 rows)
复制执行四次之后,计划者将切换到通用计划。 在这种情况下,通用计划与自定义计划相同,具有相同的成本,因此是可取的。 现在EXPLAIN命令显示了参数号,而不是实际值:
EXECUTE plane('320');
EXPLAIN EXECUTE plane('321');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '$1'::text)
(2 rows)
复制有个令人遗憾但是不是不可能发生的情况是,只有第四次执行计划比通过执行计划的成本更高,其他任何一次都是更低的,这时候,规划器将会忽略其他所有的计划。
另外一个问题是规划器比较评估成本,而不是真正需要花费的成本。(并不是真实的,而是估算的)
这就是为什么在版本12及以上中,如果用户不喜欢自动结果,他们可以强制系统使用通用计划或自定义计划。 这是通过参数plan_cache_mode完成的:
SET plan_cache_mode = 'force_custom_plan';
EXPLAIN EXECUTE plane('CN1');
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = 'CN1'::text)
(2 rows)
复制在14及以上版本中,pg_prepared_statements视图也显示计划选择统计信息:
SELECT name, generic_plans, custom_plans
FROM pg_prepared_statements;
name | generic_plans | custom_plans
−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−
plane | 1 | 6
(1 row)
复制输出检索
扩展查询协议允许客户端分批获取输出,一次获取几行,而不是一次获取所有行。 使用SQL游标也可以实现同样的效果,但成本更高,规划师将优化cursor_tuple_fraction第一行的检索:
BEGIN;
DECLARE cur CURSOR FOR
SELECT * FROM aircrafts ORDER BY aircraft_code;
FETCH 3 FROM cur;
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−+−−−−−−−
319 | Airbus A319−100 | 6700
320 | Airbus A320−200 | 5700
321 | Airbus A321−200 | 5600
(3 rows)
FETCH 2 FROM cur;
aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Boeing 737−300 | 4200
763 | Boeing 767−300 | 7900
(2 rows)
COMMIT;
复制每当查询返回大量行,而客户端需要它们时,每次检索的行数对整体数据传输速度来说就变得至关重要。 单个批处理的行越多,在往返延迟上损失的时间就越少。 但是,随着批大小的增加,效率方面的节省就会减少。 例如,批量大小从1切换到10将大大节省时间,但从10切换到100几乎不会有任何不同。
请继续关注下一篇文章,其中我们将讨论成本优化的基础:统计信息。
评论

 0 点赞
0 点赞 0 点赞
0 点赞