




一 背景
监控平台主要针对业务系统和技术中台内的硬件和软件进行监控和告警。随着云筑应用系统越来越多、IT架构越来越繁杂,我们需要一种直观地全局审查应用运行状况、资源利用的方式。监控系统不仅为应用系统提供健康稳定运行的监控保障;也能通过采集和存储的大量监控数据,提供基于监控数据的智能分析、告警预警、应急预案和故障自愈等服务。
监控对象:主机,容器,分布式存储,SDN网络,分布式系统,中间件。
监控角度:服务器监控,容器监控,网络监控,存储监控,应用性能监控(apm),中间件监控等。
案例:
二 愿景

三 现状和技术调研
1. 监控现状
apm: 在建
主机、网络监控:
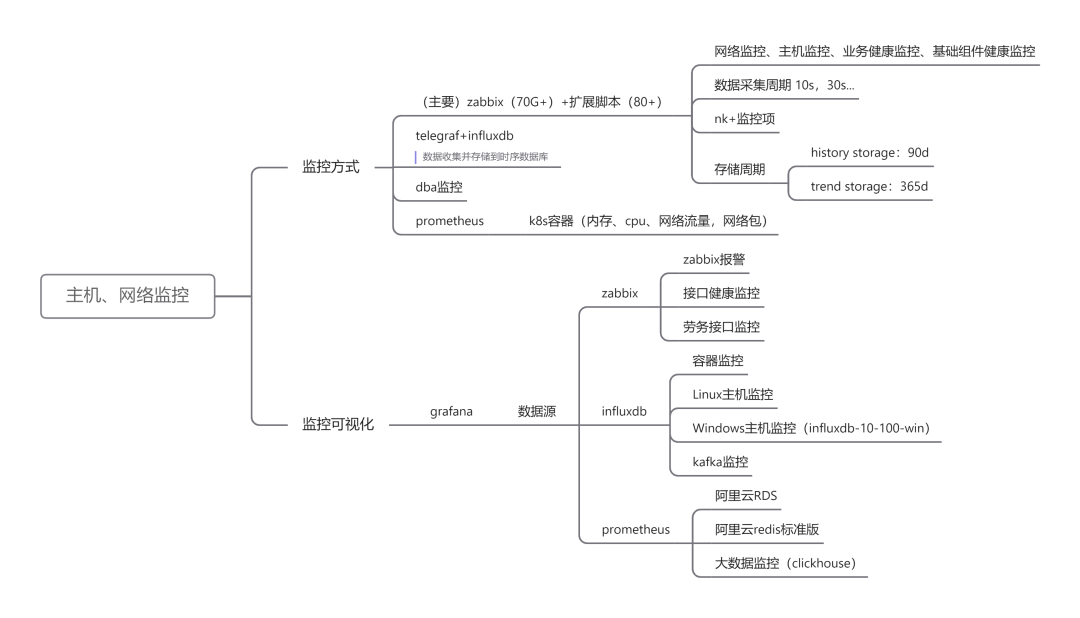
2. 参考
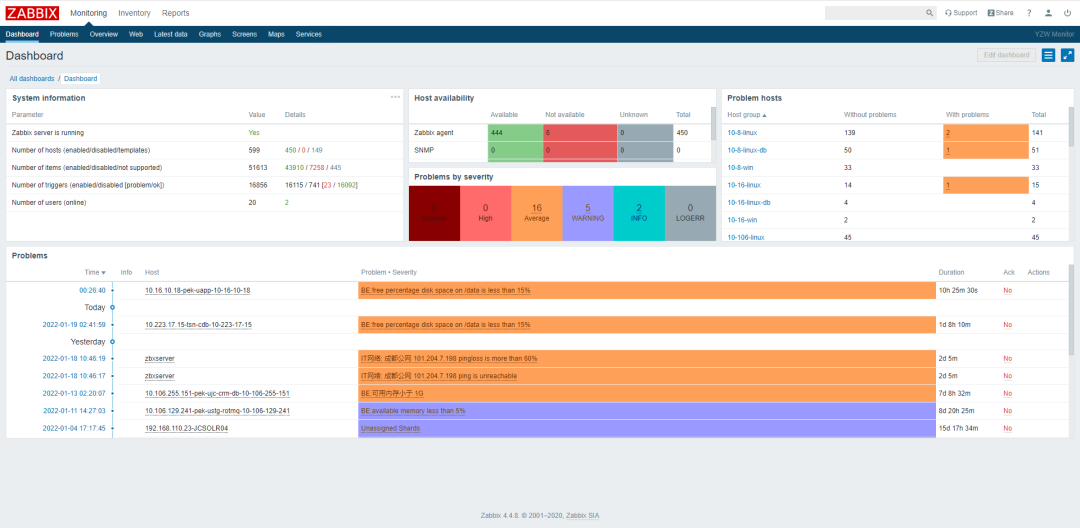
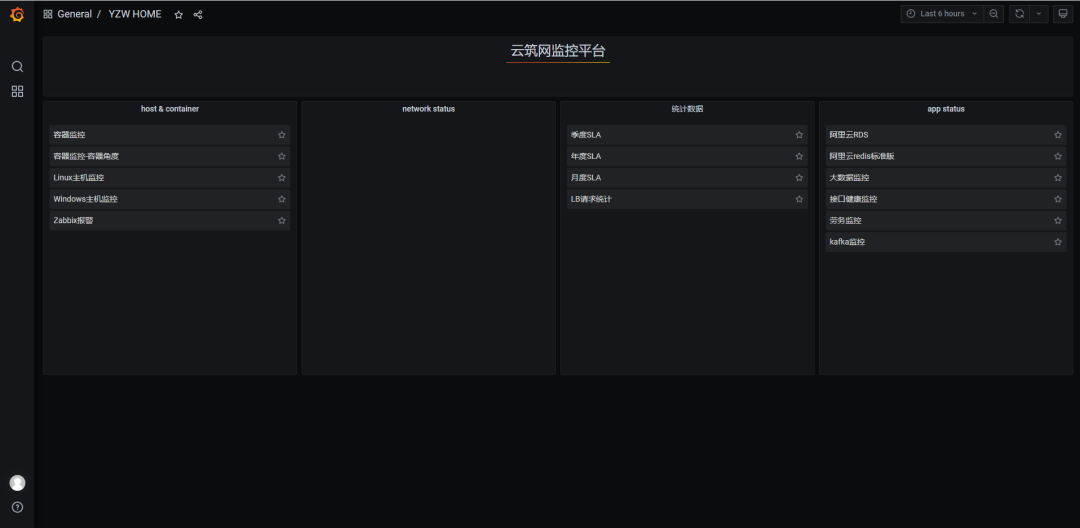
痛点
缺少业务全景视图(业务全拓扑)
无法分析全服务的调用情况(服务调用拓扑+服务调用树)
无法快速定位业务问题(问题快速定位)
无法灵活地配置业务监控告警(监控告警)
无法快速接入监控应用性能(agent零侵)
监控工具冗杂,监控架构不明确,维护和实现定制化需求难度极大(zabbix+prometheus+telegraf+influxdb+grafana)
四 价值
1. 业务价值
建立一套完善的稽核巡检机制,快速定位问题,判断故障影响范围,降低故障影响时长
通过全链路梳理应用和服务依赖关系,辅助分析业务关联关系
分析性能瓶颈,及时发现和应对性能问题,降低压测成本
实现业务级粒度监控,辅助分析业务运行状况
2. 运维价值
统一云筑监控,降低监控复杂度,更好地维护监控架构
沉淀故障分析、排查、处理的方式,减少重复繁琐的运维操作,实现高效地流程化运维、智能化运维
统一监控告警,增强监控能力,及时发现和处理故障,降低生产故障影响业务时长
分析架构合理性,资源利用率,降低硬件成本
3. 运营价值
提供运营视角全景图,辅助运营决策分析
五 产品架构
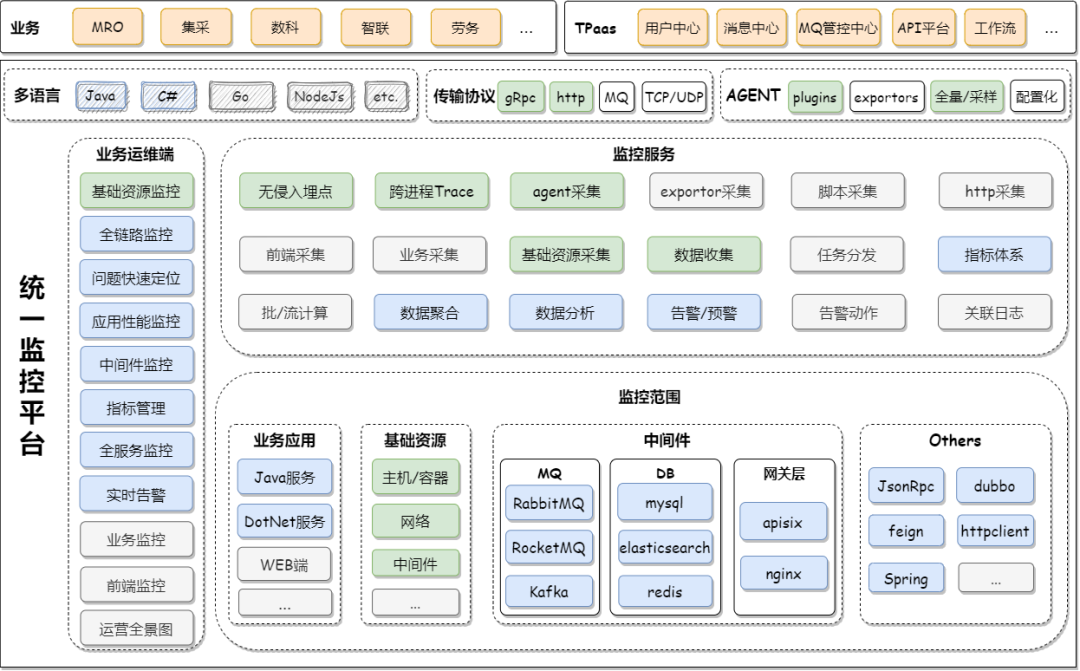
六 技术架构
基于skywalking+prometheus进行适配云筑业务架构的定制化二次开发
skywalking:agent丰富的多语言支持;天然支持elasticsearch存储,更好的数据分析与聚合
prometheus:go语言,二次开发难度更低;更好的云环境支持
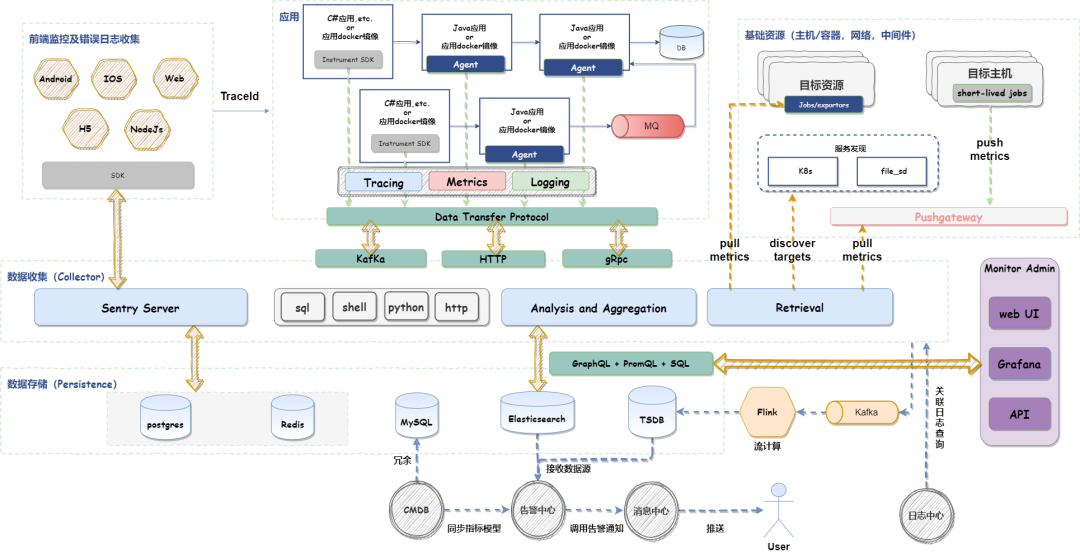
七 功能设计
apm总体核心架构主要由三部分组成:
agent:探针,用来收集和发送数据到收集器
collector:数据收集器,用来归集采集的监控数据、转发计算、落地存储等
web:可视化平台,用来呈现落地的监控数据
1.全链路监控
apm的核心在于agent部分,需要将一次调用跨进程(线程)串联,过程中包括Trace、Span、Tags、Logs等。

全局拓扑:包括应用调用拓扑(请求数,tps;后续关联资源利用率),请求散列点,请求耗时、状态统计
调用详情树分析:呈现方法级监控;包括但不限于集群,应用,方法,出入参,耗时情况,请求状态
单次请求调用拓扑:展示单笔请求调用过程
全局服务监控:服务负载,慢服务,服务健康检查,延迟响应
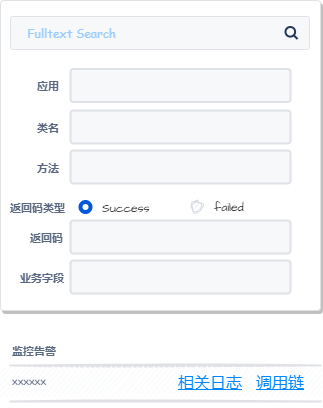
2.问题快速定位
通过应用、类名、方法、业务字段、链路ID等keywords快速全文检索出故障链路,定位故障发生的实例、异常情况、耗时情况、实例性能走势等,整个定位过程仅需几分钟,极大提高定位故障的效率。
全文检索:提供应用、类名、方法、返回码类型、返回码以及业务字段等进行客诉全文检索出链路
监控告警关联链路,页面提供快速链接
3.指标管理
通过建立一套KPI体系、一套巡检机制以及一套关注的业务场景,实现端到端追溯链路和全业务监控大屏视图,将应用系统由原有的黑盒作业转变为可管可控可预测的玻璃房,提升系统出现异常的响应效率,降低运维门槛,提升运维效率。
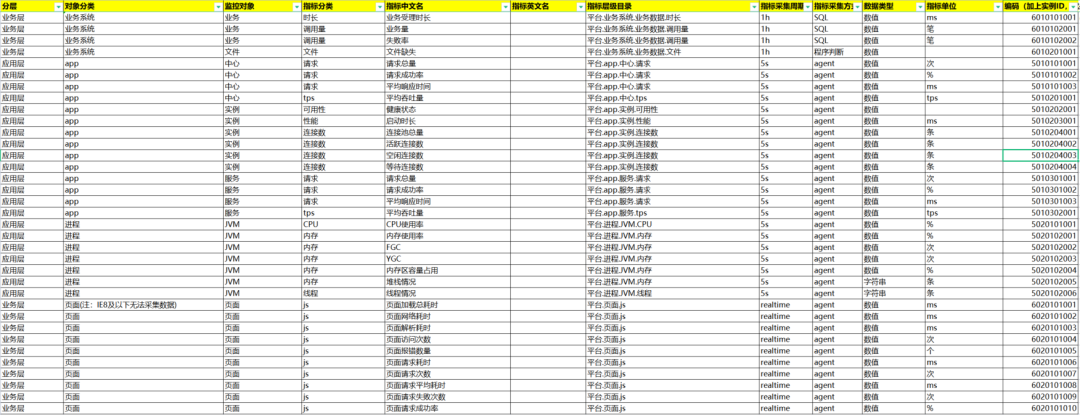
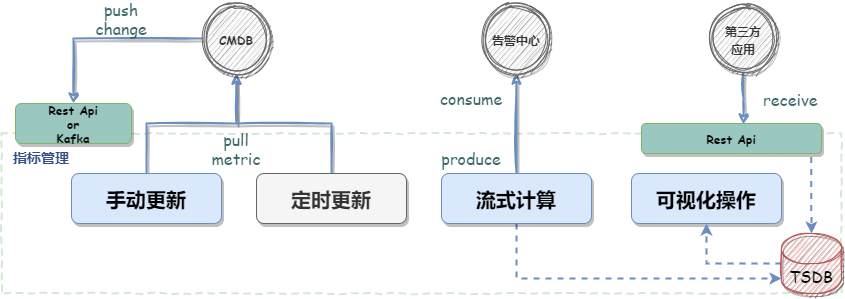
监控点 = 对象 + 指标(例 MRO请求成功率=MRO+请求成功率)
冗余cmdb维护的指标体系(支持定时更新、手动更新以及cmdb-push变更操作)
流计算指标
支持第三方上报性能数据(e.g.MQ管控平台)
对象管控(CMDB负责维护)
指标管控(CMDB负责维护)
监控点管控
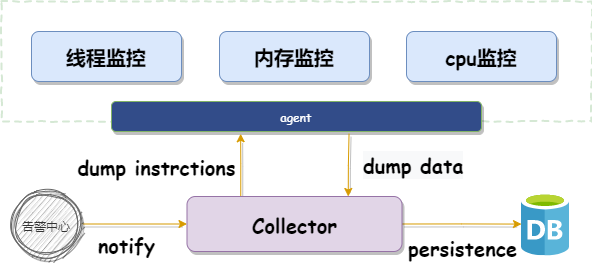
4.JVM性能监控
在生产故障排查和定位过程中,往往由于线程池阻塞、CPU占用过高、内存区占用过高引起故障,并且故障仅仅是瞬时,因此需要监控平台提供性能监控,在故障发生时快速进行dump打印,用于故障排查,提高运维效率。监控系统JVM的内存、CPU、线程的详细使用情况,为性能瓶颈提供可靠地辅助分析手段。
线程监控分析:采集全部线程,支持配置区分线程类型和线程状态(是否死锁)
cpu监控分析:采集JVM-cpu使用率
内存监控分析:采集JVM内存和垃圾回收
5.监控告警
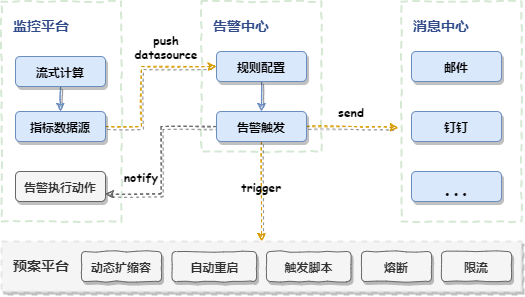
建设监控告警模型规范标准,对接告警中心,发送告警通知
八 迭代思路

