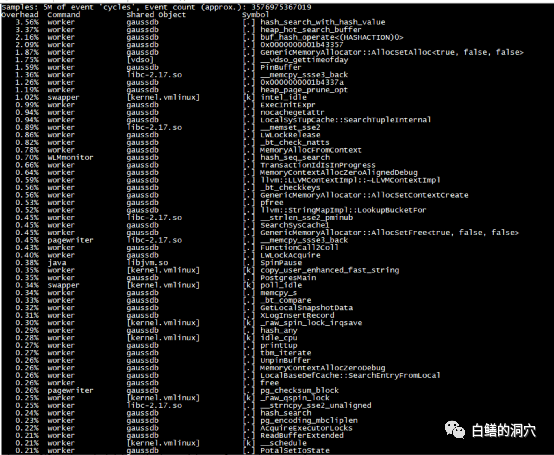
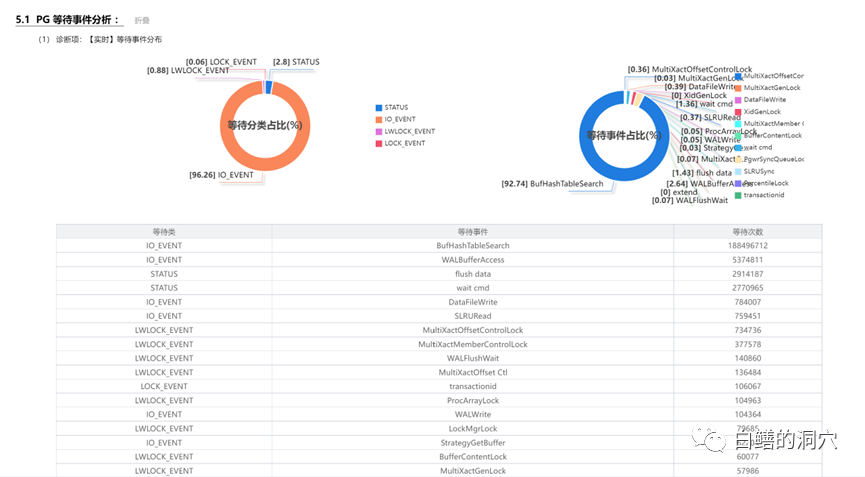
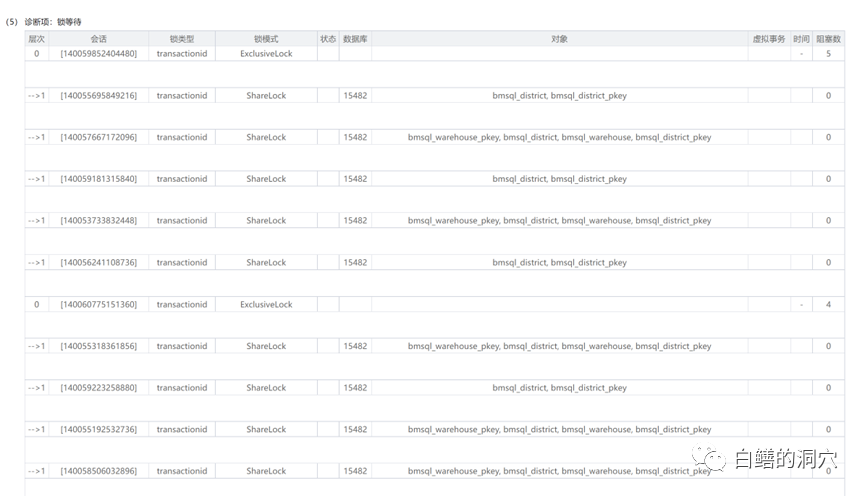
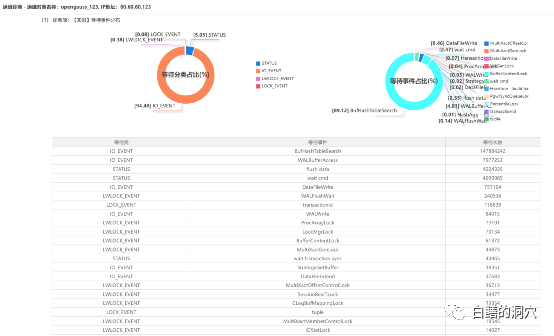
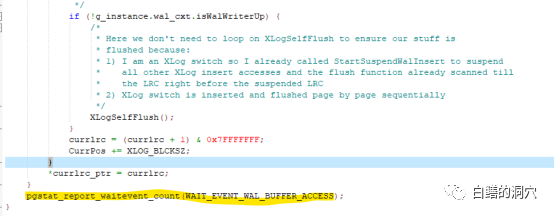
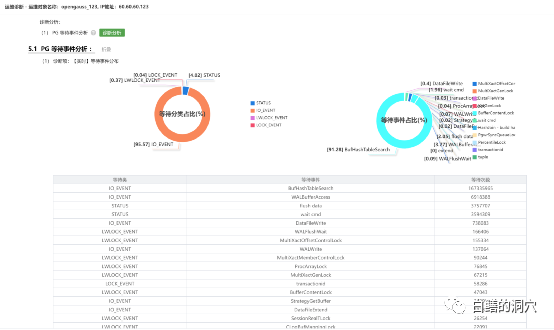
国产数据库和开源数据库的优化问题一直是个比较头疼的事情,当某些问题发生后,只能通过猜测,阅读源代码,使用火焰图等方法来进行分析,没有类似Oracle Metalink这样的知识库可以参考。那么我们使用以往掌握的其他数据库的优化经验,能否用于没有太多积累的开源、国产数据库呢?五一节正好有空,我试着分析一下openGauss的一些等待事件优化方法的问题。手头没有其他的业务负载测试环境,于是只能使用Benchmark来对系统进行加压。测试了多次,发现一旦压力上去,无论怎么调整,在30 Warehouse的情况下,tpmTotal不到30万,tpmC才 12万7。从Perf看到的系统调用情况,发现hash_search_with_hash_value和heap_hot_search_buffer调用比较多。从等待事件上看,BufHashTableSearch的等待排在第一位,占了9成以上的比例。从经验上看,是shared buffer访问,或者说出现了热块冲突导致了此类问题。我尝试调整了表和索引的FILLFACTOR参数,表调整为70,索引调整为80。再次压测之后发现有所改善,不过问题依然没有解决太多。从资源使用率上看,CPU使用率不高,似乎是被什么瓶颈挡住了,并没有充分地发挥出来。从所等待上看,表记录和pkey上的等待都差不多严重。而从等待事件来看,和刚才FILLFACTOR 100%的时候差不太多。于是我进一步减小FILLFACTOR,设置表的FILLFACTOR =50,索引的FILFACTOR =60。从TPMC指标上看,比刚才又有所提高。在openGauss社区的群里和华为的朋友沟通了我的问题,他们根据以往BENCHMARK测试的情况分析可能在索引上存在热块冲突,建议我做个火焰图看看问题在索引上还是在什么地方。从分析工具上我也看到了PK上都存在一定的争用,因此我正好在做一个表FILLFACTOR=40,索引FILLFACTOR=35的测试。测试结果出来后发现,TPMC又有了较大的提升,tpmTotal达到了43万多,tpmC达到了19.3万多。从负载情况看,CPU使用率,每秒事务数,每秒日志量等指标都有了较大的提升。从Benchmark压测的情况看,基于PG的数据库shared buffer访问时产生的热块冲突比Oracle要严重多了,在高并发环境下,对热块冲突的优化还是需要下功夫的。在这一系列压测过程中,我发现了排在第二位的问题是WalBufferAccess的等待事件。从openGauss的源码上看,这个等待事件仅仅是pgstat里在使用,其他代码中并未出现这个等待事件。于是我在openGauss SIG群里咨询了一下。这是xlog在写日志的时候要统计WAIT_EVENT_WAL_BUFFER_ACCESS的计数的时候产生的等待事件。
开始我还以为这个WalBufferAccess 等待有点类似于Oracle的Redo Copy,在高斯里也把这个等待归类的IO里,不过这里似乎有一个误解。从官方文档上看,openGauss优化了WAL BUFFER写入的算法,采用了一种号称无闩锁控制机制。既然WAL BUFFER的写入已经是无锁模式的,这种无锁模式实际上还是需要一个轻量级的串行化机制,用来保护WAL BUFFER指针的,似乎这个等待事件与那个也没有关系。在原生态的PG数据库里,在同样并发情况下,不容易看到类似的等待事件。不过从等待时间上看,这个等待事件的等待时间永远为0,这就有点令人感到诧异了,任何等待事件既然发生不大可能等待时间永远为0吧,否则这个等待事件就没有什么意义了。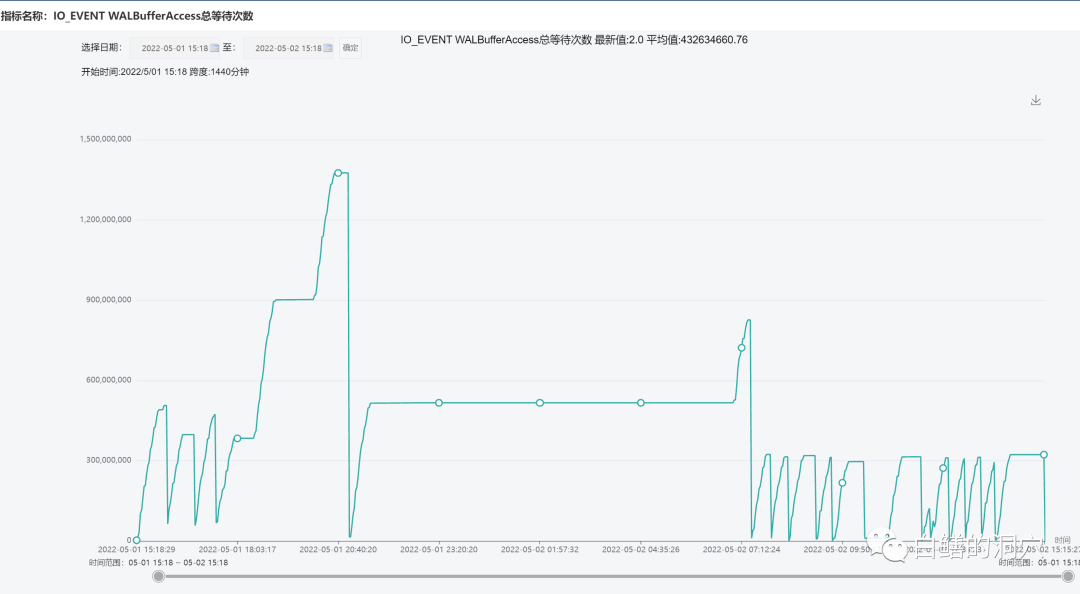

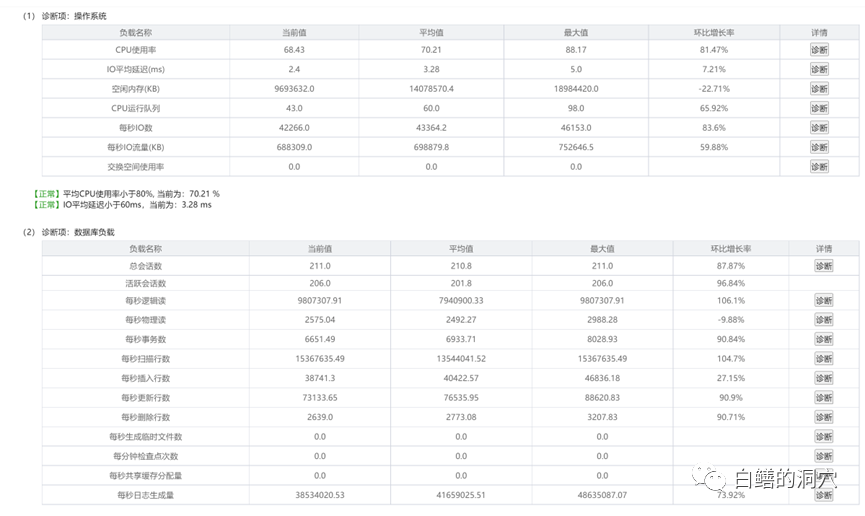
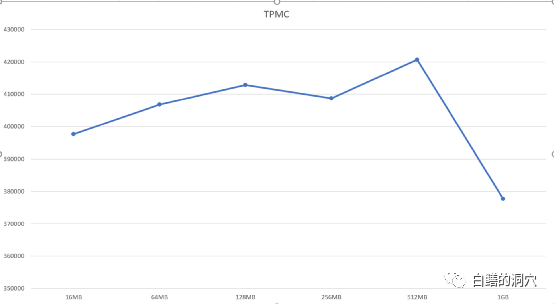
虽然这个等待事件似乎对性能影响不大,不过我们还是看到了一些和WAL相关的等待。于是我考虑针对WAL BUFFER的问题,进行一些优化的尝试。在优化WAL参数前我们可以看到tpmC指标大约在18万多。我和华为的朋友一起讨论了一下WAL优化的方案。针对openGauss,华为的朋友建议做下面的调整:2)walwriter_sleep_threshold = 50000,从而在高并发压测下,WALWRITER永远不会休眠;3)绑定WALWRITER的CPU,walwriter_cpu_bind=0,不过这个需要和线程池以及numa的设置同时进行;优化后,tpmC从18万提高到了20万多一点。还是有比较明显的提升的。随后我做了一个小实验,我设置20个WareHouse的场景,设置不同的WAL BUFFER大小,从16MB到1GB,压测线程数固定在80,压测20分钟,通过tpmTOTAL指标来更好地进行对比。可以看出,随着WAL BUFFER的加大,Benchmark是上升的。不过到了1GB的时候反而有个突然的下降。另外256MB的时候也出现了略微的下降,我没有仔细分析下降的原因。不过WAL BUFFER在适当大小的时候就会有不错的性能。这种设置和硬件配置,IO性能,业务场景,并发量,主要系统争用等都有关系。并不一定存在一个标准化的值。不过我们可以看出128MB之后,其实已经有了比较好的效果了。设置过大的WAL BUFFER对于一般的应用负载其实也没太大用处。以前我们测试PG数据库的时候,往往调整WAL BUFFER不会有太大的性能提升。本次测试并不是为了对比PG与高斯的性能,也不是为了研究高斯的热块冲突的优化方案,而是在尝试构建高斯的知识图谱的过程中遇到的几个小问题。通过和华为工程师的沟通,我们针对这两个等待事件的根因分析以及问题解决都找到了一些方法,这些方法将会更新到openGauss的知识图谱中去。大家以往在做数据库的极限测试的时候,都是按照厂家提供的配置以及设置方案去做的,实际上这种优化方案基本上对实际生产环境遇到的问题的解决没有太大的帮助。而在某些场景中发现问题后,在Oracle数据库上你可以通过MOS或者一些用户以前积累的经验和案例来参考分析。而在国产数据库或者开源数据库上,我们还远远没有形成这样的知识积累,因此总结出一系列性能监控,发现问题的方法,以及这些问题的针对性解决方案十分关键,也十分困难。今天这个实验室我通过自己的经验并在华为工程师的帮助下,形成了几条对openGauss此类场景的优化经验。只有不断地积累这些经验,才能把国产数据库用好。最后我在同一台服务器的同一块SSD盘上,使用一套12.3版本的原生态PG数据库做了一个类似的测试。发现其主要等待事件是行锁相关的,并没有出现特别严重的热块冲突相关的等待。openGauss和原生态PG之间的代码已经完全脱钩,因此一些PG原生版本的新的功能在openGauss中并没有引入,我手头目前没有9.X版本的PG的环境,因此暂时还无法进行对比测试。这个问题还十分复杂,至此也并没有彻底解决,还有一些问题留待以后再慢慢测试和分析吧。不过这两天的测试收获还是很多的,以前Oracle数据库的等待事件分析方法对于PG系列的开源/国产数据库依然有效,只不过需要花更多的时间去一点点的解析,才能获得准确的知识,用于实际生产环境的分析与优化工作中。还好,PG只有一百多个等待事件,经过openGasuss扩展后,也不过300多个。今天稍晚点我要出发去徒步几天,上班后不一定能及时更新公众号号了,等我回来后再和大家分享关于数据库优化的经验吧。因为疫情我放弃了去新疆徒步的计划,准备去雨崩村走一走,休闲休闲,这是最近4年里第四次去梅里雪山,第二次去雨崩村了。