




Oracle 的 SQL 查询中的关联方式有三种:嵌套循环关联(Nested Loop Join)、合并关联
(Merge Join)和哈希关联(Hash Join)。其中,嵌套循环是最灵活的关联方式,它适应与任何一种情况下的关联;合并关联要求关联的数据集本身已经按照关联键值排序;而哈希关联则需要额外 的内存空间以建立哈希映射表,内存不足时,还需要临时磁盘空间读写临时数据。它们的实现方式 不同,也就决定了它们的代价估算方式不同。
对于所有关联操作,一个影响它们代价的共同因素是关联数据集的势(Cardinality,CARD[Join]) 及关联选择率(Join Selectivity,JOINSEL)。
6.9.1 关联选择率
关联选择率由内、外表上的关联字段的选择率决定,采用两者中的选择性最强的一个。
JOINSEL = LEASTEST(COLSEL[Outer], COLSEL[Inner])
其中,COLSEL[Outer]为外表上关联字段的选择率;COLSEL[Inner]为内表上关联字段的选择率。计算方式和无柱状图数据的计算方式相同。并且,如果存在多个关联字段,组合计算公式也与前面 章节介绍的公式相同。
要注意的是,在 10gR2 版本之后,对于等于匹配的关联字段,如果其中某张表上存在一个连接索引(Concatenated Index,即由表的实际字段拼接组合的索引,如(ColA,ColB)),其所有字段为这
些等于匹配的关联字段,那么关联选择性则会采用 1/NDK,其中 NDK(Number of Distinct Keys)为索引的键值数。
而在 11g 以后,如果多个字段上存在扩展统计数据,优化器则会考虑采用扩展统计数据计算关联选择率。
o 关联数据集的基数(Join Cardinality,CARD[Join])
关联数据集的元素为内、外数据集中符合匹配条件的所有元素的组合,其基数的计算公式为:
CARD[Join] = CARD[Outer]*CARD[Inner]*JOINSEL
其中,CARD[Outer]外数据集的基数;CARD[Inner]为内数据集的基数。内、外数据集的基数由表 数据记录数乘以查询中谓词条件的选择率得来。
我们下面分别介绍三种关联操作的代价估算过程。
6.9.2 嵌套循环关联代价计算
嵌套循环关联实现过程为:选择一个数据集作为外循环数据集、另外一个数据集作为内循环数 据集;每读取外循环的一条数据就遍历一次内循环数据集,以对关联字段进行匹配。
IO 代价计算
由于嵌套循环关联的数据集的来源是子操作返回的数据集,关联本身是不会产生 IO 操作的。它的 IO 代价代表的是:关联操作过程中,所调用子操作所产生的 IO 代价的综合。结合嵌套循环关联的实现过程,不难得出其 IO 代价的基本计算公式:
IOCOST[NLJ] = IOCOST[Outer] + CARD[Outer]*IOCOST[Inner]
其中,CARD[Outer]是外循环数据集的基数,它决定了内循环数据集所对应的子操作的调用次数。但是,从我们之前的 IO 计算公式可以知道,单个表的 IO 代价值是一个约等于(使用 CEIL 或
ROUND 函数)得出的整数。对于单次的单表操作而言,这一误差是可以接受的。但是,在关联代
价公式中,这一数值再乘以 CARD[Outer],则会导致误差被放大,从而影响优化器选择关联方式的正确性。在 10g 中,嵌套循环关联 IO 代价公式根据内操作的方式不同,调整了取整函数的位置, 使得估算结果更加准确。
o 全表扫描
回顾单个表的全表扫描 IO 代价估算公式,Oracle 会根据参数配置对结果使用 CEIL 取整并加上额外的 1 次 IO。在嵌套循环关联代价计算公式中,取整函数和额外 IO 都被放置在与 CARD[Outer]相乘的结果之外:
IOCOST[NLJ] = IOCOST[Outer] + CEIL(CARD[Outer] * (TABBLKS[Inner]/MBRC*MREADTIM/SREADTIM))+1
示例:


计算结果:
IOCOST[NLJ] = IOCOST[Outer] + CEIL(CARD[Outer] * (TABBLKS[Inner]/MBRCMREADTIM/SREADTIM))+1
= 204 + CEIL(47585 * (TABBLKS[Inner]/MBRC(IOSEEKTIM+MBRCOPTBLKSIZ/IOTFRSPEED)/(IOSEEKTIM+OPTBLKSIZ/IOTFRSPEE D)))+1
= 204 + CEIL(47585 * (69/16(8.381+16*8192/4096)/(8.381+8192/4096)))+1
= 798452
o 唯一索引匹配
当内操作为唯一索引匹配(INDEX UNIQUE SCAN)时,优化器认为有 2 个索引块是从缓存中读取的。并且,根据唯一索引匹配本身的特点,一次操作仅会读取一个表数据块。嵌套循环关联代价 的估算与关联的索引字段在内外数据集上选择率相关。
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * (BLVL - 2 + 1 + LEAST(1,
SEL1[Outer]/SEL1[Inner])LEAST(1, SEL2[Outer]/SEL2[Inner])…LEAST(1, SELn[Outer]/SELn[Inner])))
= IOCOST[Outer] + ROUND(CARD[Outer] * (BLVL - 1 + LEAST(1,
SEL1[Outer]/SEL1[Inner])LEAST(1, SEL2[Outer]/SEL2[Inner])…LEAST(1, SELn[Outer]/SELn[Inner])))
其中,SEL1[Inner]为第一个字段在内数据集上的选择率,SEL1[Outer]为第一个字段在外数据集
上的选择率,以此类推。考虑到有 2 个索引块是从缓存中读取的,因此减 2;仅读取一个表数据块, 因而加 1.
示例:


计算结果为:
IOCOST[NLJ] = 204 + ROUND(47585*(1-1 + LEAST(1,(1/22)/(1/25))*LEAST(1,(1/29450)/(1/17139))))
= 27897
o 索引范围扫描
当内操作为索引范围扫描(INDEX RANGE SCAN)且无需访问表(TABLE ACCESS BY INDEX ROWID) 时,优化器认为会有 1 个索引数据块是从缓存中读取的。嵌套循环关联代价的估算采用的是基本代价计算公式。
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * IOCOST[Inner])
= IOCOST[Outer] + ROUND(CARD[Outer] * ROUND(BLVL - 1 + AVGLBLK))
= IOCOST[Outer] + ROUND(CARD[Outer] * ROUND(BLVL - 1 + LEAFBLK*INDACCSEL))
其中,BLVL 为索引枝节点层数;AVGLBLK 为平均每个键值对应的叶子数据块数;LEAFBLK 为叶子节点数;INDACCSEL 为索引范围选择率。
示例:
计算结果为:
IOCOST[NLJ] = 3 + ROUND(41ROUND(1-1+771/25))
= 167
o 索引缓存(Index Caching)的影响
我们知道,索引数据块被读入缓存后,是放在缓存链表的前端的,可以使得后续的访问可以从内存中直接读取,从而避免磁盘读。对于嵌套循环关联,内操作是被重复操作的。当内循环操作为 索引范围扫描时,一些索引数据块是会被缓存在内存中被后续循环直接读取的。Oracle 可以通过参数 optimizer_index_caching 设置(系统或者会话级别)这一缓存命中率,使得优化器计算得到更小的嵌套循环关联 IO 代价。引入索引缓存命中率(INDCACHE)后,估算公式变为:
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * ROUND((BLVL + LEAFBLKINDACCSEL)(100-INDCACHE)/100))
例如,改变上例中的索引缓存命中率:

 计算结果为:
计算结果为:
IOCOST[NLJ] = 3 + ROUND(41ROUND((1+771/25)*(100-60)/100))
= 85
o 索引范围扫描 + 表访问
当嵌套循环的关联字段为索引字段,且内操作需要由索引范围扫描获得的 ROWID 去访问表以读取其它字段时,Oracle 不会立即访问表,而是先由索引字段关联后,再通过关联数据集中的
ROWID 去读取表。这样做的好处是,可以明显提高索引的缓存命中率。其相应的 IO 代价估算公式为:
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * (BLVL - 1 + AVGLBLK + CEIL(CLUF*INDACCSEL[Inner])*FLTSEL[Outer]/INDACCSEL[Inner])
其中,BLVL 为索引枝节点层数;AVGLBLK 为平均每个键值对应的叶子数据块数;CLUF 为索引
簇集因子;INDACCSEL[Inner]为内表的索引访问选择率;FLTSEL[Outer]为关联字段在外表上的选择率。
示例:
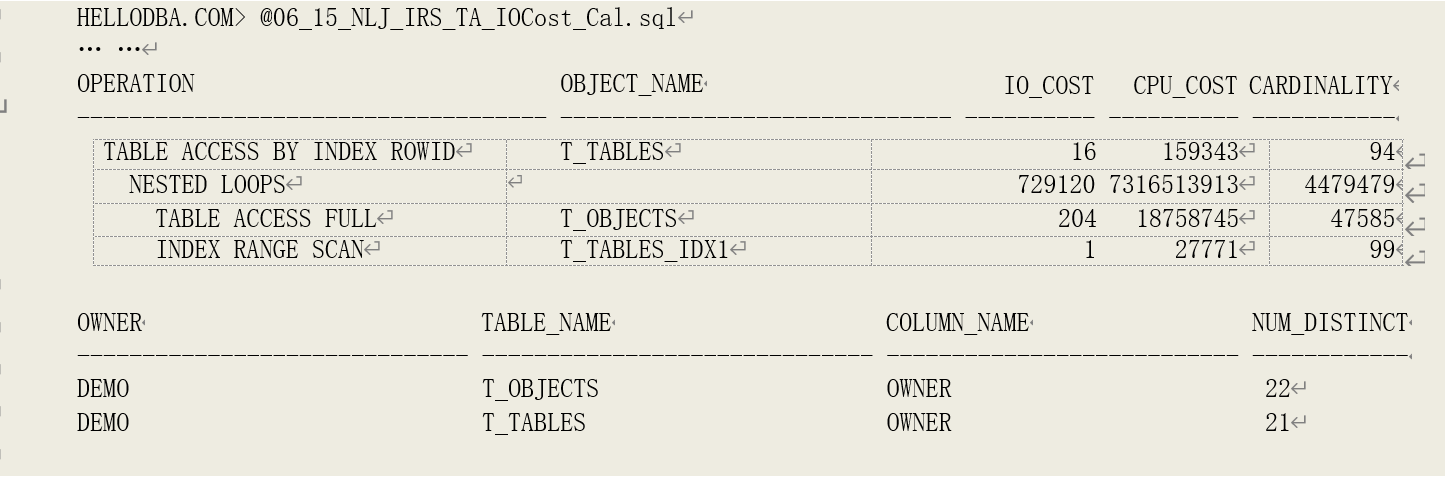
计算结果为:
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * (BLVL - 1 + AVGLBLK + CEIL(CLUFINDACCSEL[Inner])FLTSEL[Outer]/INDACCSEL[Inner])
= 204 + ROUND(47585(1-1+1+CEIL(315/21)21/22))
= 729120
o 索引缓存(Index Caching)的影响
索引缓存命中率同样会影响索引扫描的 IO 代价估算,从而对关联 IO 代价产生影响:
IOCOST[NLJ] = IOCOST[Outer] + ROUND(CARD[Outer] * (ROUND((BLVL + AVGLBLK)(100- INDCACHE)/100) + CEIL(CLUFINDACCSEL[Inner])*FLTSEL[Outer]/INDACCSEL[Inner])
CPU 代价计算
同样,CPU 代价估算也与内操作类型相关,并且在单操作代价估算公式的基础上,调整取整函数以及匹配字段的选择率,得到嵌套循环关联下的 CPU 代价估算公式。
o *全表扫描
内操作为全表扫描时,调整取整函数,得到嵌套循环关联下的 CPU 代价估算公式。
#CPUCYCLES[NLJ] = #CPUCYCLES[Outer] + ROUND(CARD[Outer] * #CPUCYCLES[Inner])
其中,#CPUCYCLES[Inner]为内操作的全表扫描 CPU 总指令数的计算公式:
#CPUCYCLES[Inner] = (#BLKS-CACHEBLK)(0.32OPTBLKSIZE + 3650) + #BLKS850 + CARD[Inner]130 + CARD[Inner]( GREATEST(1, MAXFLTCPOS) + SELGREATEST(0, MAXSELCPOS -
MAXFLTCPOS) )*20 + CARD[Inner]*FLTCYCLES
以前面例子为例,计算 CPU 代价(表 T_TABLES 的数据块数为 69,数据记录数为 2071):
#CPUCYCLES[Inner] = 69*(0.328192 + 3650) + 69850 + 2071130 + 2071(1*6)*20 + 0
= 1009129.36
#CPUCYCLES[NLJ] = 18758745 + ROUND(47585 * 1009129.36)
= 48038179341
结果与执行计划中数据完全一致。
o 唯一索引匹配
内操作为唯一索引匹配时,要考虑到有 2 个索引数据块是从缓存中读取,并且仅会读取一个叶子数据块和一条索引记录。如果还需要有索引 ROWID 访问表,也仅会读取一个表数据块和一条记录,并且考虑匹配字段选择率的影响。相应的内存操作的 CPU 代价计算公式为:
#CPUCYCLES[Index Unique Scan] = ((BLVL-2+1)(0.32OPTBLKSIZE + 3650 + 850)) + (2850) + 1200)
= ((BLVL-1)(0.32OPTBLKSIZE + 3650 + 850)) + (2850) + 1200)
#CPUCYCLES[AccessTableByRowid] = ((1*(0.32OPTBLKSIZE + 3650 + 850)) + 1130 + 1*GREATEST(MAXINDCPOS, MAXSELCPOS, MAXFLTCPOS)*20)*LEAST(1,
SEL1[Outer]/SEL1[Inner])LEAST(1, SEL2[Outer]/SEL2[Inner])…LEAST(1, SELn[Outer]/SELn[Inner])
以前面例子为例,计算 CPU 代价(索引 T_CONSTRAINTS_PK 的索引树高度为 1):
#CPUCYCLES[Index Unique Scan] = ((1-1)(0.328192 + 3650 + 850)) + (2850) + 1200)
= 1900
#CPUCYCLES[AccessTableByRowid] = ((1*(0.328192 + 3650 + 850)) + 1130 + 1*GREATEST(2, 4, 0)*20)*LEAST(1, (1/29450)/(1/17139))
= 4266.67403
最终关联操作的 CPU 代价为:
#CPUCYCLES[NLJ] = 18758745 + ROUND(47585 * (1900+4266.67403))
= 312199929
o 索引范围扫描
内操作为索引范围扫描时,要考虑到有 1 个索引数据块是从缓存中读取。
#CPUCYCLES[Index Range Scan] = ((BLVL-1+CEIL(LBLKSINDACCSEL))(0.32OPTBLKSIZE + 3650 + 850)) + (1850) + CEIL(INDROWS*INDACCSEL)*200
以前面例子为例,计算 CPU 代价(索引 T_CONSTRAINTS_IDX3 的索引树高度为 1,叶子数据块数为 77,索引记录数为 17188。表 T_CONSTRAINTS 的字段 OWNER 的选择率为 1/25):
#CPUCYCLES[Index Range Scan] = ((1-1+CEIL(771/25))(0.328192 + 3650 + 850)) + (1850) + CEIL(17188*1/25)*200
= 166935.76
最终关联操作的 CPU 代价为:
#CPUCYCLES[NLJ] = 41196 + ROUND(41 * 166935.76)
= 6885562
o 索引缓存(Index Caching)的影响
当引入了考虑索引缓存(设置了参数 optimizer_index_caching 大于 0)时,会对代价公式中的数据块读取的 CPU 指令数产生影响。
#CPUCYCLES[Index Range Scan] = ((BLVL+CEIL(LBLKSINDACCSEL))(100-
INDCACHE)/100*(0.32OPTBLKSIZE + 3650 + 850)) + CEIL(INDROWSINDACCSEL)*200
以前面例子为例,计算 CPU 代价(索引缓存命中率为 60%)
#CPUCYCLES[Index Range Scan] = ((1+CEIL(771/25))(100-60)/100*(0.328192 + 3650 + 850)) + CEIL(171881/25)*200
= 151842.88
最终关联操作的 CPU 代价为:
#CPUCYCLES[NLJ] = 41196 + ROUND(41 * 151842.88)
= 6266754
o 索引范围扫描 + 表访问
如果内操作为索引范围扫描,且还需要继续由索引 ROWID 访问表的话,还需要考虑关联字段选择率对表访问 CPU 代价的影响:
#CPUCYCLES[AccessTableByRowid] = ((CEIL(CLUFINDACCSEL[Inner])(0.32OPTBLKSIZE + 3650 + 850)) + CEIL(INDROWSINDACCSEL)130 + CEIL(INDROWSINDACCSEL)*GREATEST(MAXINDCPOS, MAXSELCPOS, MAXFLTCPOS)*20)*FLTSEL[Outer]/INDACCSEL[Inner]
以前面例子为例,计算 CPU 代价(索引 T_TABLES_IDX1 的索引树高度为 1,叶子数据块数为 5, 索引记录数为 2071,簇集因子为 315。表 T_TABLES 的字段 OWNER 的选择率为 1/21,表 T_OBJECTS 的字段 OWNER 的选择率为 1/22):
#CPUCYCLES[Index Range Scan] = ((1-1+CEIL(51/21))(0.328192 + 3650 + 850)) + (1850) + CEIL(20711/21)200
= 27771.44
#CPUCYCLES[AccessTableByRowid] = ((CEIL(3151/21)(0.328192 + 3650 + 850)) + CEIL(20711/21)130 + CEIL(20711/21)*GREATEST(1, 6, 0)20)(1/22)/(1/21)
= 125591.072727273
最终关联操作的 CPU 代价为:
#CPUCYCLES[NLJ] = 18758745 + ROUND(47585 * (27771.44+125591.072727273))
= 7316513913
