




ORACLE和MYSQL是目前市面上使用最广泛的两款关系型数据库软件,因为两款数据库在存储过程,函数,触发器和sql等语法上存在较大差异,所以迁移一套完整的ORACLE到MYSQL,需要处理好不同数据类型的差异和各种编码的差异。此文章主要分享了迁移数据上的一些方法和数据类型上的一些区别对比和选择。
源数据库(ORACLE数据库):
ip:192.169.100.107单机
目标数据库(mysql数据库),目标端需要安装ORACLE客户端,或者直接复制ORACLE的lib库到目标库。
ip: 192.169.100.247单机
mysql中的date类型为日期类型(YYYY-MM-DD) 范围:1000-01-01/9999-12-31 ,不包含时间值,所以可根据情况判断使用date类型还是datetime类型替换oracle的date类型(取决于源端是否包含具体时间),推荐使用datetime 替换date类型。
如果oracle源端使用的日期格式默认值时(default sysdate),MYSQL端只能使用使用timestamp DEFAULT CURRENT_TIMESTAMP,因为msql 只有timestamp 才能使用默认时间为系统时间。
mysql 端默认字符集推荐使用:utf8mb4,具体根据情况而定。
[ load的方式迁移数据 ]
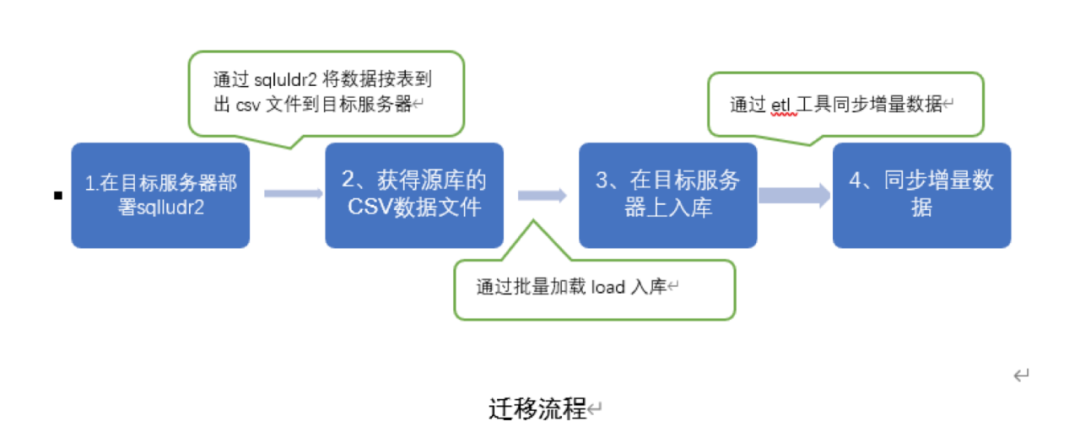
对于生产环境的数据库,动辄上TB甚至PB级的数据量和数千张表,对于这样的数据量和表的数量,我们就需要考虑比较快捷的方式去迁移数据。
数据的导出有很多有方式,比如oralce可以使用:PL/SQL、toad、NavicatforORACLE或者其他工具导出数据,但是这些工具往往会因为数据量的问题而受到各种局限,对于少量的数据时,使用这些工具是比较合适的,但是当数据量达到海量时,不仅导出速度无法保证,而且无法直接落地到服务器,从而大大的限制了我们对数据的处理。
因此我推荐一个小的工具包sqlload2(或者也可以直接使用ketle将数据直接导出),该工具可快速的将源数据导出成为txt/csv(推荐csv格式,csv格式可以更好的处理分隔符和封闭符的问题),因为在正式环境中,导入的数据的正确性尤为重要,生产数据又可能出现各种特殊的符号,仅仅使用传统的逗号作为分隔符已无法完全保证数据在导出或者导入时能正确的分隔,所以需要同时使用分隔符和封闭符,这样才能保证数据的正确性,经过多次验证建议使用特使的16进制字符:0x07作为分隔符,并且该工具支持并行导出、以及多种分隔符、封闭符、自动拆分文件和通配符等等丰富的功能。
(以下模拟一个源库包含大量数据,并且业务无法长时间停止,需要增量更新)
ORACLE文件导出工具sqlludr2
链接:https://pan.baidu.com/s/1JVo1BETvTJXPQQHburfVOg提取码:fxwf
ETL工具ketle
kettle可自行到官网下载:https://www.hitachivantara.com/en-us/products/data-management-analytics.html?source=pentaho-redirect(kettle为开源软件,后续也有推出收费版本)
使用sqlldr2导出数据并使用load加载数据:
安装ORACLE客户端,并配置好环境变量:
安装之后创建network/admin/文件夹,然后创建文件tnsnames.ora(用于连接源端ORACLE数据库)
zkl =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = IP地址)(PORT = 1521))
)
(CONNECT_DATA =
(SID = orcl )
(SERVER=DEDICATED )
(INSTANCE_NAME = testdb1)
)
配置好oracle的环境变量,指定lib 库
export ORACLE_BASE=/u01/app/oracleexport ORACLE_HOME=$ORACLE_BASE/product/11.2.0/dbhome_1export PATH=$PATH:$ORACLE_HOME/binexport ORACLE_SID=orclexport LD_LIBRARY_PATH=$ORACLE_HOME/lib:lib:/usr/libexport CLASSPATH=$ORACLE_HOME/JRE:$ORALCE_HOME/jlib:ORACLE_HOME/rdbms/jlib
上传sqlludr2工具并使用如下命令导出文件
./sqluldr2_linux64_10204.bin USER=用户名/密码@IP地址:端口号/数据库名称 query="查询语句" table=表名称 head=no charset=utf8 field=0x07 file=/sqlfile^CJ_WXMACINFO.csv log=/sqlfile/log.txt file=/sqlfile/data/WJ_WXMACINFO%B.CSV size=20MB safe=yes
常用参数说明:(更多参数可以参考:./sqluldr2_linux64_10204.binhelp=yes)
query:query参数如果整表导出,可以直接写表名,如果需要查询运算和where条件,query=“sql文本”,也可以把复杂sql写入到文本中由query调用。head:是否导出表头charset:指定字符集field:默认是逗号分隔符,通过field参数指定分隔符file:导出的文件名log:日志文件size:对于大表可以输出到多个文件中,指定行数分割或者按照文件大小分割rows=500000
示例:(导出db库里面的test表里面的前10条数据,并且分4个并行线程,导出的文件每20M截断)
./sqluldr2_linux64_10204.bin USER=test/test@10.10.10.10/db query="select *+ parallel(4) */ *from test where rownum<=100000" table=test head=no charset=utf8 field=0x07 file=/tmp/test.csv log=/tmp/log.txt file=/tmp/test%B.CSV size=20MB safe=yes
后续可写入脚本批量导出。
使用load在目标数据库批量入库:
load data infile '/tmp/test.csv' into table db.test character set utf8 fields terminated by '0x07' enclosed by '"';
kettle简介
ETL是数据抽取(Extract)、清洗(Cleaning)、转换(Transform)、装载(Load)的过程。是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。(典型的ETL工具:商业软件:Informatica、IBM Datastage、Oracle ODI、Microsoft SSIS…开源软件:Kettle、Talend、CloverETL、Kettle,Octopus …)
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
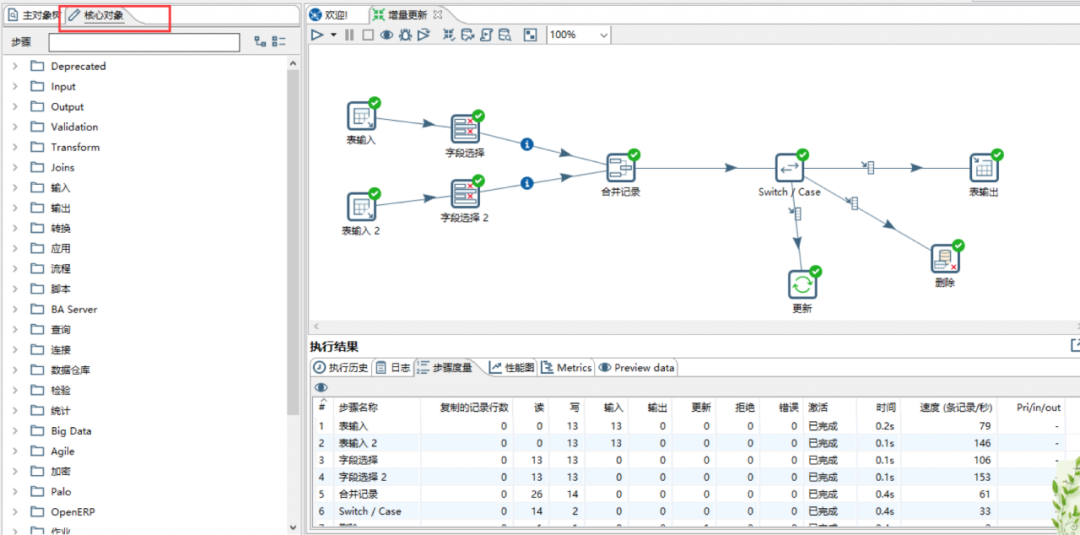
新建转换,配置增量更新:
在核心对象中分别选择两个表输入,作为旧数据源和新数据源,分别配置数据库连接;
字段选择用来规范来源数据的格式和类型;
合并记录用于对比新旧数据源的差异,并将数据对比的结果放到标志字段中;
Switch/Case用来决定差异的数据是应该更新还是修改还是删除。
标志字段值说明:

转换调用
1) windows下调用kettle程序:
cd C:\soft\kettle\data-integration kitchen /file C:\soft\job名称 /level Basic logfile E:\timing.log @pause |
2) linux下调用kettle程序:
./kitchen.sh -rep 192.168.0.13.PDI_Repository -user username -pass password -dir /目录名称 -job job名称 -level=basic>>/log/job.log |
至此使用load+kettle的的迁移和增量更新配置完成。
