




上面我们介绍了
urllib
模块的使用,有一个比urllib
更加“人性化”的模块,那就是requests
库,使用它可以更加便捷的发起各种请求。
1、安装requests
pip install requests复制
2、python发送get请求
(1)发送简单请求
import requests
jier = requests.get('http://www.baidu.com')
print(jier.text)复制
输出为一个网页的html
代码;
(2)添加Header
import requests
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
jier = requests.get('http://www.baidu.com', headers=Header)
print(jier.text)复制
输出为一个网页的html
代码;
(3)添加请求参数
import requests
jier = {'wd': '运维家的博客'}
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
suner = requests.get('http://www.baidu.com/s?', params=jier, headers=Header)
print(suner.text)复制
输出为一个网页的html
代码;
(4)查看响应内容
text
:这个是str
的数据类型,是requests
库将response.content
进行解码的字符串,当有时候text
放回的格式乱码的时候,可以采用下面的content
的方式指定编码格式;
content
:这个是直接从网络上面抓取的数据,没有经过任何解码,所以是一个bytes
类型;
import requests
jier = {'wd': '运维家的博客'}
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
suner = requests.get('http://www.baidu.com/s?', params=jier, headers=Header)
# 使用text
print(suner.text)
# 使用content
print(suner.content.decode('utf-8'))复制
输出为一个网页的html
代码;
(5)查看完整URL
import requests
jier = {'wd': '运维家的博客'}
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
suner = requests.get('http://www.baidu.com/s?', params=jier, headers=Header)
print(suner.url)复制
输出内容如下:
http://www.baidu.com/s?wd=%E8%BF%90%E7%BB%B4%E5%AE%B6%E7%9A%84%E5%8D%9A%E5%AE%A2复制
(6)查看响应头字符编码
import requests
jier = {'wd': '运维家的博客'}
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
suner = requests.get('http://www.baidu.com/s?', params=jier, headers=Header)
print(suner.encoding)复制
输出内容如下:
utf-8复制
(7)查看响应码
import requests
jier = {'wd': '运维家的博客'}
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
suner = requests.get('http://www.baidu.com/s?', params=jier, headers=Header)
print(suner.status_code)复制
输出内容如下:
200复制
3、python发送post请求
(1)发送简单请求
import requests
jier = requests.post('http://www.baidu.com')
print(jier.text)复制
输出结果为一个网页的html
代码;
(2)发送带参数的请求
这里我们再次使用
httpbin
网站,这次就不介绍如何查看方法了,之前说过好几次了,直接用。
import requests
Test_Url = 'http://httpbin.org/post'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Data = {'name': 'yunweijia', 'type': 'gongzhonghao'}
jier = requests.post(Test_Url, headers=Header, data=Data)
print(jier.text)复制
输出结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "yunweijia",
"type": "gongzhonghao"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "32",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-62822e2b-5a2c632c1d88fe0f597edd6f"
},
"json": null,
"origin": "223.71.97.14",
"url": "http://httpbin.org/post"
}复制
其他的参数和GET
一样,直接使用即可,这里就不再一一举例了。
4、Requests使用代理
(1)未使用代理之前
import requests
Test_Url = 'http://httpbin.org/post'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
jier = requests.post(Test_Url, headers=Header)
print(jier.text)复制
输出信息如下:
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-62823bc1-6bcdae190bb802f8616c3032"
},
"json": null,
"origin": "223.71.97.14",
"url": "http://httpbin.org/post"
}复制
(2)使用代理之后
import requests
Test_Url = 'http://httpbin.org/post'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Proxy_Ip = {'http': '188.131.233.175:8118'}
jier = requests.post(Test_Url, headers=Header, proxies=Proxy_Ip)
print(jier.text)复制
输出信息如下:
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-62823bc1-6bcdae190bb802f8616c3032"
},
"json": null,
"origin": "188.131.233.175",
"url": "http://httpbin.org/post"
}复制
5、python获取返回的cookie
如果我们请求的网页会返回cookie
,例如登录的时候,返回cookie
,然后我们携带cookie
去请求新的地址,我们该如何保存呢?示例如下:
import requests
Test_Url = 'http://httpbin.org/cookies/set?name=yunweijia'
jier = requests.get(Test_Url)
print(jier.text)
print(jier.cookies)
print(jier.cookies.get_dict())复制
没有找到合适的网站来做示例代码,但是写法是这样的。
6、python获取返回的session
我们还是按照使用rullib
访问博客园的示例,来使用requests
重写一下;
import requests
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Login_Url = 'https://passport.cnblogs.com/user/signin'
data = {'input1': '2276845534@qq.com', 'input2': 'yunweijia@123', 'remember': True} # 我的参数是错的,使用自己的即可
session = requests.session()
session.post(Login_Url, data=data, headers=Header)
jier = session.get('https://www.cnblogs.com/yunweijia/')
print(jier.text)复制
返回的是一个网页的heml
代码,如下样式:
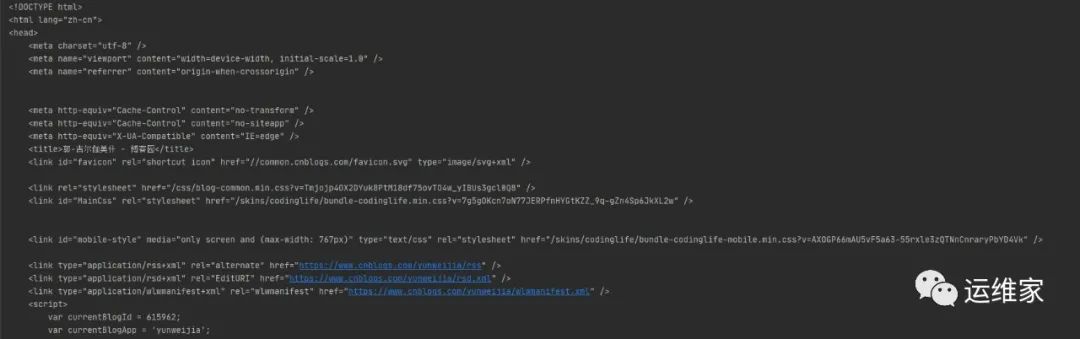
7、访问不被认证的HTTPS网站
只需要添加一个参数
verify=False
即可;
import requests
jier = requests.post('https://ceshi.com/', verify=False)
print(jier.content.decode('utf-8'))复制
至此,本文结束。更多相关内容,每日更新。

往期推荐
文章转载自运维家,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
