




挑 战
你可能听说过这样一句话,“数据是新的石油”。 这是因为数据是任何组织系统做业务决策系统时的核心。但是您需要的数据并不总是只在一个地方,就像常规、普通的关系型数据库管理系统一样,通常,它分散在不同的关系型数据库管理系统和其他数据孤岛中。
因此,遇到数据有各种不同来源的情况并不少见,DBA或数据工程师需要采取一种解决方案,将所有相关数据拉到一个集中的位置来进行进一步分析。
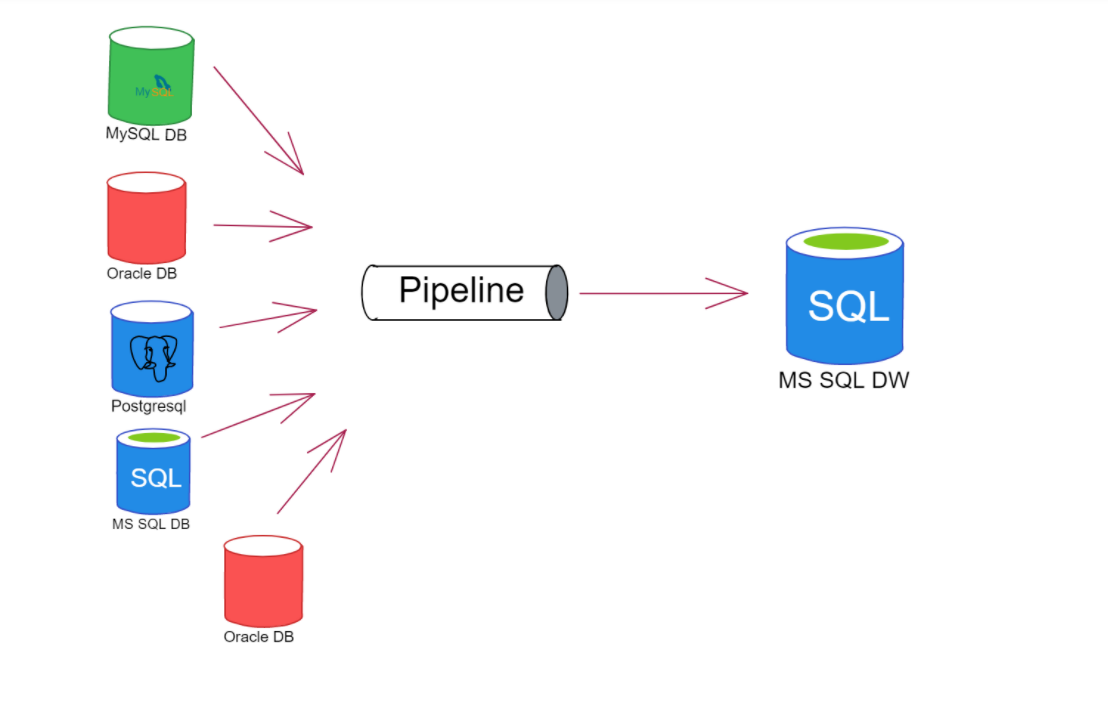
(图一:主流数据来源详情图)
最近,我们的一位客户在 AWS PostgreSQL RDS 实例中获得了销售数据,需要将这些数据(更准确地说是一组表)复制到(几乎是实时的)使用 MS SQL Server 的 Azure VM 中的一些表中。遗憾的是,异构复制被标记为“已弃用”,它只能在 SQL Server 和 Oracle 之间工作,批处理中不允许使用 PostgreSQL。此外,PostgreSQL端没有原生异构复制,这只能通过使用第三方工具或在高工作量模式下手动实现,通过使用触发器创建CDC(更改数据捕获)机制,然后从控制表中提取数据。
这听起来很有趣,但时间成本较多,开发这样的解决方案需要相当长的时间。简而言之,必须使用另一种解决方案来实现所需的数据移动。
可行性措施
上方图一中展现了一个可行的方案,但没有展示解决方案,如哪个工具可以用作管道。毕竟在大数据场景有许多工具可以实现这一目标,但没有一个具有Kafka的优势。
最初,Apache Kafka被设计成一个像应用程序一样的消息队列(还记得IBM 消息队列系列,或者SQL Server 服务端吗?这里可以引用Confluent对它的最佳定义:“Apache Kafka是一种社区分布式事件流技术,能够每天处理数万亿个事件”。DBA的想法是:“好吧,流媒体必须像复制一样,但规模很大!这是准确的,但流系统需要能够从许多不同的数据源引入数据,并在各种数据端点上传递其消息。
我们可以从许多工具中进行选择来实现这一目标,Azure Event Hubs或AWS Kinesis,甚至是Confluent Cloud中管理的Kafka。但是为了了解在引擎盖下是如何工作的,并且由于它们都有相似的背景(这是Apache Kafka开源代码)或具有相同的目标,我们决定向客户展示如何从头开始设置环境,而无需任何用于流处理的托管服务。
因此,上一张图片将如下所示:
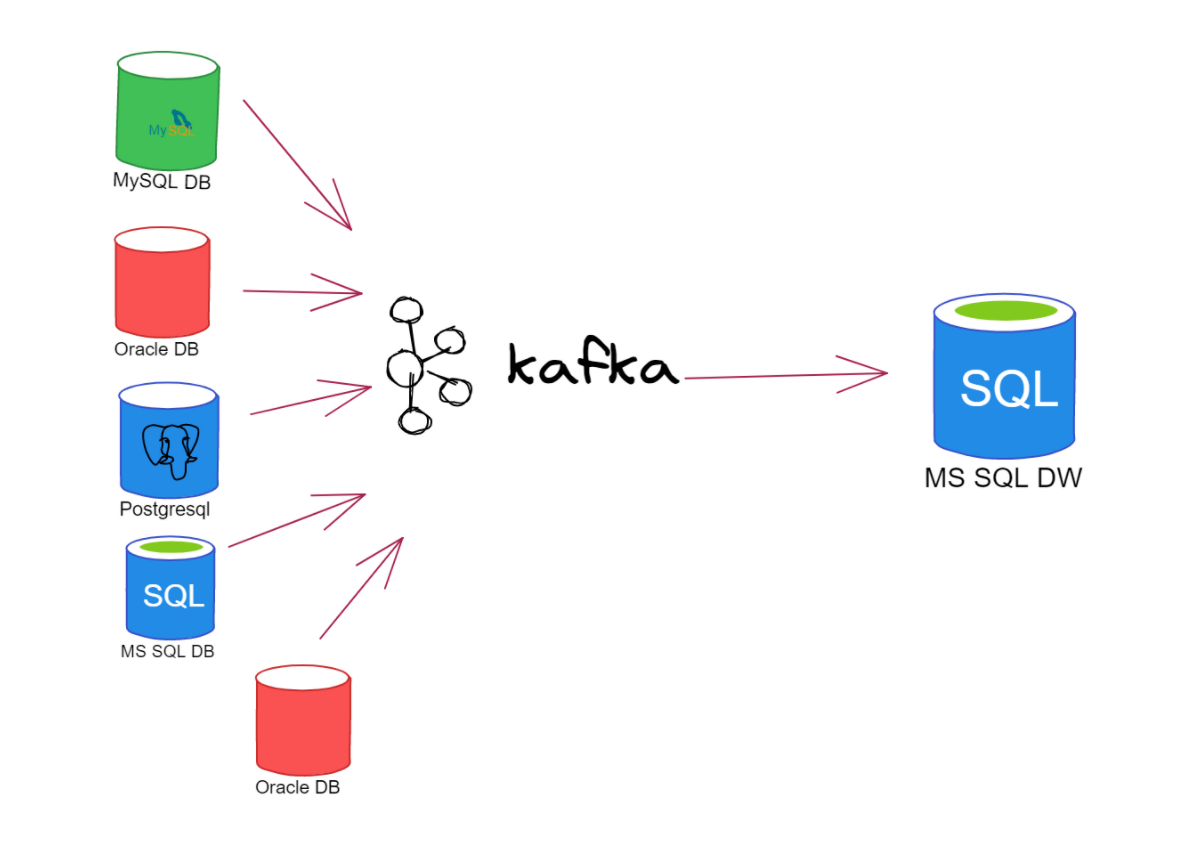
(图二:使用 Kafka 处理多个来源并将消息传递到一个或多个目的地)
简单介绍一下,Apache Kafka 的基本组件有:
消息: Kafka 中最小的数据单元,从DBA的角度来看,消息就是db表中的一行。就 Kafka 而言,消息是一个字节数组。
模式: 伴随消息的结构,因此它们可以被消费应用程序理解。
主题: 消息分为主题。在DBA世界中,这相当于一张表,以仅附加的方式从头到尾按顺序读取消息。
生产者和消费者: 还记得 SQL Server 复制发布者和订阅者吗?这里的想法非常相似,但是Kafka有能力同时处理多个生产者和消费者。
代理和集群: 单个Kafka服务器是一个“代理”。它从生产者那里接收消息,向它们写入偏移量并将它们保存在磁盘上。它还将在消费者请求消息时为他们提供服务。一般来说,在生产环境中,代理是集群的一部分。
连接器: Apache Kafka有许多用于处理消费者和生产者的连接器(可能是接收器类型)。有多种连接器可供免费或购买。您可以在 Confluent 网页:(https://www.confluent.io/product/confluent-connectors) 中找到其中的大部分。
总之,Kafka 是该任务的首选工具,我们将从头开始为数据移动创建整个环境。有关更多信息,请访问此处:https://kafka.apache.org/documentation。
架构
为了实现流功能并查看数据流的实际效果,我们将使用来自PostgreSQL DB的一组表作为源,来自SQL Server的一组表作为目标,Apache Kafka将充当“复制机制”。要连接到Postgres并检测其数据更改(CDC),还需要一个连接器插件。在这种情况下,我们将使用Debezium,因为它也是开源的,并且从头开始构建,以便尽可能轻松地与Kafka一起运作。
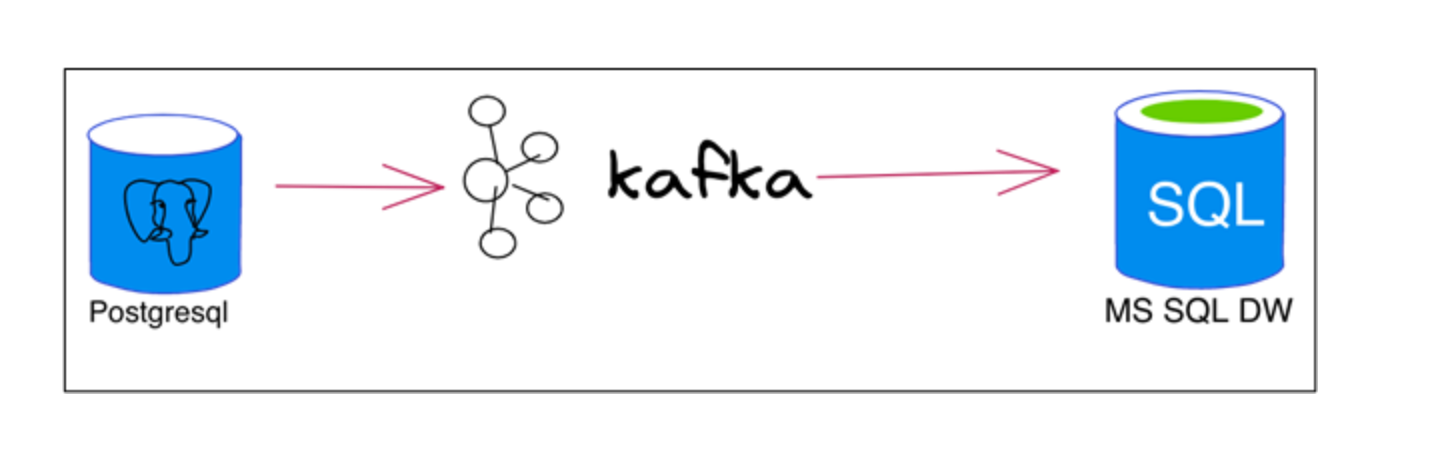
(图三:将数据从Postgres移动到MS SQL简图)
深入研究一下细节,在本文章系列的最后,我们应该有:
一个Linux VM,它具有Postgresql实例和Kafka二进制文件,理想情况下具有互联网连接(我们将使用Confluent Cli使部署不那么复杂)。Debezium for Postgres 也将安装在此 VM 中。具有 MS SQL SERVER 实例的 Windows VM(或本地)。因此,我们的架构应该看起来更像图4。
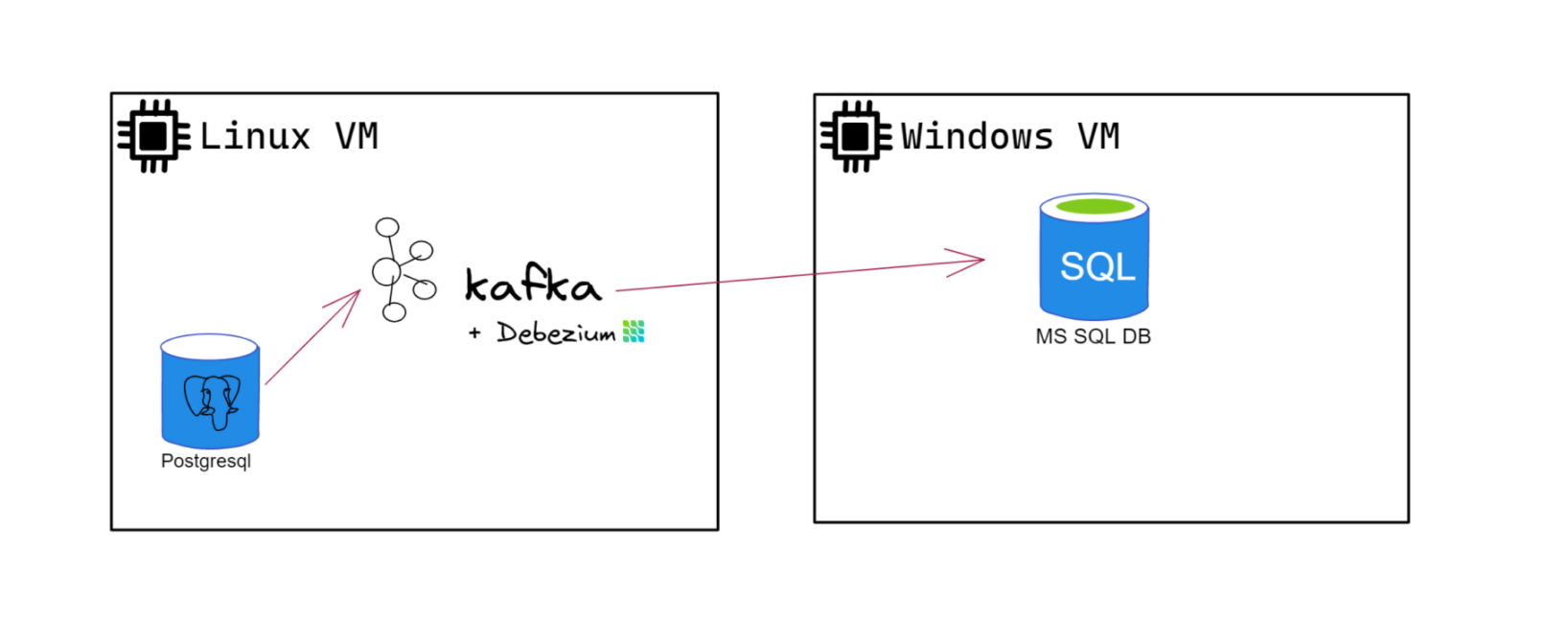
(图四:架构详情图)
请记住,为了实现所需的目标(使用Kafka将数据从Postgres复制到SQL Server),我们可以在任何主要的云提供商中使用Kafka-as-a-service产品。但是为了充分了解架构的运行方式,并简单地作为展示,我们决定不使用任何与SaaS相关的产品,也不在本系列中使用Docker。
安装步骤
让我们从安装第一个 VM 开始。我正在使用Windows PC进行所有测试,因此我正在Hyper-V中创建VM。您可以随意使用您喜欢的任何虚拟机管理程序。我的操作系统选择是红帽开发人员版 8.5。您需要订阅红帽门户:https://developers.redhat.com/products/rhel/overview。
1、在现有情况下,我将创建一个名为Jupiter的VM,作为我们Postgres和Kafka服务器。

2、就Hyper-V而言,这将是第2代。确保分配足够的内存,以便正确测试。我将我的内存设置为大约6 GB - 动态内存,这意味着Hyper-V不会将该内存完全专用于VM。
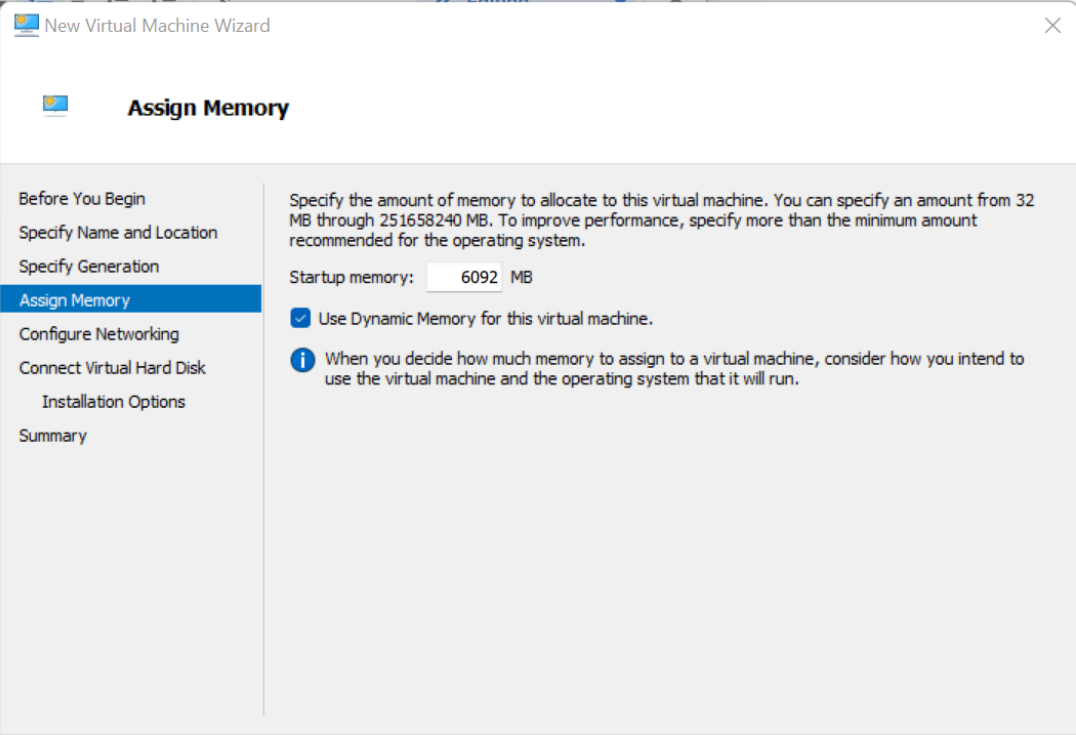
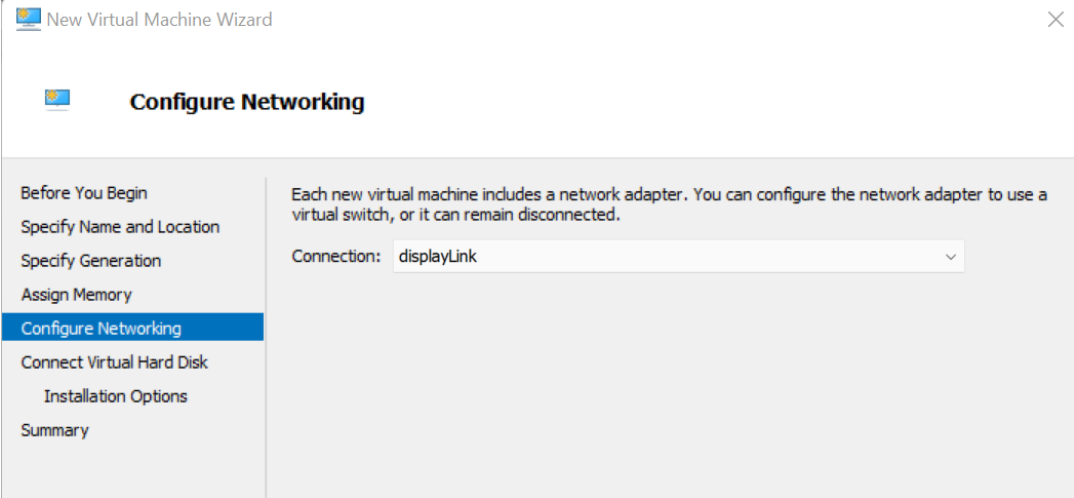
3、对于网络,我正在添加一个连接到主机物理网卡的虚拟以太网适配器,这意味着您的wifi路由器将直接向VM分配一个IP地址。
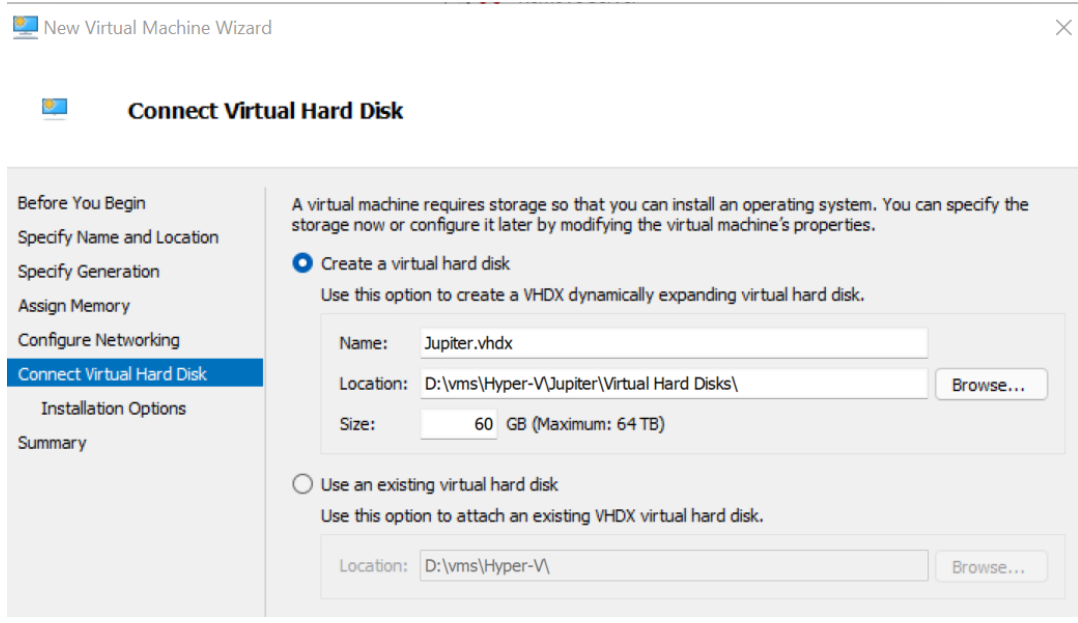
4、对于较小的数据示例,60 GB 的磁盘空间绰绰有余。
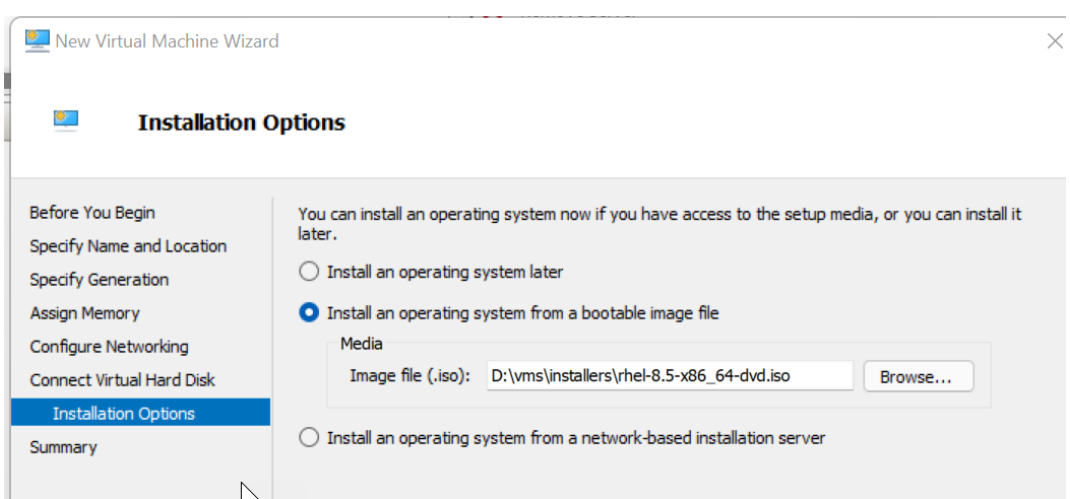
5、附加红帽 iso,以便您可以很快安装操作系统。
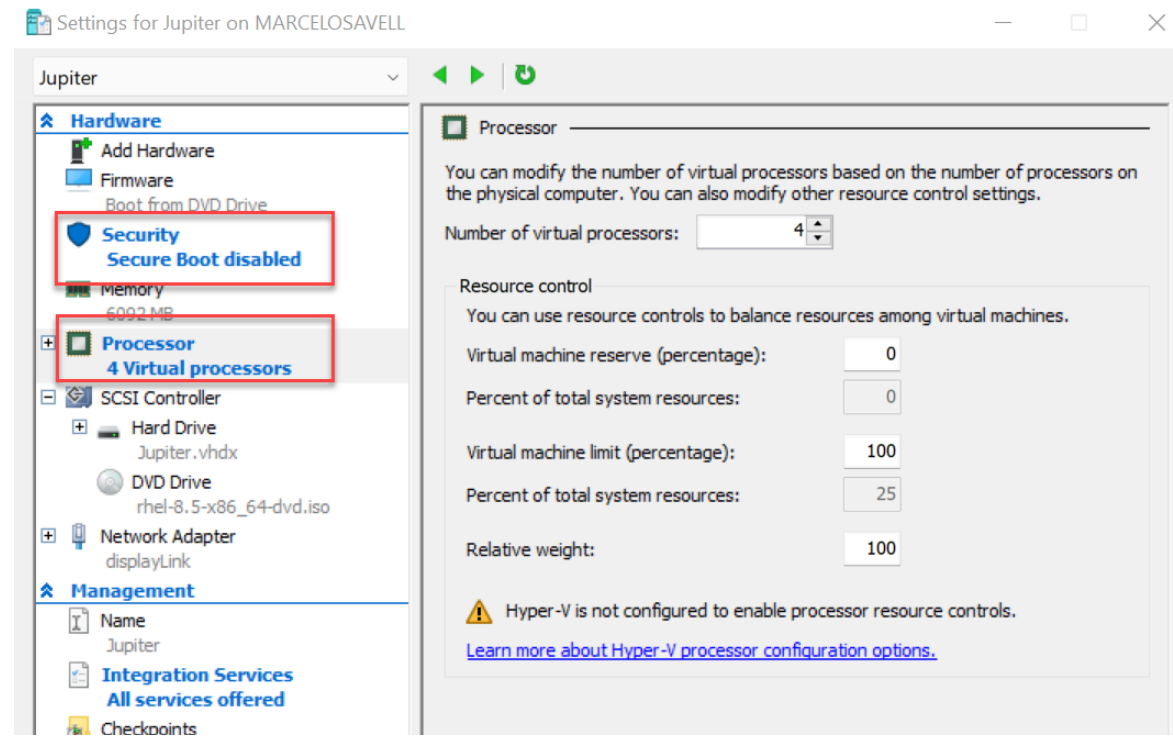
6、确保设置了合理数量的虚拟 CPU,并暂时禁用安全启动。
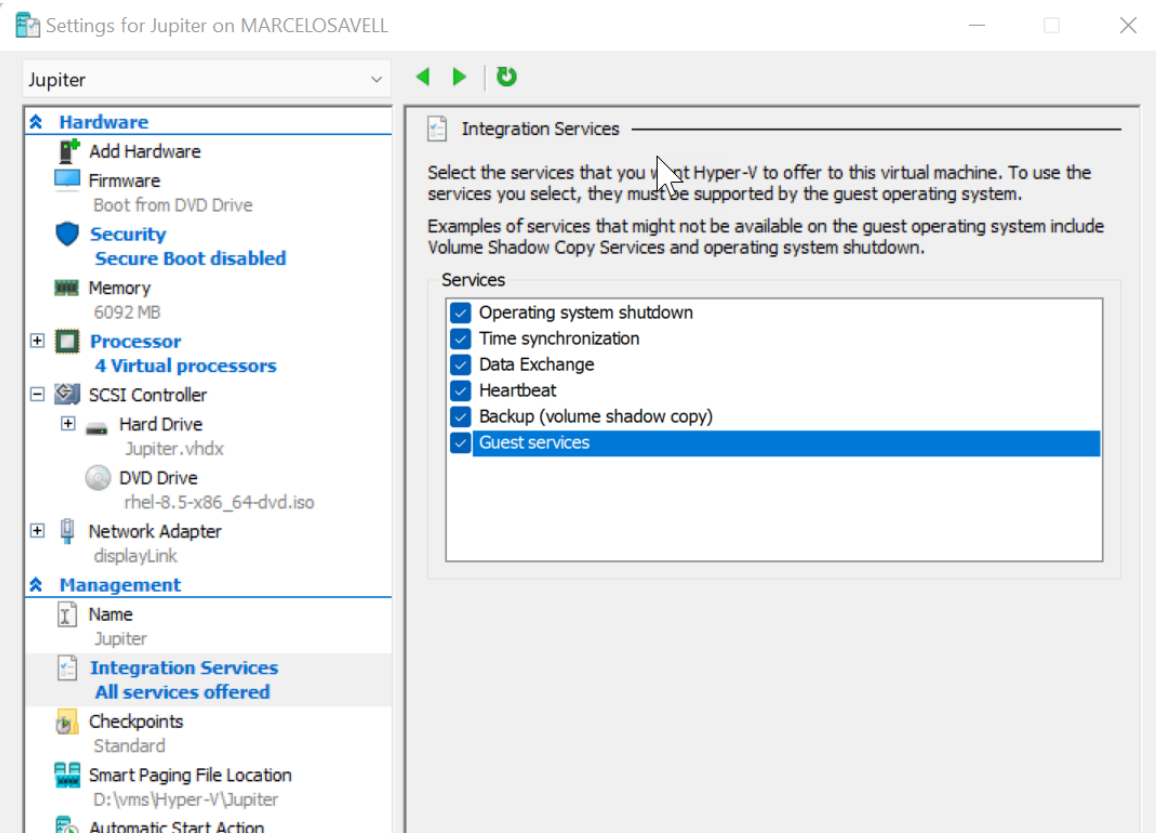
7、启用所有访客的服务。
8、让我们安装操作系统,启动 VM,选择其控制台窗口并按任意键,以便启动安装过程。

9、选择您的首选安装语言。
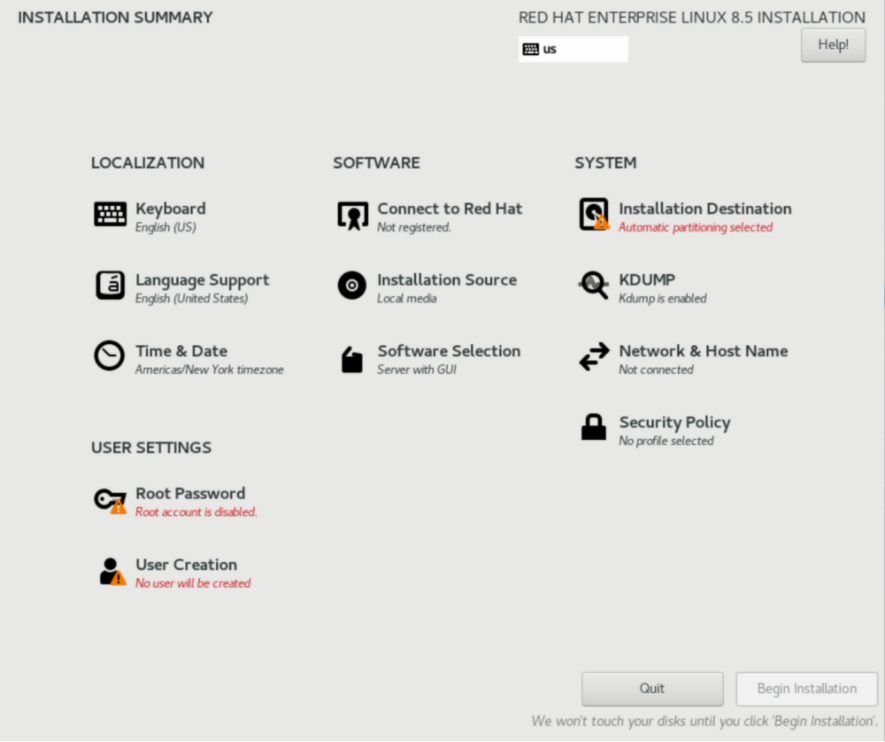
10、以下是我们要在此屏幕中调整的内容:将分区设置为自动,禁用Kdump,启用网络,设置Root密码,创建用户(在我的情况下:bigdatadude)。设置所有所需设置后,可以单击“开始安装”。
11、完成操作系统安装可能需要一段时间。之后,我们可以重新启动。
12、在配置阶段,您需要接受许可条款(您可能不会阅读)。
13、完成后,点击 “完成配置”。
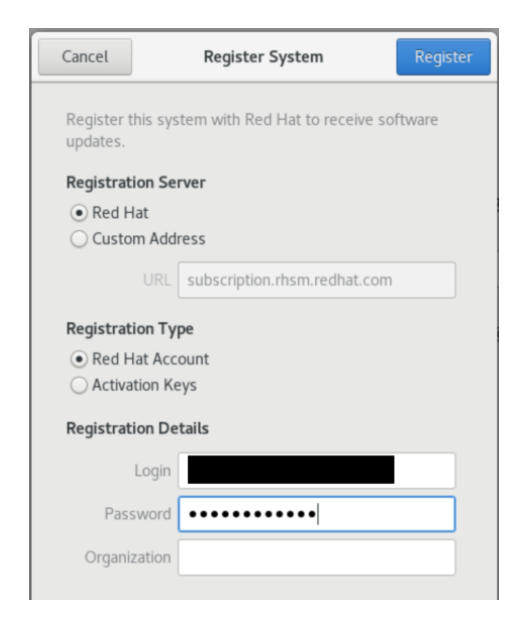
14、您一定要使用红帽帐户注册新 VM,否则您将无法下载必要的软件包以使环境正常工作。只需单击“注册”,然后为您的红帽帐户添加您的用户名(不是电子邮件)和密码即可。
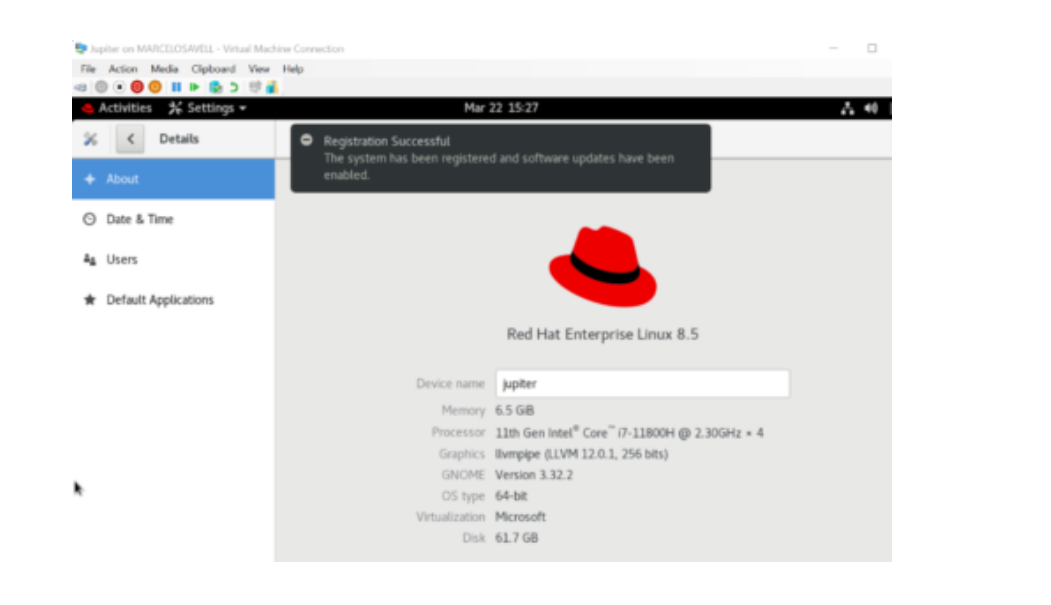
15、此时,我们可以忽略下一个屏幕,而无需登录到任何其他在线帐户。
16、现在我们不再需要使用 GUI。我们可以开始在Windows中使用任何类似终端的应用程序与我们的VM进行交互。我的选择是MobaXTerm(https://mobaxterm.mobatek.net/download.html)。
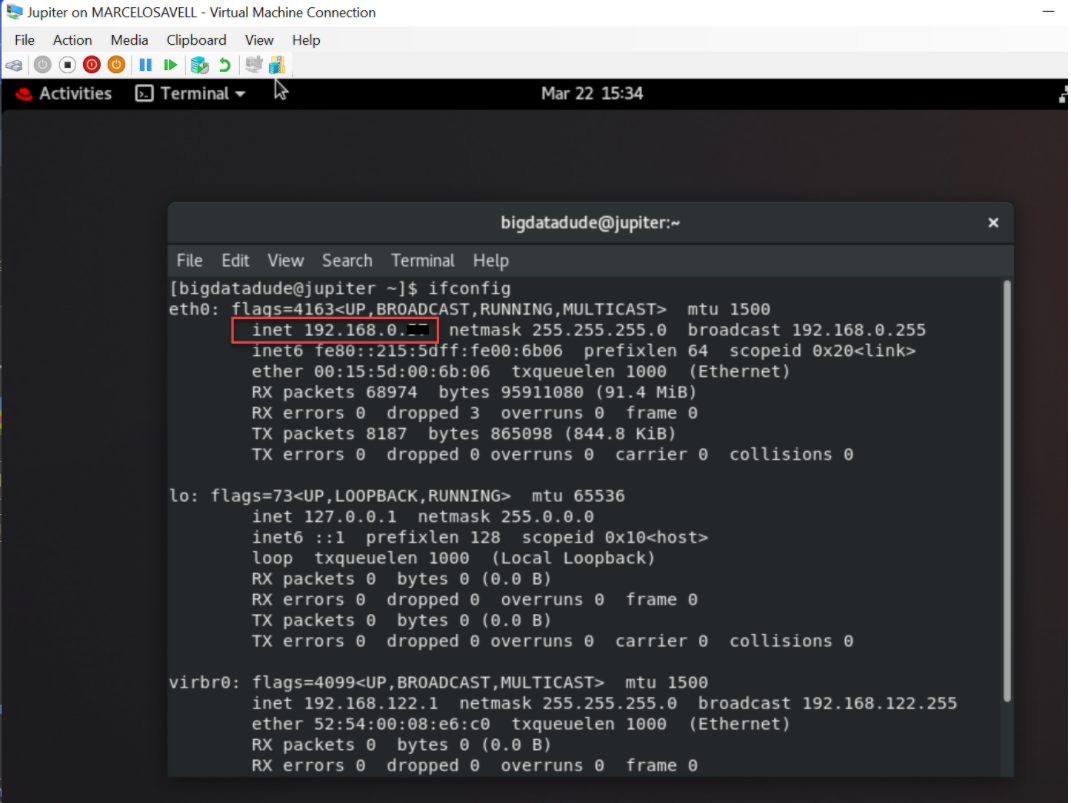
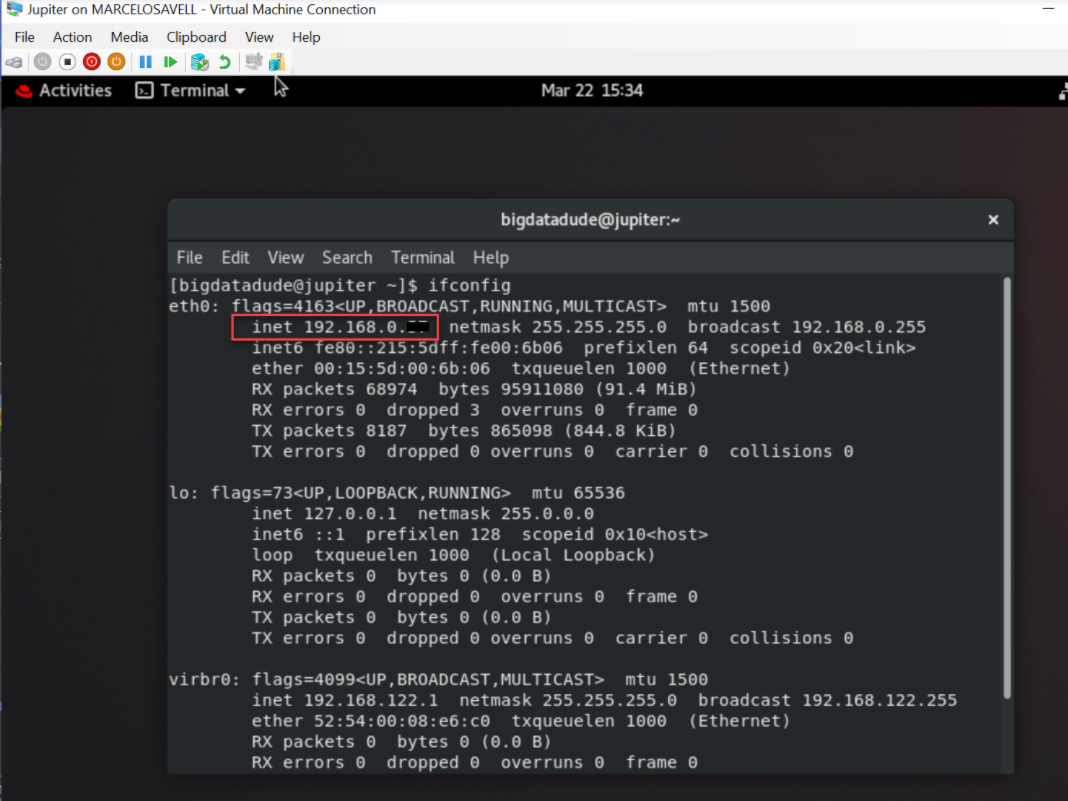
不过,需要获取刚安装的 VM 的 IP 地址。您可以通过打开终端窗口并键入:“ifconfig”来执行此操作。
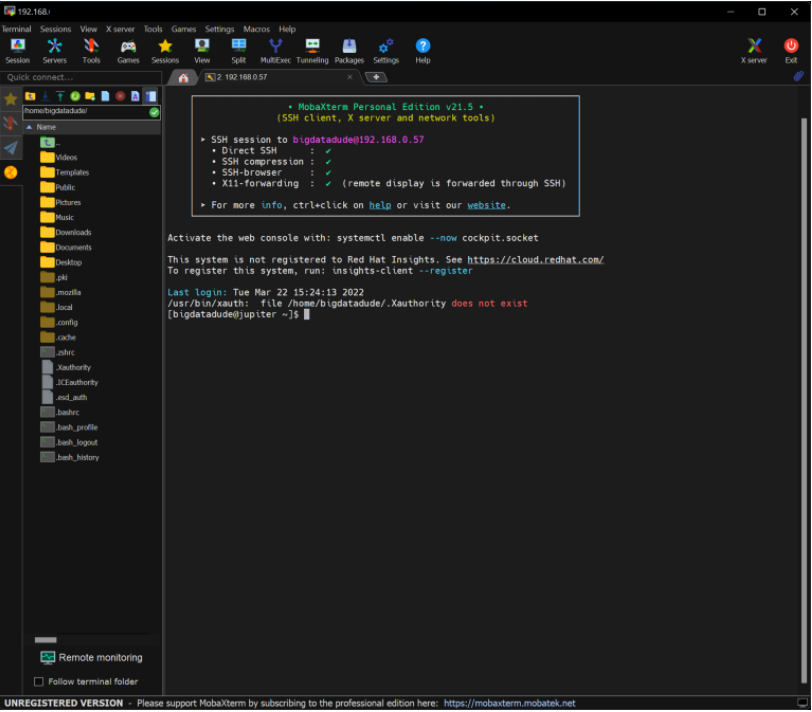
17、MobaXTerm非常有用,并且具有非常直观的UI,一旦连接,您将看到一个类似Windows资源管理器的侧窗口(如果您愿意,可以在此处传输文件)和主bash终端,您可以在其中输入所需的命令。
评论

 0 点赞
0 点赞

