




-- 表
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
-- 执行 UPDATE
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;
--# 注意:更新的 data 列上没有创建索引
1、HOT 概念
在进行含有索引的表上进行更新时,即使在没有索引的列上更新元组,索引也会进行更新,这就会导致创建了额外的索引,新创建的额外索引是没有意义的,也会导致空间的占用。并且B树索引在创建额外的索引后会造成索引页面的分裂,即使进行索引的清理页面也不会合并,这就导致索引的膨胀,影响数据库性能。所以我们通过引入 HOT,当更新的列上不存在索引时,发生Heap Only Tuple
注意:HOT 更新的前提条件是-更新的列上不存在索引。
下面这张图即不存在 HOT 更新:(需要创建额外的索引)
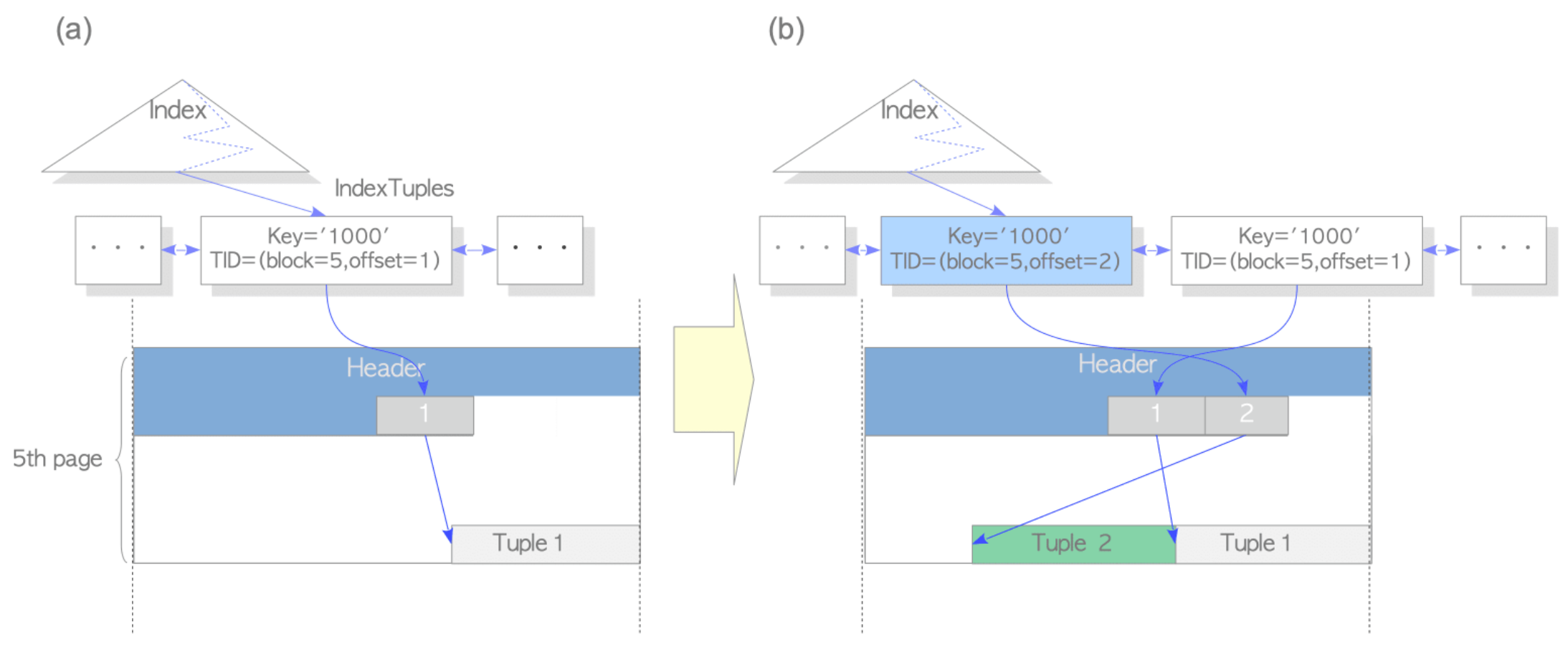
2、HOT
1)HOT 如何工作
当 HOT 特新更新行时,如果被更新的元组存储在老元组所在的页面中,PG就不会再插入相应的索引元组,旧元组(更新之前的元组)被标记为Heap Hot Updated,新元组被标记为Hot Only Tuple,两个标记位保存在元组的t_infomask2字段中
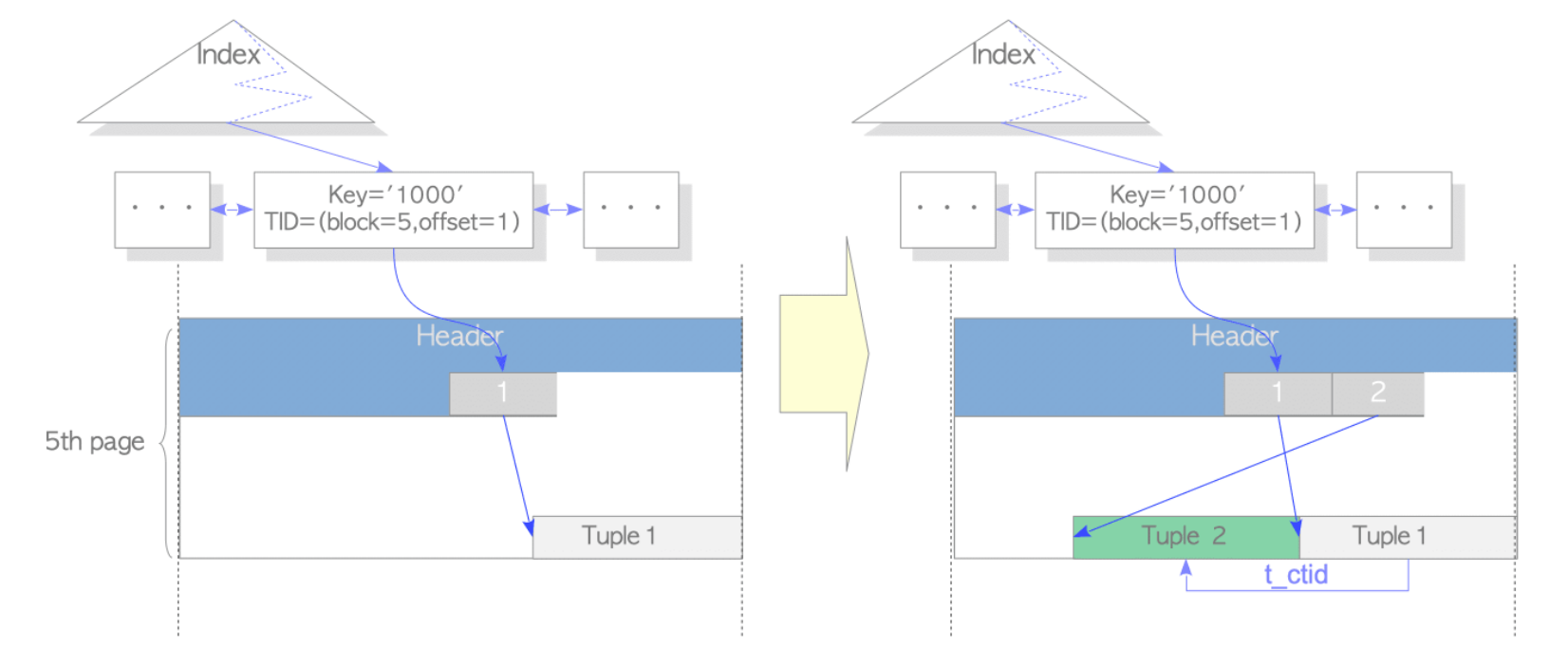



元组的查找:
(1)找到指向目标数据的索引元组
(2)通过索引上找到行指针1
(3)行指针1找到 tuple1
(4)tuple1 有 HHP,证明 HOT 链没有结束,通过 ctid 找到 tuple2
(5)tuple2 被标记为HOT,并且ctid没有指向新的元组,表明 HOT 链结束,最后的查找的结果是 tuple2
2)剪枝 - Pruning
行指针的重定向:老元组的行指针重新指向新元组的行指针
剪枝可能发生在任何时刻
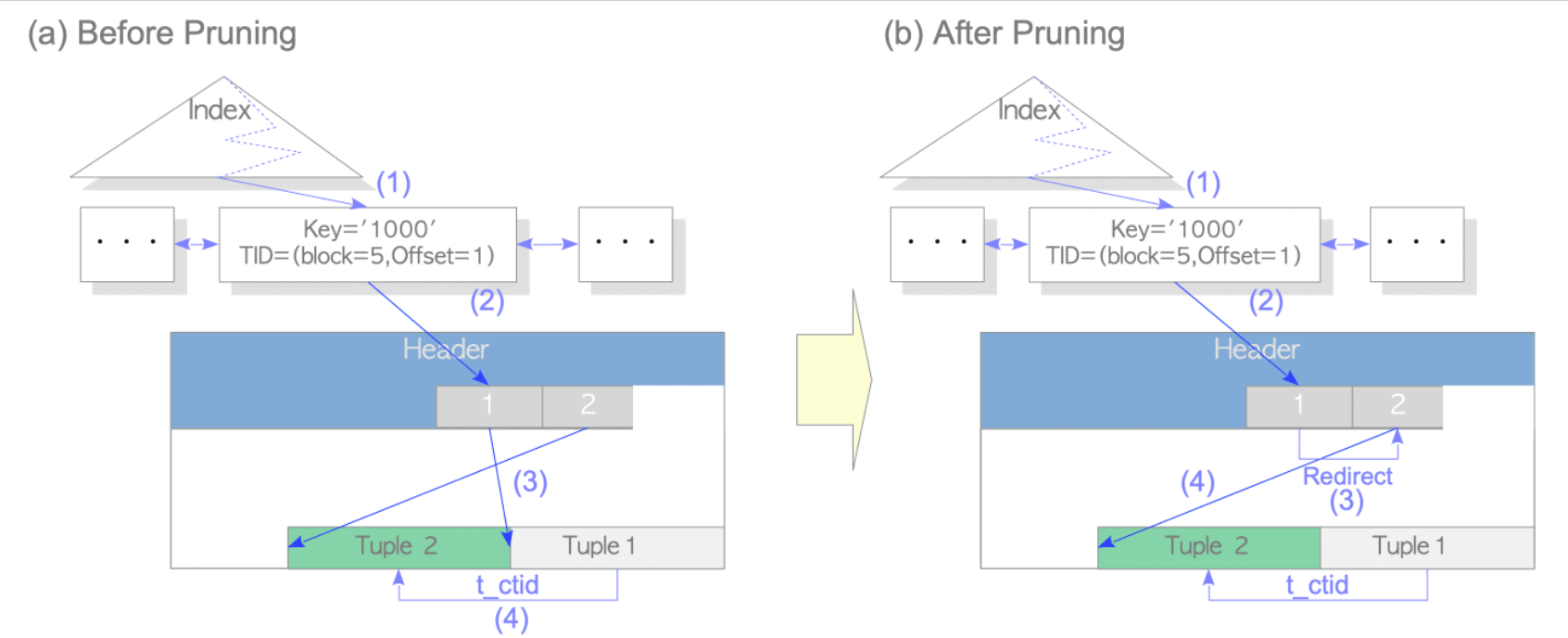

元组的查找:
(1)找到索引元组
(2)通过索引上找到行指针1
(3)行指针1 redirect到行指针2
(4)根据行指针2找到 tuple2
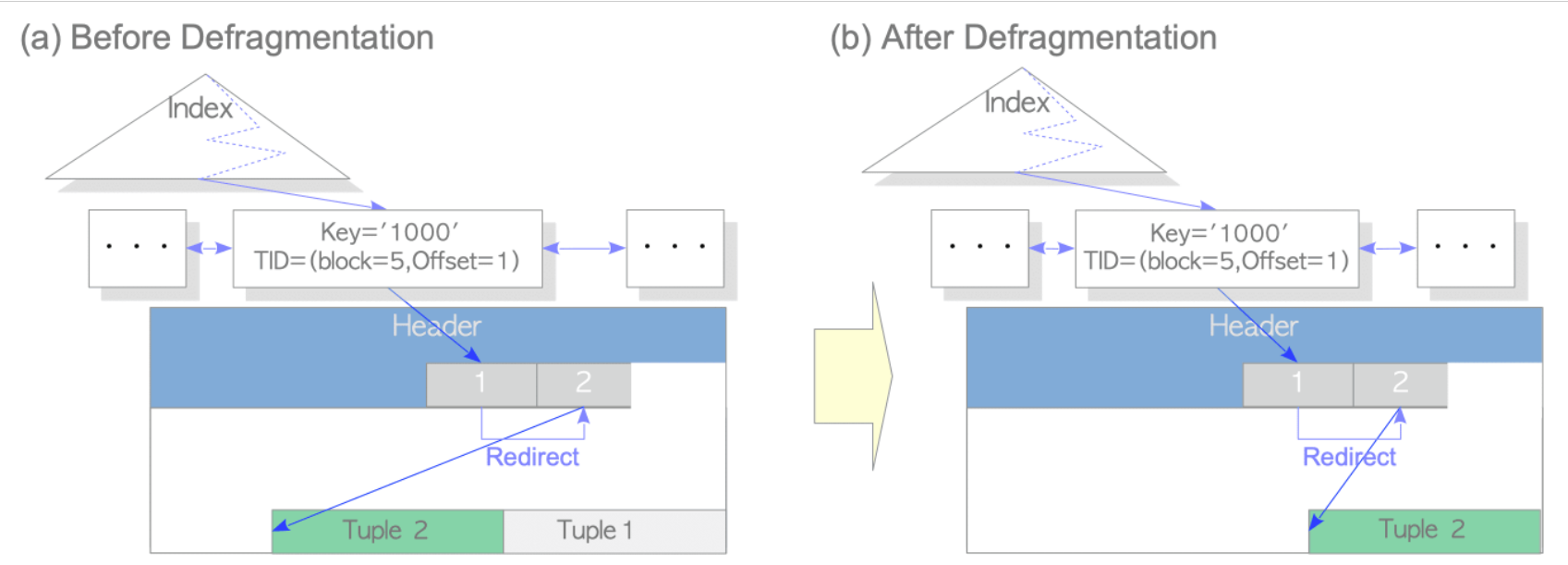
3)碎片整理 - Defragmentation
在合适的时间清理死元组
注意:碎片整理的工作不涉及索引元组的移除,所以碎片整理比起常规清理开销要小的多

3、HOT 优点
- PostgreSQL不必修改索引。由于元组的外部地址保持不变,因此仍可以使用原始索引条目。索引扫描遵循HOT链以找到适当的元组。
- 无需删除死元组即可执行VACUUM。如果一行上有多个HOT更新,则HOT链会很长。现在,任何后端进程处理的块,当检测到带有无效元组的HOT链,都将尝试锁定并重新组织该块,从而删除中间元组。这是可能的,因为没有外部引用这些元组,这大大减少了UPDATE繁重工作负载时对VACUUM的需求。
查看是否进行 HOT 更新以及更新的行数:
maleah_db=# SELECT n_tup_upd, n_tup_hot_upd FROM pg_stat_user_tables where relname = 'hot' ; n_tup_upd | n_tup_hot_upd -----------+--------------- 15 | 10 (1 row)将显示自上次调用函数pg_stat_reset()以来的累计计数。
检查n_tup_hot_upd(HOT更新计数)的增长速度是否与n_tup_upd(更新计数)一样快,以查看是否获得了所需的HOT更新
4、HOT 更新不适用的条件
1)被更新的元组和之前的元组不在同一个页面内。此时指向该元组的索引元组也会被条件到索引页中,如图 7.6(a) 所示
2)更新的列上存在索引。当索引的键更新时,会在索引页插入一条新的索引元组,如图 7.6(b) 所示
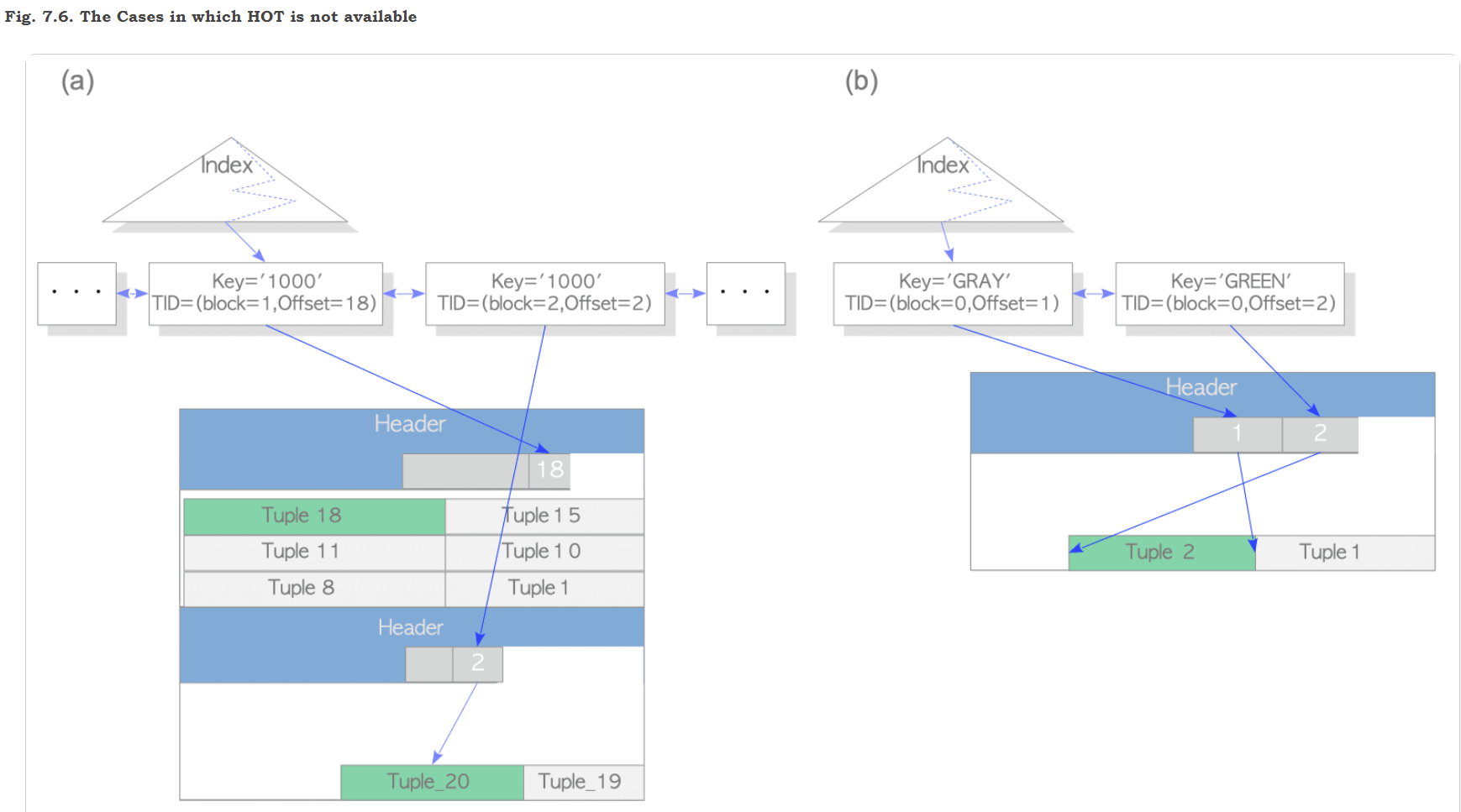

结论:可以适当调小fillfactor的值,预留一定的空间存放更新后的元组
参考
https://www.modb.pro/db/33457
《The Internals of PostgreSQL》
