今天(5月19号)客户反馈数据库很慢,我在观察io负载的过程中,突然发现2节点的library cache lock明显增加,另外有大量的异常等待事件
昨天客户反馈慢的时候我也观察到这两个等待事件偶尔会出现,但是客户反馈的是IO负载高的问题,且它们都不是top event所以我没有上心,当时对比了正常和异常时间点的awr信息,发现每秒物理IO增长了149%,IO延迟没有异常增加,所以把精力都放在了查找以及优化磁盘IO高的SQL上了.
查看library cache lock 的等待对象:


等待对象是last_successful_logon_time,是12c新增namespace。根据这个关键词+library cache lock没有在mos找到相关信息.
没有相关案例,我只能靠自己想象,脑子里出现了一个场景:在library cache 有一这么一个区域,它存放了用户的last_successful_logon_time信息,这些信息被组织成hash chains,hash chain 的入口是一个hash bucket数组。用户登陆数据库时,先检查这个区域,找到目标bucket,并且对相关的handle申请了lock,对该lco的信息进行修改。
我考虑了一下,想到了2个可能的解决方法:
1.有没有隐含参数可以增加handle数,把争用分散开来?
2.既然是12c新增的,并且只是个提示信息,说明这个特性不是必要的,那么能否通过修改参数禁用?
后来我问了一下mos和度娘,没有找到有用的信息。只能作罢
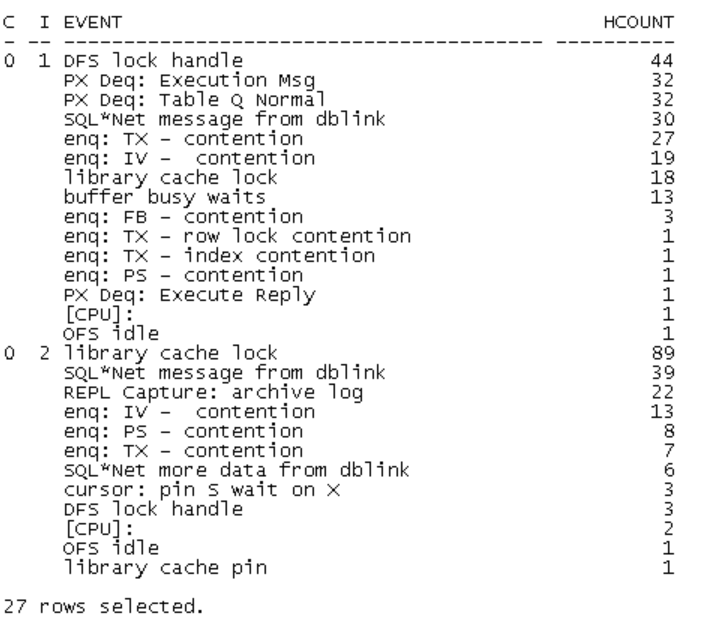
当务之急是解决故障,没有什么头绪的我查看了等待library cache lock的会话:

基本都是没有SQL_ID的,问了一下,果然现在用户都连不进来了。因为需要先生成登陆信息才能放行,在library cache lock解决之前,这些用户是进不来的。
经过观察我发现,每个节点的library cache lock 的final blocking_session 的是一样的,一节点的是2911,2节点的都是3631,而且过了一会儿发现这个blocking_session是不变的,也就是说很可能已经Hang住了

LCK的等待事件都是enq:IV-contention

enq说明它是个队列锁,但是我查询了v$enqueue_statistics以及v$lock 都没有这个类型的队列锁的信息。
我用官方文档给的方法
select chr(bitand(p1,-16777216)/16777215)||
chr(bitand(p1, 16711680)/65535) "Lock",
bitand(p1, 65535) "Mode"
from v$session_wait
where event = 'enq: IV - contention';
查询出来,lock=IV,mode=5。的确是个队列锁,但是我没有在相关视图找到等待事件的描述信息。
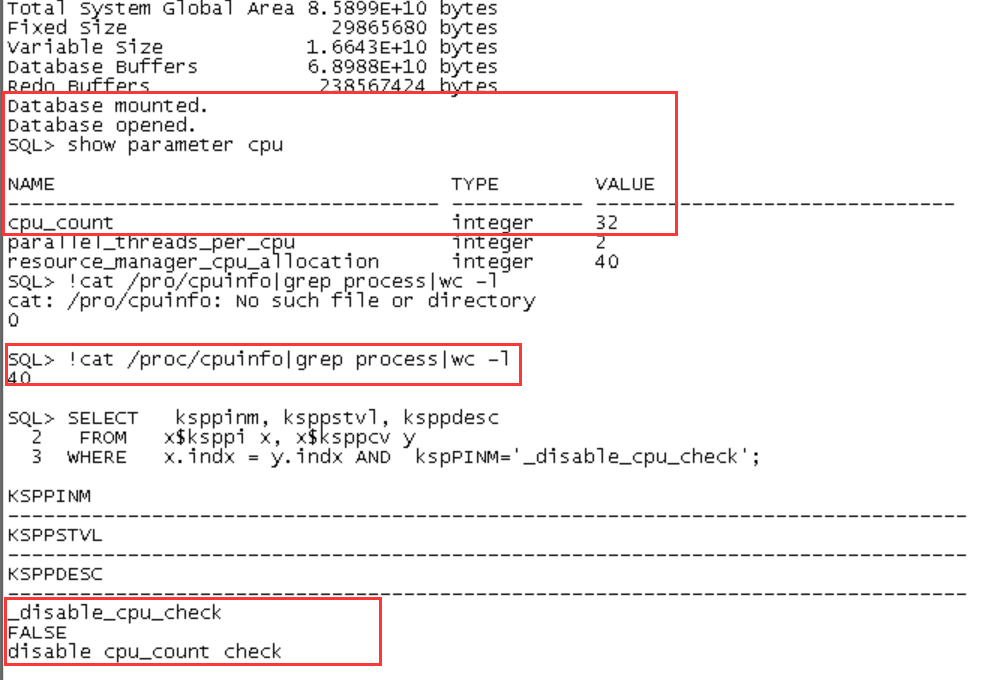
后来我查了一下这个等待事件,找到了其中一个案例,是cpu_count的个数不一致导致的bug。我查看了一下两个节点的cpu_count:
1节点cpu_count=40
2节点cpu_count=32
实际上的主机cpu个数也是这样的情况。于是我手动修改了cpu_count个数,可以动态修改,但是因为很多参数已经在启动的时候根据cpu_count确定下来了,所以其实于事无补,而且lck 这么核心的进程hang住,问题也很大。本次故障中,cpu_count影响最大的是lmd进程,导致全局资源调度出现了问题,个人推测这是多种enq类等待事件出现的原因。然后enq资源(主要是IV队列锁资源)调度故障又导致了LCK进程hang住,进一步出现library cache lock等待异常(不过我比较奇怪,为啥没有其它namespace的library cache lock等待呢)。
我咨询了大神同事,他告诉我,last_successful_logon_time可以禁用,但是必须先打补丁。听到他这么说,我去掉了下划线去Mos重新查了一下,还真有相关的文章。

但是跟我这个情况是不一样的
而且问题的源头不是这个特性,而是LCK 因为IV等待hang住了。
由于这个lck 比较核心我不敢随便kill,所以我询问客户能否重启实例?征得同意后,我把1节点的cpu_count修改成32并重启1节点之后,数据库恢复正常,持续观察了一个小时,没有出现IV等待了。

PS:12C修改CPU_COUNT不需要修改 _disable_cpu_check=TRUE