




openGauss 目前版本3.0.0了
1.培训的资料
训练营第三期PPT合辑:
https://www.modb.pro/topic/403519
2.官网
3.官方文档(html版)
https://opengauss.org/zh/docs/3.0.0/docs/BriefTutorial/BriefTutorial.html
官方文档(pdf/chm版)
https://opengauss.obs.cn-south-1.myhuaweicloud.com/3.0.0/openGauss-document-zh-3.0.0.zip
4.docker build脚本
https://github.com/enmotech/enmotech-docker-opengauss
docker镜像
https://hub.docker.com/r/enmotech/opengauss
5.帮助文档gitee库,可考虑放到自己网站上,增加ElasticSearch全文检索功能,搜索起来更方便吧
https://gitee.com/opengauss/docs
6.源代码库等
7.openGauss 开发规范及运维一些相关的内容:
状态监控
https://www.modb.pro/db/21018
SQL执行计划
https://docs.mogdb.io/zh/mogdb/v3.0/1-query-execution-process
WDR报告解读
https://docs.mogdb.io/zh/mogdb/v3.0/wdr-snapshot-schema
https://docs.mogdb.io/zh/mogdb/v3.0/wdr-report
故障排查流程:
https://www.modb.pro/db/99353
常用查询SQL:
https://www.modb.pro/db/165105
闪回特性实践
https://www.modb.pro/db/378767
8.如何连接openGauss
工具安装及展示
https://www.modb.pro/db/42604
https://docs.mogdb.io/zh/mogdb/v2.1/datastudio
9.openGauss扩缩容、升级及监控管理
opengauss_exporter 是由云和恩墨开发,为MogDB/openGauss数据库量身打造的数
据采集工具,配合监控报警框架prometheus + grafana实时展示数据库信息,为
MogDB/openGauss数据库的平稳运行保驾护航。
源码地址: https://gitee.com/enmotech/opengauss_exporter
10.新特性1 AI特性
https://opengauss.org/zh/docs/3.0.0/docs/Developerguide/AI%E7%89%B9%E6%80%A7.html
AI特性子模块名为DBMind,相对数据库其他功能更为独立,大致可分为AI4DB、DB4AI以及AI in DB三个部分。
- AI4DB就是指用人工智能技术优化数据库的性能,从而获得更好地执行表现;也可以通过人工智能的手段实现自治、免运维等。主要包括自调优、自诊断、自安全、自运维、自愈等子领域;
- DB4AI就是指打通数据库到人工智能应用的端到端流程,通过数据库来驱动AI任务,统一人工智能技术栈,达到开箱即用、高性能、节约成本等目的。例如通过SQL-like语句实现推荐系统、图像检索、时序预测等功能,充分发挥数据库的高并行、列存储等优势,既可以避免数据和碎片化存储的代价,又可以避免因信息泄漏造成的安全风险;
- AI in DB 就是对数据库内核进行修改,实现原有数据库架构模式下无法实现的功能,如利用AI算法改进数据库的优化器,实现更精确的代价估计等。
11.安全特性
全密态等值查询
当数据拥有者在客户端完成数据加密并发送给服务端
12.防篡改
账本数据库机制
举例如下
创建带blockchain的schema
omm=# create schema test1 with blockchain;
CREATE SCHEMA
创建行表,自动会变成防篡改用户表
omm=# create table test1.table1( a int primary key);
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "table1_pkey" for table "table1"
CREATE TABLE
检查表结构可以看到多了一列hash
omm=# \dS+ test1.table1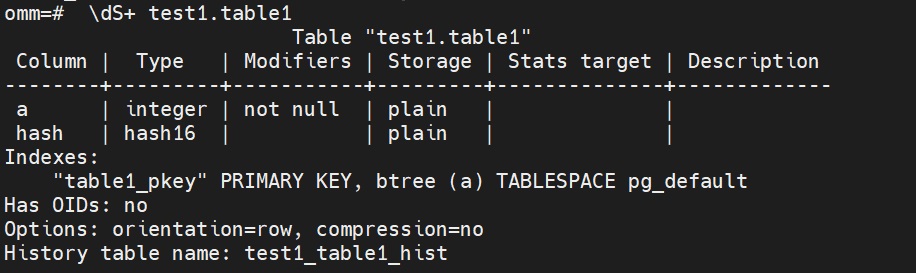
85个Q&A
openGauss后续演进中提供DSS共享存储及DMS共享内存(备机实时一致性)能力。
openGauss兼容MySQL,包括在gs_initdb时候指定dbcompatibility参数来进行兼容,同时社区提供兼容插件供大家在迁移MySQL时候使用。
openGauss有计划缓存,提供global plan cache能力。
openGauss提供数据加解密函数gs_encrypt_aes128,同时在多个特性提供数据加解密功能,例如数据导入导出、数据库备份恢复。
优化器针对某个SQL语句获得其最优的执行路径,枚举不同的候选的执行路径,这些执行路径互相等价,但是执行效率不同,分布计算它们的执行代价,最终可以获得一个最优的执行路径。
当前PostgreSQL对于每个客户端连接,通过fork单独进程来执行,和openGauss的架构不相同。openGauss实现线程化改造,通过线程模型来提升并行性能。
openGauss社区开发者提供基于grafana + prometheus + opengauss_exporter方式进行数据库节点监控,同时AI框架DBMind也提供类似能力,欢迎大家使用。
openGauss提供Append only和inplace update两种存储引擎模式,在处理update语句上有些许区别,可以参考源码和相关技术文章来了解。
openGauss在多核架构的处理上做了很多优化,包括Numa相关设计及优化、并行执行、线程池架构等。
在大并发场景下,openGauss提供线程池能力,控制并发数量,保障系统稳定;以及提供增量checkpointer等机制,保障性能波动不超过5%。
避免线程在运行中在不同核上漂移,从而引起访问NUMA远端内存。openGuass通过配置参数thread_pool_attr控制CPU绑核分配,该参数仅在enable_thread_pool打开后生效。
TPC-C是用计算机设备在每分钟内所能处理的标准事务的数量来衡量其处理能力的多少;TPC-C的通用估算公式如下: TPC-C = ∑(每分钟业务事务量 * 标准事务量比率)/ (1 — 冗余率)。具体可以参考相关资料来学校。
关闭NUMA绑核后,性能会有一定衰减,大概20%左右。
以WALInsertLock优化来讲,将全局WALInsertLock数组按照NUMA Node的数目分为多份,分别在对应NUMA Node上申请内存。每个事务线程根据自己所归属的NUMA Node,选择WALInsertLocks子数组。WALInsertLock引用了共享内存中的LWLock,为了最大化减少跨Node竞争,将LWLock直接嵌入到WALInsertLock内部,这样就可以一起进行NUMA分布,同时还减少了一次Cache Line访问。
openGauss后续演进中提供DSS共享存储及DMS共享内存(备机实时一致性)能力。
openGauss主备机制提供物理复制能力,在主备节点间进行日志同步,实现节点故障或者重启情况下,数据无丢失;同时提供逻辑解码能力,将物理日志反解析为逻辑日志。通过DRS等逻辑复制工具将逻辑日志转化为SQL语句,到对端数据库回放,达到异构数据库同步数据的功能。
openGauss内核和华为GaussDB Kernel共基线开发,所以代码演进上是一致的。openGauss社区版本是由DBV伙伴来提供数据库产品和服务,华为GaussDB Kernel通过华为云GaussDB (for openGauss)对外提供服务,企业可以根据自己需求选择华为云或者openGauss DBV。
支持基本的语法检验和组件关系,如果解析失败,将会影响安装流程。
数据不加密就不会影响性能,全密态在对加密字段做查询的时候对性能有影响。如果已经将某字段进行了加密,也可以通过脚本变成非加密字段,但有一定的复杂度。
如果需要CM组件的话,需要扩容到一主两备。
可以自己手动挨个initDB,然后通过配置搭建主备关系,但是相对比较复杂,易用性不好。
大部分语法是兼容的,不排除部分业务需要改造适配。
RTO和硬件环境强相关,当前在商用环境上,openGuass 主备切换时间可以在10s内完成。
server agent 架构主要是工作职责上的区分,server 重点关注数据汇总处理,而agent更加倾向于本地化,主要负责本节点的管理对象操作。
没有强制要求,因为CMServer是基于Paxos协议选主,建议部署≥3的奇数个节点。
om_moniter,主要负责监控cm_agent进程,我们在集群安装的时候,会把moniter的拉起命令写入系统crontab中,由操作系统定期拉起。
备机恢复后会自动加入集群。备机会自动被CMA拉起,会被CMS仲裁出角色(备),并连接指定主机。部分可build解决的故障,CM会自动下发build修复。
当前社区开放的主要有选主仲裁(无主,双主,僵死,网络故障,磁盘故障等场景),磁盘满只读保护仲裁,AZ级网络故障仲裁等。
是的,集群所有命令都可以跨节点执行。
答:没有少,不同节点可以部署不一样的实例,例子中CMS部署在节点1,3,4,5,6的,而数据库是在节点1,2,3,4,5,展示上都是五个,实际用了6个节点。
当前慢SQL受log_min_duration_statement参数控制,具体的慢SQL信息存储于postgres库下的statement_history表
dbe_perf是自带的一个schema,内部包含很多系统内置的性能视图,可以查询pg_views获取具体视图列表
有很多种可能性,比如:可能是IO满导致的IO争抢;也可能是IO相关的读写策略配置问题;也有可能是SQL计划不优导致走全表扫描等,需要具体情况具体分析。
当前WDR snapshot过程中会把wait events信息写入相关表;同时调用capture_view_to_json函数,传入wait events视图,也可以将相关信息以json形式存储到pg_perf目录下(同pg_log同级目录)。
这个要具体问题具体分析,首先要明确这块是不是数据库内核导致的CPU/MEM/IO高,如果是,则再继续分析。对于CPU高,一般较大概率是SQL导致的,可以试着分析一下WDR、归一化SQL内的CPU Time信息;对于MEM高,可以运行时的时候查看SESSION相关的内存视图,或者在线会话数量变化信息;对于IO高的话,可以使用pidstat/iotop等,以及结合内核内慢SQL、WDR、归一化SQL看一下行活动或者cache/io相关指标。
受wdr_snapshot_retention_days参数控制。
主从节点上都可以生成WDR报告,运行相关函数即可。
(1)数据库自治中的信息收集的执行频率是可调的,对于数据库的影响可以控制。
(2)数据库查询优化现在已经能够做到微秒级别,通过场景的判断,我们可以决定是使用Gplan还是Cplan(GPlan采用了计划缓存机制不总走优化器)。也可以决定是否要走AI多列模型。
社区版本已经包含一些算子,语法默认支持,可以直接使用。
AI优化器需要统计信息,需要数据样本或者负载样本支持训练。
使用系统表存储二进制串格式。
命令行调用优化组件会直接回显结果,也可以部署相应的服务将结果存入系统表或者前端界面。
数据库内置AI算法都是比较轻量级的算法,执行时间和成本是很小的,但是虽然代价很小,占用计算资源是不可避免的。
包含建议的解决方案。目前具备的自调优包括参数调优和索引推荐调优,之后还会加入一些基于OM工具的系统恢复。
使用AI算法的基数估计在列相关性强的场景下准确性要优于传统方法1-2个数量级,大部分情况下可以让执行计划更优。但是查询优化是个NP难问题,保证最优也是比较难的。
DB4AI特性和自治运维特性和数据库功能相对比较隔离,默认开启。AI优化器和数据库内核功能关系比较密切,可以使用GUC参数配置开启。我们使用场景识别以及模型本身的性能设计确保对于数据库只有正向收益。在基数估计中,机器学习的训练过程代价和传统统计信息创建的代价相当,对于数据库性能不会有过多影响。
华为云,消费者云以及一些DBV客户都有应用。
采用了基于差分的基数判断异常,不仅仅依赖基准值(阈值)。识别的关键特征包括波动加剧,有毛刺,以及周期性破坏等,不需要预先加入基准值。
openGauss的脱敏策略,属于动态脱敏,适合于对外发布数据,或者对其他用户共享数据时使用,数据接收者只能获取到脱敏之后的数据,可以保护用户隐私不被泄露。
全密态策略,适合于高强度保护数据机密性,除了应用本身外的任何人或物都无法获取数据明文,能够极大提升机密数据安全性。
全密态加密字段,会造成存储膨胀,但是相比于整个数据库空间,膨胀系数不大。
正常的物理备份和恢复,并不会改变运维过程。但逻辑备份和恢复,会需要配置密钥,并且执行加解密过程, 且备份文件不再加密。
加密对一般数据库TPCC性能影响,在10%左右,不同加密的场景也不一样,性能损耗也有差别,一般可以选择只对重要数据加密。
正常的物理备份和恢复,并不会改变运维过程。但逻辑备份和恢复,会需要使用对应版本的libpq,配置密钥,并且执行加解密过程, 且备份文件不再加密。
应用连接HA的连接串是安装时OM预写入的。
在jvm虚拟机中是不允许同时加载两个相同的driver类,因为openGauss驱动兼容PG的driver类;不过openGauss-jdbc 3.0除了支持兼容PG的driver,也有独立的org.opengauss.Driver类,此时PG驱动和openGauss驱动可以共存。
不同的节点是可以设置不同的策略,不过HA一般不这样设置,除非有特殊的使用场景,此时可以用include方式包含hba文件,hba文件存放到PGDATA之外来保持差异性,因为主从切换可能会覆盖PGDATA里的配置。
只要数据库编码支持中文就可以,比如通用的UTF8、EUC_CN、GBK。
字符集的支持可以查看系统表pg_collation,支持简体中文的编码包括UTF8、EUC_CN、GBK。
Oracle迁移到openGuass相比迁移到PG有很多兼容性提升,训练营分享的<<opengauss与PostgreSQL部分特性对比>>也有一些介绍。
支持。
支持。
支持,如东方通,宝兰德,金蝶天燕等。
jdbc连接串只能配置连接主库角色,切换要借助CM和其他的一些工具(它们会判断如何切换到同步备库)。
不一样的,目前openGauss用OM搭建的集群不支持两主。
暂时不可以。需要人工去判断,也是根据实际需求摘除。自动摘除对安全性没有保障。
GAUSSHOME、PATH、LD_LIBRARY_PATH以及数据目录等。
在扩容命令时会进行检验,如果有问题会提示出来。
不需要停业务,云和恩墨研发的MTK工具可以平滑迁移。
可以的,注意如果执行删除命令的同时主机上存在事务操作,事务提交时会出现短暂卡顿,删除完成后事务处理可继续进行。
主备之间的root和omm用户都要有互信。
节点信息,数据目录位置等。
不可以的,就地升级和灰度升级都是一次性升级全部节点。
增加删除节点时候或硬件损坏需要移除节点时候。
也可以使用rm的方式清理,但是gs_uninstall工具可以减少自己查找对应目录的动作,避免漏掉要清理的环境。
出现这样的问题应该是因为wal2json.so文件没有拷贝到升级后的新的环境目录下。因为升级过程是不会做这一步的,数据库升级完拉起之后,想要进行逻辑解码,但是缺少了wal2json,就会有问题了。
升级过程也是会停数据库的,因为替换软件包后,要用新的软件把数据库拉起;灰度升级和就地升级区别在于是否可以在业务进行时候操作,一般生产选择灰度升级,对升级的割接窗口较大时候可以考虑选择就地升级。
缩容是一定要在主节点进行的,扩容的话,最好在主节点进行。
可以的。
会失效,例如升级过程的wal2json.so文件就不会拷贝,需要手动拷贝。主备节点最好不要这样做,在实际运维的时候会出现问题,且环境检查的时候可能就会出现相关报错。
大概时间在十秒之内
数据库云管平台在满足监控的基础上,能快速构建、快捷运维、智能分析、高效巡检能力,提升了效率。
默认为15天。启动时带上这个参数--storage.tsdb.retention=90d可以延长,也可以自定义。prometheus按照block块的方式来存储数据,每2小时为一个时间单位,首先会存储到内存中,当到达2小时后,会自动写入磁盘中。
可以创建索引,同时建议应该结合分区表。
是的,需要用这个命令将数据库角色更新到对应的二进制文件,否则再重启集群之后,主备关系可能出现问题。
慢SQL需要通过log_min_duration_statement参数去设置,同时在dbe_perf.statement 和 dbe_perf.statement_history 中去查看。



