




5 月 14 日,5 月 15 日,由华为李士福老师领衔主讲《8 小时玩转 openGauss 训练营》(第三期)在周末两天的下午顺利结营。

训练营报名
感谢云和恩墨、openGauss 社区、Gauss 松鼠会联合组织的《8 小时玩转 openGauss 训练营》(第三期)直播课程,去年 9 月份参加了举办的第二期活动,感觉很是不错,再加上本月墨天轮中国数据库排行榜上 openGauss 终于登上了榜首;北京疫情又严重起来了,哪里也不敢跑,居家办公中,故有大把的时间,于是乎也就报名了第三期的训练营。
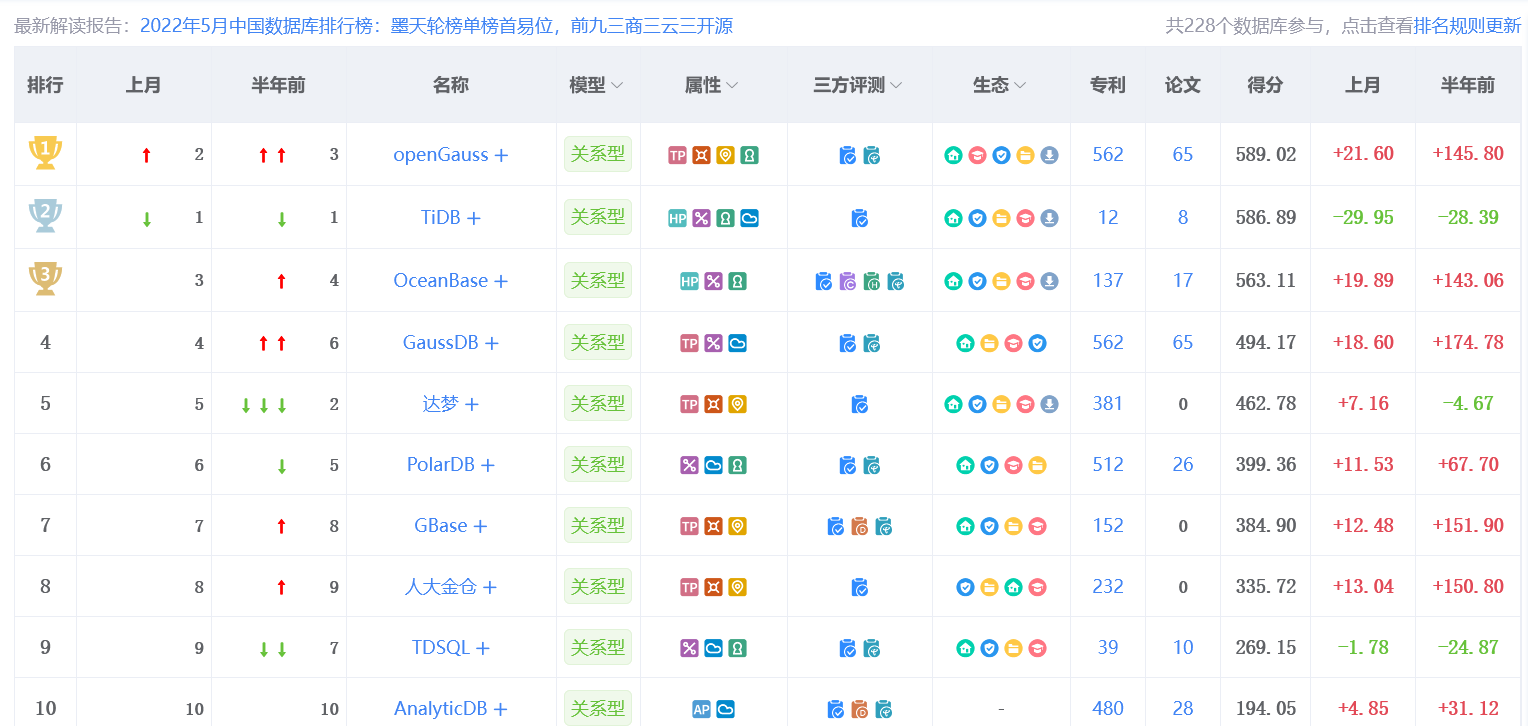
openGauss 作为面向数字基础设施的开源数据库,于 2020 年 6 月 30 日正式开源后获得业界积极响应,当前 10+ 家合作伙伴发布基于 openGauss 的商业发行版,前景势头正盛,邮储银行新核心系统、中华联合人寿团险核心交易系统、四川气象局气象观测数据系统等多家企业已经选择了 opengauss 作为生产系统,openGauss 已与超过 70 所重点高校达成开课意向;《openGauss 数据库核心技术》成为多所高校的专业辅助教材;openGauss 技术内容入选全国计算机等级考试二级、三级试题,于今年九月份正式实施。未来 2-3 年 openGauss 多维度的培养体系将会培养出上千上万的开发者和 DBA,助力数据库人才发展。 openGauss 正在成为国内主流的核心技术路线,市场占有率正在逐步扩大。
业余时间学习了解 openGauss 是十分有必要的,通过两天的训练营学习还是很有收获的。来自 11 位专家的内容涉及到 openGauss 开发规范及运维,连接,WDR 报告和性能调优,扩缩容升级监控,主备 HA 部署,安全,openGauss 与 PostgreSQL 部分特性对比,AI 特性,集群管理组件,社区发展等方方面面,还是比较丰富的。
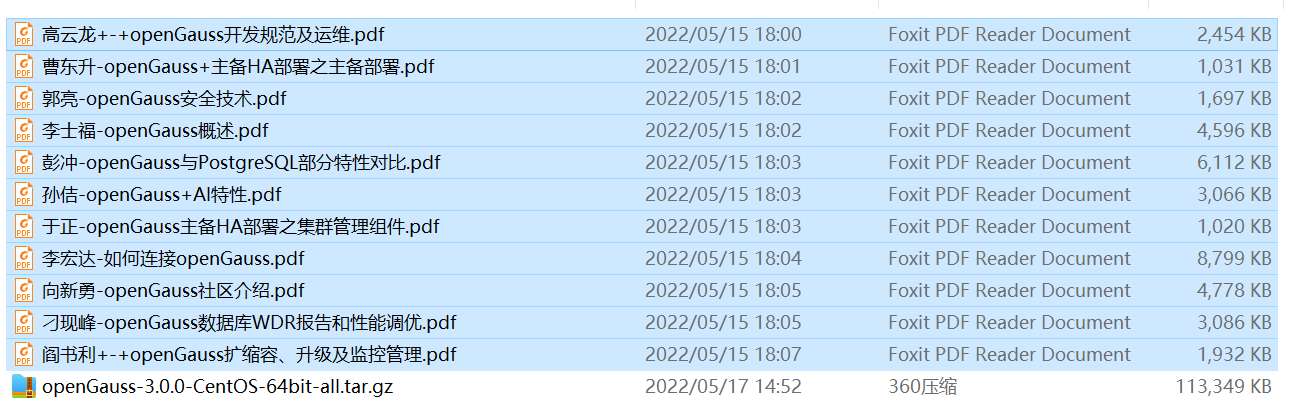
干货满满,其中一节的开发规范内容如下,很有借鉴意义。
命名规范:
数据库对象(database, schema, table, column, view, index, function, trigger等)
命名标准:
• 长度不超过63个字符
• 命名尽量采用富有意义英文词汇
• 建议使用小写字母、 数字、 下划线的组合
• 不以PG、 GS开头(避免与系统DB object混淆) , 不以数字开头
• 不使用双引号即"包围, 除非必须包含大写字母或空格等特殊字符
• 禁止使用保留字, 保留关键字参考官方文档或通过pg_get_keywords()函数查看
• table能包含的column数目,根据字段类型的不同, 数目在 250 到 1600 之间
• 分区表命令规则与普通表保持一致
• 临时或备份的数据库对象名, 如table,建议添加日期, 如dba.trade_record_2100_01_07
• 索引显示命名规则为: 表名_列名_idx, 与缺省默认给出的索引名保持一致
• 数据库的用户表空间用ts_<表空间名>来表现 ,数据表空间和索引表空间可以分开, 如ts_data_xxx 和 ts_idx_xxx
Tablespace 设计
• 频繁使用的表和索引单独存放在一个表空间, 此表空间应在性能好的磁盘上创建
• 以历史数据为主, 或活跃度较低的表和索引可以存放在磁盘性能较差的表空间
• 表和索引可以单独存放在不同的表空间
• 表空间可以按数据库分、 按schema分或按业务功能来分
• 也可以用默认表空间pg_default, 即base目录
Database 设计
• 建议以业务功能来命名数据库, 简单直观
• 推荐使用兼容PG模式创建数据库
• 数据库编码建议使用UTF8
Schema 设计
• 在一个数据库下执行创建用户时, 默认会在该数据库下创建一个同名schema
• 不建议在默认public schema下创建数据库对象
• 创建一个与用户名不同的schema给业务使用
Table 设计
• 规划好表结构设计, 避免添加字段、 修改字段类型或长度
• 禁止使用unlogged、 temp/temporary 关键字创建业务表
• 必须为表添加comment注释信息
• 表间关联字段数据类型要保持一致, 避免索引无法使用
• 对于频繁更新的astore表, 需要指定填充因子fillfactor=85, 给HOT预留空间
• 频繁更新使用的表应该单独放在存储性能好的表空间
• 数据量超过亿级或占用磁盘超过10GB的表, 建议考虑分区
Cloumn 设计
• 避免与系统表的列名重复
• 字段含义及数据类型要与程序代码设计保持一致
• 所有字段必须要添加comment注释信息
• 能使用数值类型, 就不要使用字符类型
• 禁止用字符类型存储日期数据
• 时间类型字段统一使用timestamptz
• 字段尽量要求not null, 为字段提供默认值
Sequence 设计
• 禁止手动创建与表相关的序列, 应指定serial/bigserial类型方式创建
• 序列的步长建议设置为1
• 不建议设置minvalue 和 maxvalue
• 不建议设置cache, 设置cache后序列号不连续
• 禁止开启cycle
Index 设计
• 频繁DML操作的表索引数量不建议超过5个
• create/drop index时添加concurrently参数
• 真正创建索引前可以使用虚拟索引确定索引的有效性
• 经常出现在关键字order by、 group by、 distinct后面的字段, 建立索引
• 经常用作查询选择的字段, 建立索引
• 经常用作表连接的属性上, 建立索引
• 复合索引的字段数不建议超过3个
• 复合索引得一个字段是常用检索条件
• 复合索引第一个字段不应存在单字段索引
• 用unique index 替换 unique constraints
• 对数据很少被更新的表, 经常只查询其中的几个字段, 考虑使用索引覆盖
• 不要在有大量相同取值的字段上建立索引
Partition Table 设计
• 范围分区表数量不建议超过1000个
• 分区表可以按使用频度选择表空间
• 分区键必须要有索引, 不建议使用全局索引
• 定期清理历史分区表
View 设计
• 尽量使用简单视图, 减少复杂视图(数据来自多个表, 表的数量不建议超过3个)
• 避免嵌套视图, 如必须使用, 不能嵌套2层
Constraint 设计
• 每张表必须要有主键
• 不要用有业务含义的字段做主键, 尽管其唯一
• 建议使用id serial/bigserial primary key的方式创建主键
• 大表添加主键可以使用unique + not null的方式替代
• 建议使用唯一索引替换唯一约束
• 所有非空列必须要添加not null 约束
• 存在外键关系的表尽量添加外键约束
• 性能要求高而安全性自己控制的系统不建议使用外键


经过 8 小时的认真学习,那么还需要参加结营考试,对于结营考试那是相当残酷的,等待你的是为期一个小时的 25 道单选和多选测试题,80 才算合格意味着你只能错 5 道题,庆幸的是开卷,你可以查阅资料,不幸的是知识点分散,涉及到方方面面难度比较大,也是正因为此,今天官方将及格分数降到了 60。
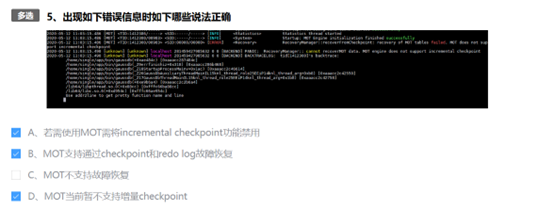

槽点
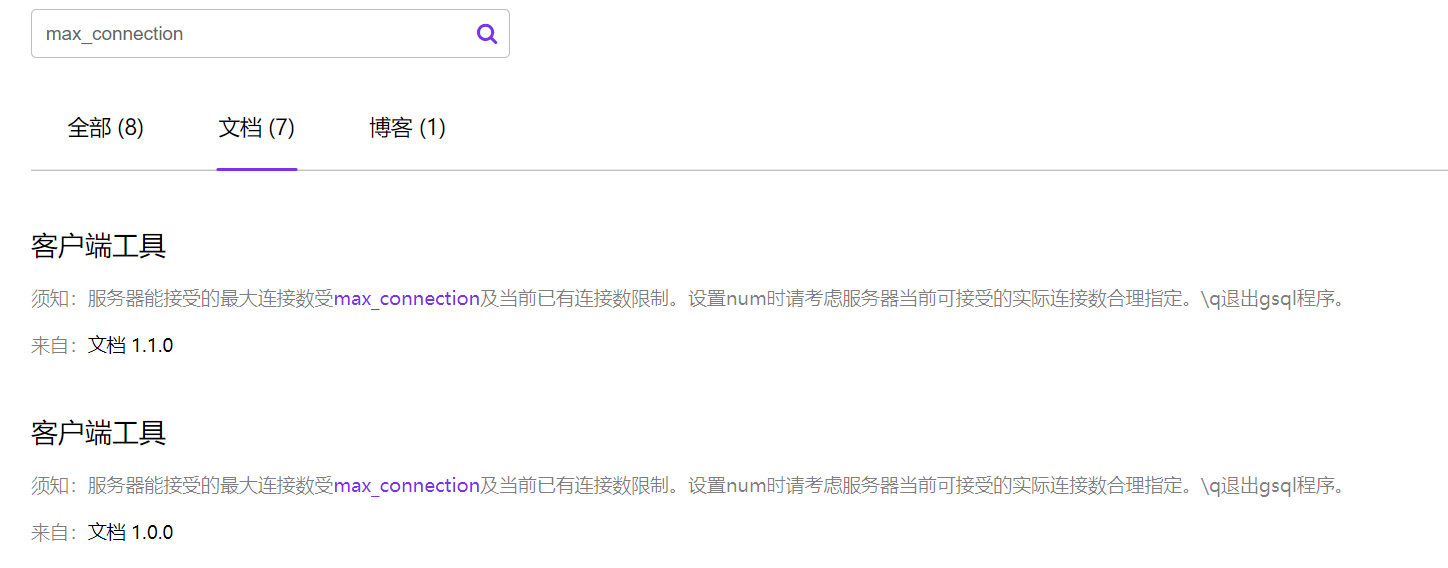
最后,这里也有个吐槽点,就是官方文档的问题,据说 openGauss 是国产数据库中,官方文档比较全面的(PS:有的国产数据库官方文档还需要注册账号,下载才能阅读,这里就不吐槽了),可我就想看数据库的最大连接数是多少时,一搜官方文档居然没有找到相关的说明,昨天查看视图时也是一个简单的字段说明,视图的具体作用啥的基本没提,谁知道写的啥。这点在国产数据库中是通病,文档建设不全,文档架构也不完善,需要花费更大的人力物力投入进去才能有所收获,这也是一件很不容易的事情,但也是必须要做的事情,Oracle 健全的官方文档 DOC,强大的知识库 MOS 是值得国产数据库学习的。openGauss 在文档建设方面还需要加强,真的是 openGauss 爱你不容易!!!
JiekeXu 写在 20220520
———————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
腾讯云:https://cloud.tencent.com/developer/user/5645107
———————————————————————————

