




原文地址:https://dzone.com/articles/what-are-vector-databases
原文作者:Jun Gu、Frank Liu
在这篇入门级文章中,我们将介绍与向量数据库相关的概念,向量数据库是一种旨在存储、管理和搜索嵌入向量的新技术。

相关概念参考链接:https://www.modb.pro/wiki/2411
在这篇入门级文章中,我们将介绍与向量数据库相关的概念,向量数据库是一种旨在存储、管理和搜索嵌入向量的新技术。向量数据库被用于越来越多的应用中,包括但不限于图像搜索,推荐系统,文本理解,视频摘要,药物发现,股票市场分析等等。
关系技术是不够的
数据无处不在。在互联网的早期,数据主要是结构化的,可以很容易地在关系数据库中存储和管理。以图书数据库为例:
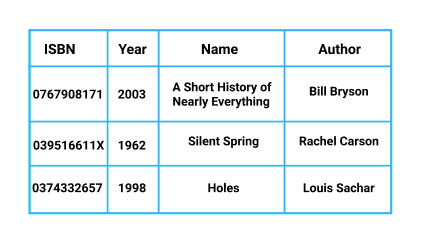
跨表存储和搜索基于表的数据(如上所示)正是关系数据库的设计目的。在上面的示例中,数据库中的每一行都表示一本特定的书籍,而列对应于特定类别的信息。当用户通过线上服务查找书籍时,他们可以通过数据库中存在的任何列名称来查。例如,查询作者姓名为Bill Bryson的书将返回Bryson所有书籍结果。
随着互联网的崛起和发展,非结构化数据(杂志文章,共享照片,短视频等)变得越来越普遍。不同于结构化数据,没有简单的方法可以将非结构化数据的内容存储在关系数据库中。例如,想象一下,给定一组鞋子图片,尝试从各个角度搜索类似的鞋子;这在关系数据库中是不可能的,因为纯粹从图像的原始像素值来理解鞋子的款式,尺寸,颜色等是不可能的。
X2vec:一种了解数据的新方法
这就把我们带到了向量数据库。非结构化数据的日益普遍导致使用经过训练的机器学习模型来了解此类数据的频率稳步上升。Word2vec是一种自然语言处理(NLP)算法,它使用神经网络来学习单词关联,是一个众所周知的早期例子。word2vec模型能够将单个单词(以多种语言,而不仅仅是英语)转换为浮点值或向量的列表。由于机器学习模型的训练方式,彼此接近的向量表示彼此相似的单词,因此称为嵌入向量。我们将在下一节中更详细(使用代码!)地介绍。
将一段非结构化数据转换为数值列表的想法并不是什么新鲜事。随着深度学习在学术界和工业界的蓬勃发展,呈现文本、音频和图像的新方法应运而生。所有这些表示的一个共同组成部分是它们使用由经过训练的深度神经网络生成的嵌入向量。回到word2vec的例子,我们可以看到生成的嵌入向量包含重要的语义信息。
早期的计算机视觉和图像处理依赖于局部特征描述符号将图像变成嵌入向量“包” - 每个检测到的关键点对应一个向量。SIFT,SURF和ORB是您可能听说过的三个众所周知的功能描述符号。虽然这些特征描述符号对于将图像相互匹配很有用,但事实证明,这是一种相当糟糕的表示音频(通过频谱图)和图像的方式。
python
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
示例: Apple, the Company, the Fruit, … 或两者都有?
词语 “apple” 既可以指某公司也可以指美味的红苹果。 在此示例中,我们可以看到Word2Vec包含两种释义。
python
print(model.most_similar(positive=['samsung', 'iphone'], negative=['apple'], topn=1))
print(model.most_similar(positive=['fruit'], topn=10)[9:])
[(‘droid_x’, 0.6324754953384399)].
[(‘apple’, 0.6410146951675415)].
“Droid” 指的是三星的第一款4G LTE智能手机(“Samsung” + “iPhone” - “Apple” = “Droid”), 而“apple”是最接近“水果”的第10个词。

虽然有更新和更好的深度学习算法/模型用于生成词嵌入(ELMo,GPT-2和BERT,仅举几例),但概念保持不变。
从多层神经网络生成的向量包含足够的高级信息,适用于各种任务。
向量嵌入不仅限于自然语言。在下面的示例中,我们使用towhee库为三张不同的图片生成嵌入向量,其中两个图像具有相似的内容:
生成嵌入
现在,让我们使用towhee为我们的图片生成嵌入。
from towhee import pipeline
p = pipeline('image-embedding')
dog0_vec = p(dog0)
dog1_vec = p(dog1)
car_vec = p(car)
from sklearn.preprocessing import normalize
dog0_vec = normalize(dog0_vec[0])
dog1_vec = normalize(dog1_vec[0])
car_vec = normalize(car_vec[0])
计算距离
import numpy as np
print('dog0 to dog1 distance:', np.linalg.norm(dog0_vec - dog1_vec))
print('dog0 to car distance:', np.linalg.norm(dog0_vec - car_vec))
dog0 to dog1 distance: 0.59794164
dog0 to car distance: 1.1380062
跨向量搜索
现在我们已经看到了向量嵌入的表征能力,让我们花一点时间简要讨论一下向量的索引。与关系数据库一样,向量数据库需要可搜索才能真正有用:仅仅存储向量及其关联的元数据是不够的。这被称为最近邻搜索,或简称NN(nearest neighbor)搜索,由于提出的解决方案数量庞大,因此可以单独被认为是机器学习和模式识别的子领域。
向量搜索通常分为两个部分:相似度指标和索引。相似性指标定义了如何评估两个向量之间的距离,而索引是便于搜索过程的数据结构。相似性度量相当简单:最常见的相似性度量是L2范数(也称为欧几里得距离)的倒数。另一方面,存在一组不同的指数,每个指数都有自己的优缺点。我们不会在这里详细介绍向量指数(这是另一篇文章的主题)。只要知道,如果没有它们,单个查询向量将需要与数据库中的所有其他向量进行比较,从而使查询过程变得非常长。
整合
现在,我们已经了解了嵌入向量的表示能力,并对向量搜索的工作原理有了总体概述,现在是时候将这两个概念放在一起了。欢迎来到向量数据库的世界。向量数据库专门用于存储、索引和查询通过机器学习模型传递非结构化数据而生成的嵌入向量。
当嵌入向量的庞大数据量打到一定比例时,跨嵌入向量(即使使用索引)进行搜索可能非常昂贵。尽管如此,除了指定您选择的索引算法和相似性指标外,最好和最先进的向量数据库将允许您在数百万甚至数十亿个目标向量中插入和搜索。
与预生产环境的关系数据库一样,向量数据库在实际生产环境中部署之前,应满足一些关键性能目标:
1.可扩展性:嵌入向量在绝对存储方面相当小,但为了促进读写速度,它们通常存储在内存中(基于磁盘的NN/ANN搜索是另一篇博客文章的主题)。当扩展到数十亿个嵌入向量及更多时,存储和计算对于单台计算机来说很快就会变得难以管理。分片可以解决这个问题,但这需要在多台计算机之间拆分索引。
2.可靠性:现代关系数据库具有容错能力。复制允许云原生企业数据库避免单点故障,从而实现正常启动和关闭。向量数据库也不例外,它应该可以在不丢失数据的情况下处理内部故障,并且对操作的影响最小。
3.快速性:是的,查询和写入速度很重要,即使对于向量数据库也是如此。一个越来越常见的用例是实时处理数据库输入并为其编制索引。对于像Snapchat和Instagram这样的平台来说,每秒可以上传数百或数千张新照片(一种非结构化数据),速度成为了一个至关重要的因素。
随着数据以前所未有的速度生成,通过向量数据库了解所有数据日益重要。
世界上最先进的向量数据库
Milvus是一款开源向量数据库,是这个领域的领导者。Milvus提供了许多示例,您可以使用这些示例来评估向量数据库的功能和用例。随着Milvus2.0 GA的发布,Milvus现在是一个云原生的容错系统,能够以数以亿计的规模索引向量。设置是通过一个简单的docker命令完成的,而跨Milvus的插入和查询可以通过我们的Python、Go、Node.js或Java绑定来完成。有关更多信息,请访问milvus.io。
我们希望本文中的信息对您有用。我们将定期发布帖子,因此请随时来获取有关向量数据库,非结构化数据或AI/ML的更多材料。
相关文章可参考原作者的主页,链接如下:
Jun Gu:https://dzone.com/users/4361141/gujun720.html
Frank Liu:https://dzone.com/users/4699357/liuf-stanford.html
