





点击上方蓝字,关注我们
01
vacuum
什么时候会触发autovacuum?
1.当update,delete的tuples数量超过 autovacuum_vacuum_scale_factor * table_size + autovacuum_vacuum_threshold
2.指定表上事务的最大年龄配置参数autovacuum_freeze_max_age,默认为2亿,达到这个阀值将触发 autovacuum进程,从而避免 wraparound 事务回卷。
每个表dead tuples的数量(包括用户表和系统表)
# 每一行的空间(pg_class.relpages pg_class.reltuples)
relpages:该表磁盘表示的尺寸,以页面计(页面尺寸为BLCKSZ)。这只是一个由规划器使用的估计值。它被VACUUM、ANALYZE以及一些DDL命令(如CREATE INDEX)所更新。
reltuples:表中的存活行数。这只是一个由规划器使用的估计值。它被VACUUM、ANALYZE以及一些DDL命令(如CREATE INDEX)所更新。
其中两个参数分别为:autovacuum_vacuum_threshold = 50 #阈值autovacuum_vacuum_scale_factor = 0.2 #比例因子复制
死亡元组数可以认为是pg_stat_all_tables中n_dead_tup的值。
由以上公式可以看出,一般在dead tuple达到20%时,会进行自动清理,50行的阈值是为了防止非常频 繁地清理微小的表。这个默认的比例比较适用于中小表,但如果表较大时,比如10GB大小的表,dead tuple达到2GB时才清理,这在清理的过程中会严重影响性能,一般来说解决方案有两种:
一是调小大表的比例因子
二是放弃比例因子,调大阈值
比较理想的方案:
ALTER TABLE test SET (autovacuum_vacuum_threshold = 100);复制
触发autovacuum的消耗:
vacuum_cost_page_hit = 1 #如果页面是从shared_buffers读取的,则计为1
vacuum_cost_page_miss = 10 #如果在shared_buffers找不到并且需要从操作系统中读取,
则计为10(它 可能仍然从RAM提供,但我们不知道)
vacuum_cost_page_dirty = 20 #当清理修改一个之前干净的块时需要花费的估计代价,它表示再次把脏块刷 出到磁盘所需要的额外I/O,默认值为20
再加上另外两个参数即可计算出清理操作的成本:
autovacuum_vacuum_cost_delay = 20ms #每次完成清理后睡眠20ms
autovacuum_vacuum_cost_limit = 200 #完成一次清理的消耗限制
比如:延迟20ms,则每秒可以清理50轮,乘以200后,即为10000的成本,那么:
02
检查点的作用
1.将事务提交的修改写进disk(写脏数据);保证数据库的完整性和一致性。
2.缩短恢复时间,将脏页写入相应的数据文件,确保修改后的文件通过fsync()写入到磁盘。
检查点触发条件:
1.checkpoint_timeout 设置的间隔时间自上一个检查点已经过去(默认间隔为 300 秒(5 分钟))。
2.在 9.4 或更早版本中,为checkpoint_segments设置的 WAL 段文件的数量自上一个检查点以来已经被消耗(默认数量为 3)。
3.在 9.5 或更高版本中,pg_xlog(在 10 或更高版本中为 pg_wal)中的 WAL 段文件的总大小已超过参数max_wal_size的值(默认值为 1GB(64 个文件))。
4.PostgreSQL 服务器在smart或fast模式下停止。
5.当超级用户手动发出 CHECKPOINT 命令时,它的进程也会这样做。
6.写入WAL的数据量已达到参数max_wal_size(默认值:1GB)
7.执行pg_start_backup函数时
8.在进行数据库配置时(例如CREATE DATABASE DROP DATABASE语句)
checkpoint_timeout (integer)
checkpoint_completion_target (floating point)
checkpoint_flush_after (integer)
checkpoint_warning (integer)
max_wal_size (integer)
min_wal_size (integer)
03
PITR和WAL复制

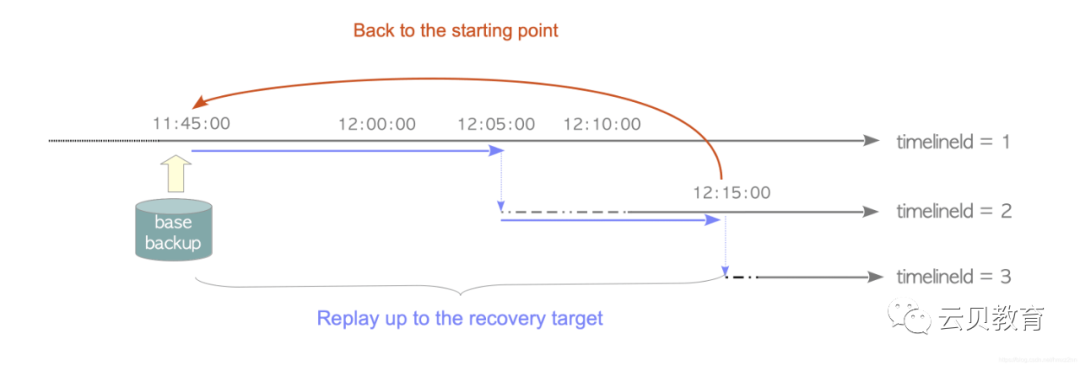
PITR模式下的PostgreSQL会在基础备份上重放归档日志中的WAL数据,从pg_start_backup创建的重做点开始,恢复到你想要的位置为止。在PostgreSQL中,想要恢复到的位置被称为恢复目标。
时间线历史文件在第二次及后续PITR过程中起着重要作用。通过尝试第二次恢复,我们将探索如何使用它。同样,假设你在12:15:00时间点又犯了一个错误,错误发生在时间线ID为2的数据库集簇上。
restore_command ='cp opt/pg_arch/%f %p'recovery_target_time = "2018-7-16 12:15:00 GMT"recovery_target_timeline = 2参数recovery_target_time被设置为犯下新错误的时间,而recovery_target_ timeline被设置为2,以便沿着这条时间线恢复。复制
配置归档命令mkdir opt/archvi $PGDATA/postgresql.auto.confarchive_mode = onarchive_command = 'DATE=`date +%Y%m%d`; DIR="/opt/arch/$DATE"; (test -d $DIR || mkdir -p $DIR) && cp %p $DIR/%f'wal_level = replica使用pg_basebackup备份数据库mkdir home/postgres/bak/pg_basebackup -D home/postgres/bak/ -Ft -P -R -Upostgresselect * from t_rec;更新数据,模拟宕机createtable t_rec (id int,time timestamp);insert into t_rec values (1,now());insert into t_rec values (2,now());insert into t_rec values (3,now());insert into t_rec values (4,now());insert into t_rec values (5,now());select pg_switch_wal();checkpoint;select * from t_rec;关闭实例pg_ctl -m f stop删除pg_root13数据库目录rm -rf /opt/pg_root13/*基于时间点恢复将备份的数据文件解压到$PGDATA目录,wal日志解压放到$PGDATA/pg_wal目录mkdir /opt/pg_root13/pg_waltar -xvf /home/postgres/bak/base.tar -C /opt/pg_root13tar -xvf /home/postgres/bak/pg_wal.tar -C /opt/pg_root13/pg_walchmod 0700 /opt/pg_root13rm -f opt/pg_root13/standby.signaltouch opt/pg_root13/recovery.signalchmod 600 opt/pg_root13/recovery.signal编辑$PGDATA/postgresql.auto.conf文件restore_command = 'cp /opt/arch/20220325/%f %p'recovery_target_timeline = 'latest'启动数据库%p 表示wal文件名$PGDATA的相对路径, 如pg_wal/00000001000000190000007D%f 表示wal文件名, 如00000001000000190000007D启动DBpg_ctl start复制
postgresql.auto.conf内容参考listen_addresses = '0.0.0.0'port = 5432max_connections = 1000shared_buffers = 410MBwal_buffers = 120MBsuperuser_reserved_connections = 20unix_socket_directories = '.'unix_socket_permissions = 0700tcp_keepalives_idle = 60tcp_keepalives_interval = 10tcp_keepalives_count = 10vacuum_cost_delay = 10bgwriter_delay = 10mssynchronous_commit = offwal_writer_delay = 10mslog_destination = 'csvlog'logging_collector = onlog_directory = 'pg_log'log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'log_file_mode = 0600log_truncate_on_rotation = onlog_rotation_age = 1dlog_rotation_size = 10MBhot_standby = onarchive_mode = onarchive_command = 'DATE=`date +%Y%m%d`; DIR="/opt/arch/$DATE"; (test -d $DIR || mkdir -p $DIR) && cp %p $DIR/%f'wal_level = replicarestore_command = 'cp opt/arch/20220325/%f %p'recovery_target_timeline = 'latest'复制

那流复制是怎么实现的呢?
主要涉及到几个backend辅助进程:walwriter,walsender,&&& walreceiver,startup。
当用户连接进行数据操作,产生对应的WAL日志记录后,walwriter会周期性地把产生的WAL page刷新到磁盘中,如果配置了备库,则walsender会不断将WAL page发给备库的walreceiver进程,walreceiver进程会把对应WAL page直接写到本地磁盘,同时slave上的startup辅助进程会不断地应用xlog日志,改变本地数据,实现与主库之间的数据同步。
而且,通过配置,备库是可以接受用户的只读请求。
wal_levelmax_wal_sendershot_standbywal_keep_segmentssynchronous_commit单机on 写入wal segment中Off 写入buffer就会返回成功Local 和on的类似流复制On 本地wal落盘、备库wal落盘。remote_apply 本地wal已落盘、备库wal已落盘并且已完成重做。remote_write 需等待备库接收主库发送的日志流,并写入备节点操作系统缓存中,之后返回成功复制
*PostgreSQL配置优化(三)
持续更新中...

