




上个月的时候,我发了一篇文章,mysql之从服务器状态变量角度看max、min优化。
细节不再赘述,总之文章最后得出一结论:
针对需要使用max或者min函数的场景,可以考虑替换成order by id desc/acs limit 1。
于是,我在我的代码中美滋滋地用了这个tip,在我需要使用max(id)的时候,全都用了order by id desc limit 1
代替,刚开始一切都很正常,我为用到这个小tip,而沾沾自喜。

但是,就在几天前,我突然收到了一条数据库cpu满了的告警,然后在数据库的当前会话中赫然发现了我的那条order by id desc limit 1
的SQL,并且他已经执行了20分钟了?!!
当即我就震惊加疑惑了🤔, 不是说好order by id desc limit 1
优化很明显的吗?怎么执行了这么久??

我就把这条SQL拎出来,又使用max(id)的方式查了一遍,发现max(id) 执行很快......。
接下来我还是像这篇中介绍的一样,从Innodb_rows_read角度比较两个语句的资源消耗。
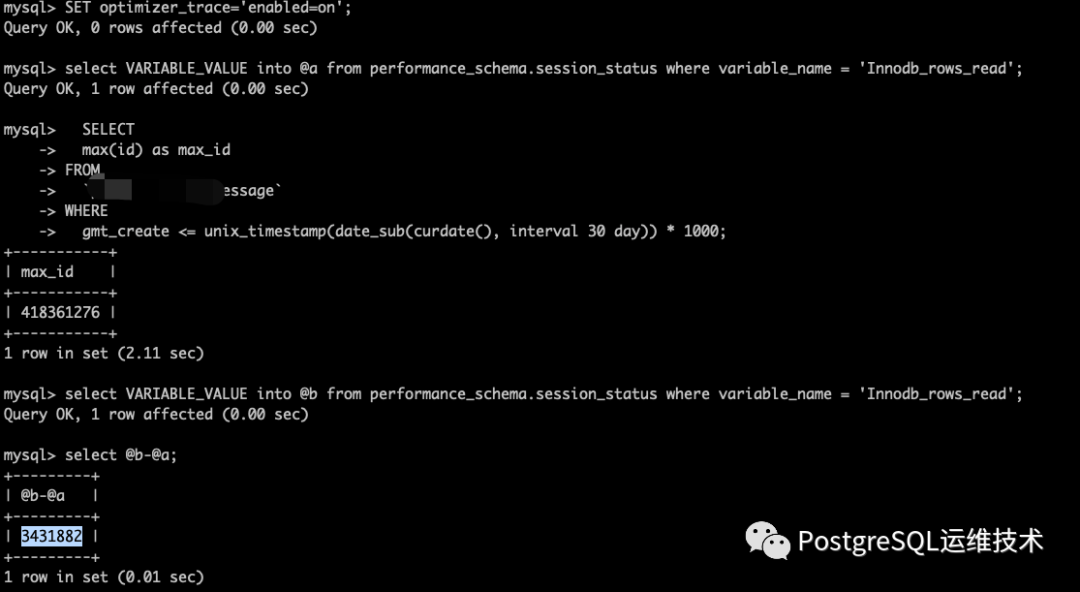
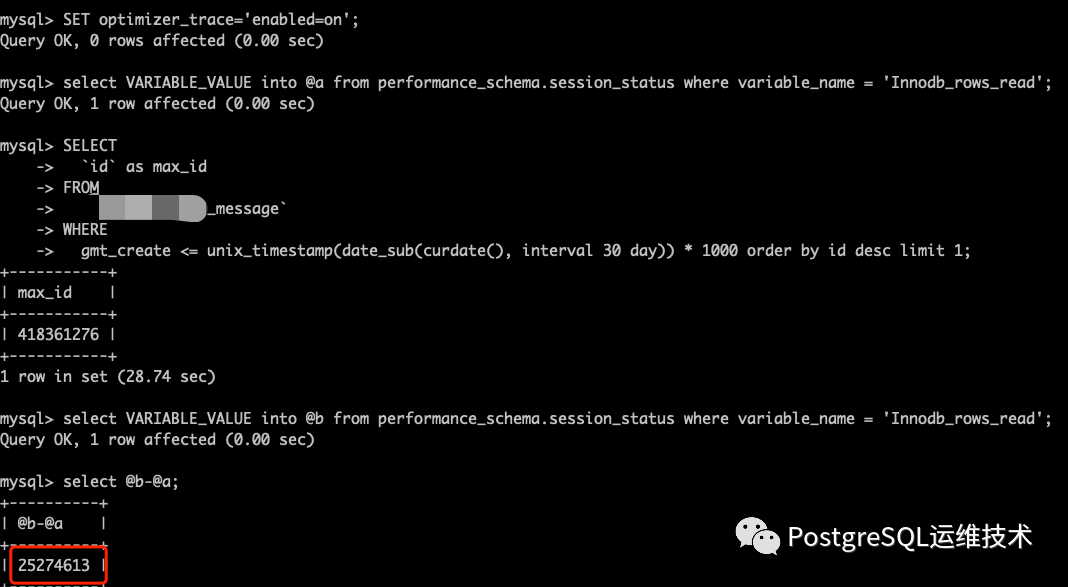
然而这次,max(id)
的方式Innodb_rows_read的增量是3421882,而order by id desc limit 1
的方式,Innodb_rows_read的增量是25274613。后者的资源消耗又明显多于前者了。

猜想造成这种差异的原因,应该是跟表中数据分布有关的。emmmm,所以说,还是不能一概而论啊。
为了避免在这种情况时CPU被打爆,我最后采用的方案是:在SQL里面加了max_execution_time,如果一定时间内order by id desc limit 1
取不到数据,再换成max(id)的方式来。不再一味依赖order by id desc limit 1
了。
果然,还是实践出真知啊。


点个“赞 or 在看” 你最好看!
👇👇👇下面的咔片谢谢各位老板啦




