




原文链接:Table size in YugabyteDB, PostgreSQL and Oracle 🅾🐘🚀
原文作者:Franck Pachot
PostgreSQL 和 YugabyteDB 的协议和 SQL 处理是一样的,但是存储是不同的。今天,磁盘上的大小并不是最昂贵的资源,而且由于高可用性和性能的原因,在向外扩展的分布式数据库中也不是一个大问题。 但是,当跨数据库迁移时,最好了解存储大小。特别是在遗留数据库(堆表、B-Tree 索引、8k 块页面)和分布式数据库(文档存储、LSM 树、SST 文件)之间。
我正在以最小的部署进行ybdemo实验:
git clone https://github.com/FranckPachot/ybdemo.git cd ybdemo/docker/yb-lab # create a minimal RF=1 deployement sh gen-yb-docker-compose.sh minimal # stop the demo containers docker-compose kill yb-demo-{read,write,connect}复制
在单节点集群上查看大小更容易。 当分布到更多的节点时,总大小不会改变。 当添加高可用性与复制因子RF=3总大小乘以3。 但这里我感兴趣的是磁盘上的原始大小。
我连接到 tserver 节点:
docker exec -it yb-tserver-0 bash复制
生成 csv
我将使用以下函数来生成数据。
gen_random_csv生成大小为 $1 到 $2 列的随机字母数字到 $3 行中以加载到 $4 表中gen_table_ddl生成 CREATE TABLEgen_pg调用这些函数来创建表并使用COPY插入行。 PostgreSQL很简单,而YugabyteDB受益于所有这些特性,可以扩展到分布式存储。
gen_random_csv(){ cat /dev/urandom | tr -dc '[:alpha:]' | fold -w $1 | awk ' NR%m==1{if(NR>1)print "";d=""} {printf d $0 ; d=","} ' m=$2 | head -$3 | nl -s "," } gen_table_ddl(){ echo -n "create table $4 ( id bigint primary key check (id<=$3)" for i in $(seq 1 $2) do echo -n ", col$i varchar($1)" done echo ");" } gen_pg(){ echo "drop table if exists $4;" gen_table_ddl $1 $2 $3 "$4" echo "copy $4 from stdin with csv;" gen_random_csv $1 $2 $3 "$4" echo "\\." }复制
YugabyteDB
加载 1000 行
作为第一个测试,我加载了1000行60列的VARCHAR(100),看看它是如何工作的:
time gen_pg 100 60 1000 franck_varchar | ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON复制
指标包括以下franck_varchar表:
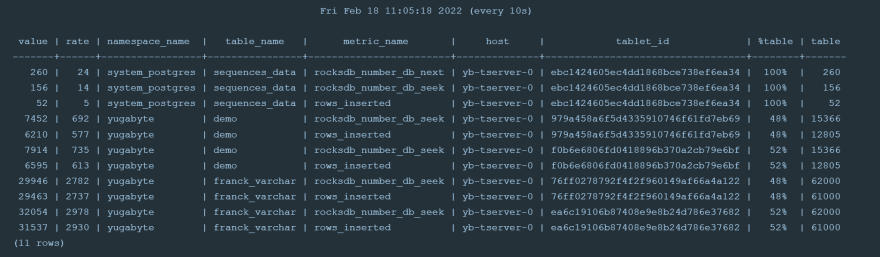
1000 行 60 列在 DocDB 中存储为 61000 个子文档:每行 1 个,每列 1 个。这被分配到 2 个tablets中(我的默认设置是每个 tserver 2 个tablets)。每行都必须查找主键以检查重复项,这就是为什么 YSQL 接口比仅附加新版本的 YCQL 接口需要更长的加载时间。
如果你是YugabyteDB的新手,你可能会惊讶地发现这个表的大小为0:

默认情况下,第一级存储是128MB的MemTable。 我的1000行适合它,然后没有任何内容存储到 SST 文件中。 当然,这是受WAL保护的,我看到了加载的6MB数据。 在崩溃的情况下,可以从其中恢复MemTable。
现在让我们插入更多数据,以便将 MemTable 刷新到 SST 文件。
加载 600M
我生成这个来测量原始大小:
time gen_pg 100 60 100000 franck_varchar | wc -c | numfmt --to=si复制
结果:607M
我运行它来创建和加载表:
time gen_pg 100 60 100000 franck_varchar | ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON复制
以下是来自http://tserver:9000/tables端点的存储详细信息。
文件系统中的数字显示相同:

[root@yb-tserver-0 yugabyte]# du -h | grep 000030af00003000800000000000406a | sort -h 4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17.snapshots 4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0.snapshots 92K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17.intents 92K ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0.intents 282M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17 283M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0 395M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a/tablet-0d3e98af78354a43bcaef9fc2e37da17 395M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a/tablet-7bdf68bb1b324ff0baccfdb24e7d6ba0 565M ./data/yb-data/tserver/data/rocksdb/table-000030af00003000800000000000406a 789M ./data/yb-data/tserver/wals/table-000030af00003000800000000000406a复制
不计算用于保护内存结构的临时WALs,磁盘上的大小小于CSV大小。
加载 6.1 GB
现在加载一百万行:
time gen_pg 100 60 1000000 franck_varchar | ysqlsh -h $(hostname) -e -v ON_ERROR_STOP=ON复制
输出显示了DDL,我的笔记本电脑上的加载时间,以及生成和只计算大小的时间:
drop table if exists franck_varchar; DROP TABLE create table franck_varchar ( id bigint primary key check (id<=1000000), col1 text, col2 text, col3 text, col4 text, col5 text, col6 text, col7 text, col8 tex t, col9 text, col10 text, col11 text, col12 text, col13 text, col14 text, col15 text, col16 text, col17 text, col18 text, col19 text, col20 text, col21 text, col22 text, col23 text, col24 text, col25 text, col26 text, col27 text, col28 text, col29 text, col30 text, col31 text, col32 text, col33 text, col34 text, co l35 text, col36 text, col37 text, col38 text, col39 text, col40 text, col41 text, col42 text, col43 text, col44 text, col45 text, col46 text, col47 text, col4 8 text, col49 text, col50 text, col51 text, col52 text, col53 text, col54 text, col55 text, col56 text, col57 text, col58 text, col59 text, col60 text); CREATE TABLE copy franck_varchar from stdin with csv; COPY 1000000 real 19m0.471s user 15m30.699s sys 14m54.813s [root@yb-tserver-0 yugabyte]# time gen_pg 100 60 1000000 franck_varchar | wc -c | numfmt --to=si 6.1G real 7m18.488s user 10m15.511s sys 12m7.927s复制
我的表存储在 6.4 GB 中:

我从文件系统中得到相同的图片:
[root@yb-tserver-0 yugabyte]# du -h | grep 000030af000030008000000000004070 | sort -h 4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132.snapshots 4.0K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222.snapshots 92K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132.intents 92K ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222.intents 1.6G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132 1.6G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222 3.2G ./data/yb-data/tserver/wals/table-000030af000030008000000000004070 3.3G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-9fea5fced0924eebb7a978be7cd83132 3.3G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070/tablet-f6dffe42f77044deadd217ea3aeb7222 6.5G ./data/yb-data/tserver/data/rocksdb/table-000030af000030008000000000004070复制
基本上,我在数据库中的数据大小和我输入的CSV文本大致相同。
WAL 大小
WAL的作用是保护在内存中所做的更改(LSM树的第一级是一个MemTable)。 它具有由以下参数定义的保留,我使用默认设置:
--log_min_seconds_to_retain=900 --log_min_segments_to_retain=2 --log_segment_size_mb=64复制
这意味着在这个表上15分钟没有活动之后,它应该会被tablets缩小到2x64MB的段,而我有两个tablets。 这是我午休后的照片:

压缩
我这里有5个SST文件,因为默认的,所以不会触发进一步的自动压缩
rocksdb_level0_file_num_compaction_trigger=5复制
我可以手动运行一个:
time yb-admin --master_addresses $(echo yb-master-{0..2}:7100|tr ' ' ,)\ compact_table_by_id 000030af000030008000000000004070 300复制
这将减少到每片一个文件:

在我的示例中,总大小没有改变,因为我只加载了没有进一步更改的行,所以没有旧版本可以压缩。
PostgreSQL
我启动一个 PostgreSQL 容器来比较相同的负载
docker pull postgres docker run --name pg14 -e POSTGRES_PASSWORD=franck -d postgres docker exec -it pg14 bash复制
我运行与(上面定义的gen_random_csv和gen_table_ddl)相同的方法gen_pg来加载 600MB数据
time gen_pg 100 60 100000 franck_varchar | psql -U postgres -e -v ON_ERROR_STOP=ON复制
这很快:
drop table if exists franck_varchar; DROP TABLE create table franck_varchar ( id bigint primary key check (id<=100000), col1 varchar(100), col2 varchar(100), col3 varchar(100), col4 varchar(100), col5 varch ar(100), col6 varchar(100), col7 varchar(100), col8 varchar(100), col9 varchar(100), col10 varchar(100), col11 varchar(100), col12 varchar(100), col13 varchar (100), col14 varchar(100), col15 varchar(100), col16 varchar(100), col17 varchar(100), col18 varchar(100), col19 varchar(100), col20 varchar(100), col21 varch ar(100), col22 varchar(100), col23 varchar(100), col24 varchar(100), col25 varchar(100), col26 varchar(100), col27 varchar(100), col28 varchar(100), col29 var char(100), col30 varchar(100), col31 varchar(100), col32 varchar(100), col33 varchar(100), col34 varchar(100), col35 varchar(100), col36 varchar(100), col37 v archar(100), col38 varchar(100), col39 varchar(100), col40 varchar(100), col41 varchar(100), col42 varchar(100), col43 varchar(100), col44 varchar(100), col45 varchar(100), col46 varchar(100), col47 varchar(100), col48 varchar(100), col49 varchar(100), col50 varchar(100), col51 varchar(100), col52 varchar(100), col 53 varchar(100), col54 varchar(100), col55 varchar(100), col56 varchar(100), col57 varchar(100), col58 varchar(100), col59 varchar(100), col60 varchar(100)); CREATE TABLE copy franck_varchar from stdin with csv; COPY 100000 real 1m29.669s user 0m32.372s sys 1m14.037s复制
查看pg_relation_size时要小心:
postgres=# select pg_size_pretty(pg_relation_size('franck_varchar')), current_setting('data_directory') ||'/'||pg_relation_filepath('franck_varchar'); pg_size_pretty | ?column? ----------------+------------------------------------------- 195 MB | /var/lib/postgresql/data/base/13757/16384复制
如何用195MB存储600MB?这是因为我的行比一个页面可以容纳的要大(PostgreSQL以块的形式存储元组)。TOAST用于存储溢出。让我们看看我的数据库文件:
postgres=# \! du -ah /var/lib/postgresql/data/base/13757 | sort -h | tail -5 2.2M /var/lib/postgresql/data/base/13757/16390 105M /var/lib/postgresql/data/base/13757/16389 196M /var/lib/postgresql/data/base/13757/16384 661M /var/lib/postgresql/data/base/13757/16388 972M /var/lib/postgresql/data/base/13757复制
以下是目录中的相关元数据:
postgres=# select pg_size_pretty(pg_relation_size(oid)) , oid, relname, relkind, relpages, reltuples, reltoastrelid from pg_class where oid in (16390,16389,16384,16388) order by pg_relation_size(oid); pg_size_pretty | oid | relname | relkind | relpages | reltuples | reltoastrelid ----------------+-------+----------------------+---------+----------+-----------+--------------- 2208 kB | 16390 | franck_varchar_pkey | i | 276 | 100000 | 0 105 MB | 16389 | pg_toast_16384_index | i | 1 | 0 | 0 195 MB | 16384 | franck_varchar | r | 25000 | 100000 | 16388 660 MB | 16388 | pg_toast_16384 | t | 84483 | 4.9e+06 | 0复制
600MB在TOAST中,实际上是660 + 105MB用于索引。 我在表中有额外的195MB,用于non-toasted的列和行内部属性。 而且,由于 PostgreSQL 将表存储在堆表中,所以主键与索引有一个额外的关系,但是这个关系很小:只有2MB。总共需要 972MB 来存储 600MB 的原始数据。 当然,这会对查询性能产生影响,但这是另一个话题。
从这一点来看,由于堆表、页面和元组的原因,PostgreSQL 中的存储似乎不如使用 LSM 树和 SSTables 的 YugabyteDB 化。PostgreSQL 有一些优化,但基本上这种情况(我从我们slack channel的用户那里得到)不能从压缩中受益(阈值是 2KB 文本)。当然,您可能想知道在任何数据库中存储 60 列 100 个字符是否有意义。JSON 可能更适合它,因为它是一个文档。
Oracle Database
最开始的问题是与甲骨文的比较。
让我们启动一个容器:
docker pull gvenzl/oracle-xe docker run --name ora -e ORACLE_PASSWORD=franck -d gvenzl/oracle-xe复制
你得等一等, 空的Oracle数据库并不轻。 Docker日志记录ora,直到看到监听器成功启动。 不用担心The listener supports no services…它们将被动态注册。
我使用gen_table_ddl上面定义的创建表:
gen_table_ddl 100 60 100000 franck_varchar | sed -e '/create table/s/bigint/number/' | sqlplus system/franck@//localhost/xepdb1复制
我生成的CSV,如我上面所做的gen_random_csv,但现在到一个linux命名|被SQLLoader读取,因为我不认为SQLLoader可以从stdin读取:
mknod franck_varchar.dat p gen_random_csv 100 60 100000 > franck_varchar.dat &复制
并使用所有默认值的 SQL*Loader Express 调用:
time sqlldr system/franck@//localhost/xepdb1 table=franck_varchar复制
这很快:
从字典中快速检查大小:
sqlplus system/franck@//localhost/xepdb1 SQL> select segment_type||' '||segment_name||': ' ||dbms_xplan.format_size(bytes) from dba_segments where owner=user and segment_name in ( 'FRANCK_VARCHAR' ,(select index_name from user_indexes where table_name='FRANCK_VARCHAR')) ; SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES) -------------------------------------------------------------------------------- TABLE FRANCK_VARCHAR: 783M INDEX SYS_C008223: 2048K复制
和PostgreSQL一样,索引是2M。 堆表是783M,比我的原始数据稍高。 注意,我在这里保留了缺省PCTFREE。 当你在堆表上将它们的行存储到块中时,这些都是需要注意的。 Oracle有一些压缩选项,但对于这个,你需要购买Exadata来获得HCC,或者将你的数据移动到他们的云上。 其他表压缩选项在这里没有任何作用,因为没有重复的值。
这里,我在每一列中插入了100个字符,因为这是我的测试用例。 但我知道,在YugabyteDB中,将列存储为子文档对每列都有开销,这是基于块的堆表中可变大小行的开销。 然后我在gen_random_csv 1 60 100000的每列中只运行一个字符.
CSV 中的卷现在为 13MB:
# time gen_pg 1 60 100000 franck_varchar | wc -c | numfmt --to=si 13M复制
我已经导入了这个并检查了存储
甲骨文:
SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES) -------------------------------------------------------------------------------- TABLE FRANCK_VARCHAR: 8192K INDEX SYS_C008223: 2048K复制
8MB的数据,2MB的索引————这很小。 这甚至比CSV文件还少一点… 🤔但是,等等。 没有解释的实验结果是不可信的。 唯一可以更小的是NUMBER数据类型。 🤦♂️我记得我之前用ALTER TABLE franck_varchar MOVE COMPRESS做了一个测试,没有重新创建表。 它没有改变随机的100个字符值,但现在我有很多重复的每个块只有一个字符随机。
让我们在重新创建表的情况下再次运行它:
SEGMENT_TYPE||''||SEGMENT_NAME||':'||DBMS_XPLAN.FORMAT_SIZE(BYTES) -------------------------------------------------------------------------------- TABLE FRANCK_VARCHAR: 15M INDEX SYS_C008225: 2048K复制
是的,这是正确的。 如果没有压缩,卷只比原始卷加上索引高一点。
#### PostgreSQL: pg_size_pretty | ?column? ----------------+---------------------------------------------- 15 MB | /var/lib/postgresql/data/base/13757/19616663 oid | relname | reltoastrelid ----------+----------------+--------------- \! du -ah /var/lib/postgresql/data/base/13757 | sort -h | tail -5 752K /var/lib/postgresql/data/base/13757/1255 752K /var/lib/postgresql/data/base/13757/2840 2.2M /var/lib/postgresql/data/base/13757/19616667 16M /var/lib/postgresql/data/base/13757/19616663 27M /var/lib/postgresql/data/base/13757复制
这里没有TOAST, 2MB用于索引,16MB用于堆表。 PostgreSQL有大量的逐行元数据来管理锁和MVCC。
YugabyteDB:
Total: 328.32M Consensus Metadata: 19.7K WAL Files: 255.80M SST Files: 72.50M SST Files Uncompressed: 237.76M复制
因为文档存储中的每列存储,我预计会很大。 由于压缩,简单的基于增量编码的前缀压缩,以及默认的——enable_ondisk_compression=true——compression_type=Snappy,这不会带来太多好处。 当然,如果你将YugabyteDB与Oracle或PostgreSQL进行比较,会看到 4 倍的系数。 但这不是在现实生活中应该看到的,存储60列,其中只有一个字节。 我们拥有所有 PostgreSQL 数据类型,例如 ARRAY 或 JSONB。 对于填充列的增强,还有一个未解决的问题。 顺便说一下,我是在YugabyteDB 2.11.2中运行这个.
概括
我在一个特定的案例中做了这个测试,我得到了一个关于存储到YugabyteDB的大小的问题。 当然,所有这些都取决于列数、数据类型、值、写模式、数据库设置、读性能需求等等。 今天,开发人员没有时间对所有这些进行微调。像YugabyteDB平板存储所基于的RocksDB这样的键值对文档存储更容易。在压缩 SST 文件期间,少量的写入放大通过压缩来平衡。横向扩展的能力可以克服任何限制。
总之,现代SQL数据库也支持JSON文档,比如PostgreSQL JSONB,也可以在YugabyteDB或Oracle OSON中使用。 如果您有60列的文本,那么也许这应该放到一个文档中。



