




「目录」
数据聚合与分组运算
Data Aggregation and Group Operations
10.1 => GroupBy机制
10.2 => 数据聚合
10.3 => apply:拆分 - 应用 - 合并
10.4 => 透视表和交叉表
数据聚合
聚合指的是任何能够从数组到标量值的数据转换过程,比如mean、count、min以及sum等。
In [1]: import numpy as np
In [2]: import pandas as pd
In [3]: df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'], 'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})
In [4]: df
Out[4]:
key1 key2 data1 data2
0 a one 1.742646 -0.307503
1 a two 2.027999 0.013633
2 b one 1.317202 0.177529
3 b two 0.243344 -0.183811
4 a one 0.976750 0.034316
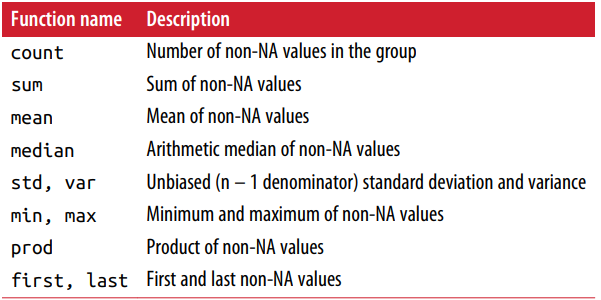
下面的表格就总结了很多常用的聚合方法,包括计数count,求和sum,求平均mean,中位数median,标准差std,最小值min,最大值max,乘积prod
quantile
quantile可以计算Series或DataFrame列的样本分位数,下面就是我们根据key1列分组,然后查看每个组在data1列0.9分位的值:
In [5]: grouped = df.groupby('key1')
In [6]: grouped['data1'].quantile(0.9)
Out[6]:
key1
a 1.970928
b 1.209816
Name: data1, dtype: float64
使用自己的聚合函数
若要使用自己的聚合函数,我们只需将其传入aggregate或agg方法:
In [7]: def peak_to_peak(arr):
...: return arr.max() - arr.min()
In [9]: grouped.agg(peak_to_peak)
Out[9]:
data1 data2
key1
a 1.051249 0.341819
b 1.073858 0.361340
Note : 使用自定义的函数要比上面那些经过优化的函数慢得多,空间开销也更大。
describe方法
describe方法会返回DataFrame或Series的统计变量
In [10]: grouped.describe()
Out[10]:
data1 ... data2
count mean std min 25% ... min 25% 50% 75% max
key1 ...
a 3.0 1.582465 0.543622 0.976750 1.359698 ... -0.307503 -0.146935 0.013633 0.023975 0.034316
b 2.0 0.780273 0.759332 0.243344 0.511809 ... -0.183811 -0.093476 -0.003141 0.087194 0.177529
[2 rows x 16 columns]
最近什么都不想做,就这样吧,bye-bye
往期回顾


Stay hungry, stay foolish
文章转载自Yuan的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
