





有些验证码是中文的,使用的时候可能发现了,并不能支持识别中文,那么我们应该如何解决呢?
1、python识别图片中的中文字符-old
先来看下默认的情况下识别中文是什么样子的呢,比如我们要识别下图:

然后我们写出如下代码:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\chinese_0.jpg")
text = pytesseract.image_to_string(image, lang='eng+osd')
print(text)
运行结果:
ffi’:
赖荤
蝴
可以看到并没有识别出来,是乱码;
2、安装tesseract新版本+tesseract语言包
python
通过tesseract
识别图形中文乱码,是因为你安装的时候没有选择合适的语言进行安装,上一文中我们是直接默认下一步安装的,且安装版本是tesseract-ocr-setup-3.02.02.exe
,这个版本在安装的时候确实可以选择其他语言进行支持,但是你只能选择
,并没办法进行下载
。且官网也没有对应该版本的语言支持包,所以我这里重新找了一个**5.1.0
**版本的程序包进行安装,这个软件包是没有问题的;
获取tesseract
软件包的方式为:
微信公众号“运维家”,后台回复:resseract
软件包
即可获取tesseract
软件包的网盘下载地址了;
tesseract
这个软件安装的过程中,windows
安装路径必须选择:
C:\Program Files (x86)\Tesseract-OCR
如果是windows
务必选择以上路径进行安装哈;
我们可以选择语言,点击Additional language data(download)
前面的符号,就会展示出来很多语言,如果识别的内容比较复杂,建议全选,将所有的语言包都下载下来,我这里为了演示,只选择了和中文有关的,也就是抬头是“Chinese”的;
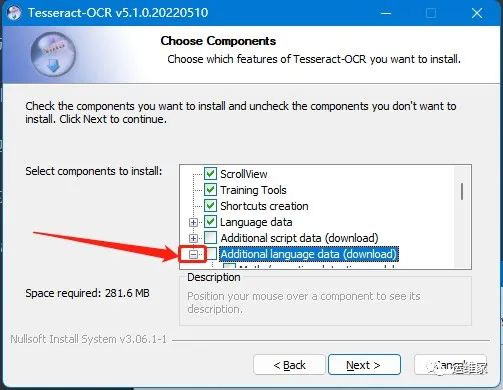
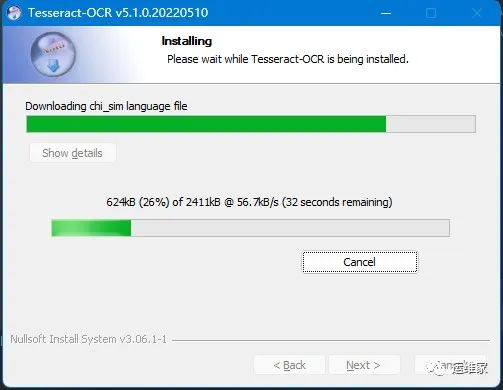
然后点击下一步即可,这里我们会看到下图的安装界面,可能会比较慢,因为他会一个个下载语言包,这里我们耐心等待即可;
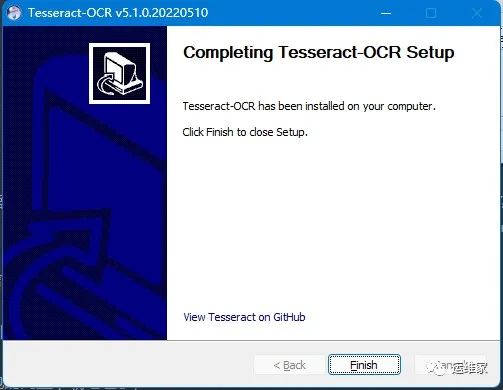
出现下面的界面就表示安装成功了;
tesseract
软件无法下载语言包,或者tesseract
下载语言包失败,如果有这种问题,是因为啥呢?那简单了,就是因为他的语言包在国外,网络不稳定所导致的,那么我们如何解决呢,我这里准备了一份完整的语言包,直接解压覆盖你resseract
安装路径中的tessdata
这个文件夹即可。
获取tesseract 5.1.0
语言包的方式为:
微信公众号“运维家”,后台回复:tesseract
语言包
即可获取tesseract
语言包的网盘下载地址了;
然后我们需要将C:\Program Files (x86)\Tesseract-OCR\tessdata
这个路径下的内容全部拷贝到C:\Program Files (x86)\Tesseract-OCR
目录下方可,不然会报错以下信息:
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:\\Program Files (x86)\\Tesseract-OCR\\eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'eng\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
3、再次使用tesseract进行中文识别
先来看下他现在支持多少种语言了吧;
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
print(pytesseract.get_languages())
运行结果如下:
['chi_sim', 'chi_sim_vert', 'chi_tra', 'chi_tra_vert', 'eng', 'osd']
当使用我上面提供的语言包之后,就会发现支持的语言变成了下面这么多:
['afr', 'amh', 'ara', 'asm', 'aze', 'aze_cyrl', 'bel', 'ben', 'bod', 'bos', 'bre', 'bul', 'cat', 'ceb', 'ces', 'chi_sim', 'chi_sim_vert', 'chi_tra', 'chi_tra_vert', 'chr', 'cos', 'cym', 'dan', 'deu', 'div', 'dzo', 'ell', 'eng', 'enm', 'epo', 'equ', 'est', 'eus', 'fao', 'fas', 'fil', 'fin', 'fra', 'frk', 'frm', 'fry', 'gla', 'gle', 'glg', 'grc', 'guj', 'hat', 'heb', 'hin', 'hrv', 'hun', 'hye', 'iku', 'ind', 'isl', 'ita', 'ita_old', 'jav', 'jpn', 'jpn_vert', 'kan', 'kat', 'kat_old', 'kaz', 'khm', 'kir', 'kmr', 'kor', 'lao', 'lat', 'lav', 'lit', 'ltz', 'mal', 'mar', 'mkd', 'mlt', 'mon', 'mri', 'msa', 'mya', 'nep', 'nld', 'nor', 'oci', 'ori', 'osd', 'pan', 'pol', 'por', 'pus', 'que', 'ron', 'rus', 'san', 'sin', 'slk', 'slv', 'snd', 'spa', 'spa_old', 'sqi', 'srp', 'srp_latn', 'sun', 'swa', 'swe', 'syr', 'tam', 'tat', 'tel', 'tgk', 'tha', 'tir', 'ton', 'tur', 'uig', 'ukr', 'urd', 'uzb', 'uzb_cyrl', 'vie', 'yid', 'yor']
这个时候我们再次来识别文章最开始的时候的图片,来看看是否识别出来了吧。
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\1654881934269.jpg")
text = pytesseract.image_to_string(image, lang='chi_sim+chi_sim_vert+chi_tra+chi_tra_vert')
print(text)
运行结果如下:
运维家
那么我们再来识别一张字比较多的图片再试试呢,例如:
运行代码
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"
image = Image.open(r"C:\Users\22768\Desktop\gzh\1654882172968.jpg")
text = pytesseract.image_to_string(image, lang='chi_sim+chi_sim_vert+chi_tra+chi_tra_vert')
print(text)
结果:
钟山风雨起苔划,百万雄师过大江。
虎跟龙盘今胜苦,天翻地覆慨而慷。
二将剩筋追穷坪,不可沽名学等王。
天吞有情天订老,人间正道是沧对 。
不可避免有一些错字,但是已经很少了。
至此,本文结束。相关内容每日更新。

往期推荐
