






全文检索是对大数据文本进行索引,在建立的索引中对要查找的单词进行搜索,定位哪些文本数据包括要搜索的单词。因此,全文检索的全部工作就是建立索引和在索引中搜索定位,所有的工作都是围绕这两方面进行的。
本章介绍DM8全文索引的创建和使用。
本章内容已在如下环境上测试:
①操作系统:中标麒麟7;
②数据库版本:达梦8;
相关关键字:
全文索引、CONTEXT INDEX、DM8
全文索引使用
1、构建测试用户和测试表
使用SYSDBA用户新建TEST用户,并赋予TEST用户创建表、创建全文索引的权限;
使用TEST用户创建测试表T_TEST。
create table t_test(id int primary key, name varchar(200), information text);复制

2、插入测试数据
使用如下命令插入测试数据:
insert into t_test(id, name, information)values(1, 'name1','全文检索是对大数据文本进行索引,在建立的索引中对要查找的单词进行进行搜索,定位哪些文本数据包括要搜索的单词。因此,全文检索的全部工作就是建立索引和在索引中搜索定位,所有的工作都是围绕这两个来进行的。');insert into t_test(id, name, information)values(2, 'name2', 'rlwrap依赖readline包,在安装之前需先检查操作系统是否安装有readline包。本机测试环境中标麒麟6最小化安装,系统默认已安装好readline包(若系统无readline包,可配置yum源,使用yum安装readline)。使用如下命令检查readline环境.');insert into t_test(id, name, information)values(3, 'name3', '武汉达梦数据库股份有限公司成立于2000年,为中国电子信息产业集团(CEC)旗下基础软件企业,专业从事数据库管理系统的研发、销售与服务,同时可为用户提供大数据平台架构咨询、数据技术方案规划、产品部署与实施等服务。多年来,达梦公司始终坚持原始创新、独立研发,目前已掌握数据管理与数据分析领域的核心前沿技术,拥有全部源代码,具有完全自主知识产权。达梦公司是国家规划布局内重点软件企业,同时也是获得国家“双软”认证和国家自主原创产品认证的高新技术企业,拥有国内数据库研发精英团队,多次与国际数据库巨头同台竞技并夺标。');复制
3、创建全文索引
在创建全文索引时,用户可以为分词器定义分词参数,即控制分词器分词的数量,包括CHINESE_LEXER(中文最少分词)、CHINESE_VGRAM_LEXER(机械双字分词)、CHINESE_FP_LEXER(中文最多分词)、ENGLISH_LEXER(英文分词)、DEFAULT_LEXER(默认分词,为中文最少分词)。
DM全文检索的中文分词依赖系统词库,该词库是只读的,不允许修改。指定中文分词参数可以切分英文,但是指定英文分词参数不可以切分中文。
在创建全文索引时,也可以使用SYNC关键字指明全文索引的同步类型。不指定SYNC时创建全文索引后系统不进行全文索引填充(需要用户后期手工填充);指定为SYNC时系统将在全文索引建立后对全文索引执行一次完全填充;指定为SYNC TRANSACTION时系统将在每次事务提交后,自动以增量更新方式填充全文索引,不需要用户手动填充。
使用如下语句给T_TEST表创建全文索引,索引名称为CNT_TEXT。我们这里使用默认分词和SYNC TRANSACTION同步方式。
create context index cnt_text on t_test(information)tablespace main sync transaction;复制

4、查询数据字典信息
查询SYSCONTEXTINDEXES系统表可以查询所有的全文索引信息:

select name, id, schid, type$, subtype$, pidfrom sysobjectswhere name like '%CNT_TEXT%';复制
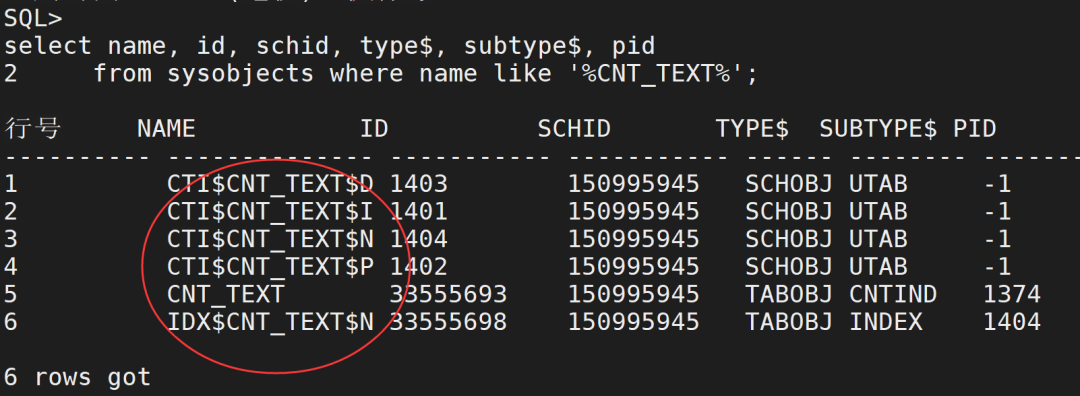
系统自动产生如下相关的辅助表(简称I表,P表,N表,D表):CTI$INDEX_NAME$I,CTI$INDEX_NAME$P, CTI$INDEX_NAME$N和CTI$INDEX_NAME$D。
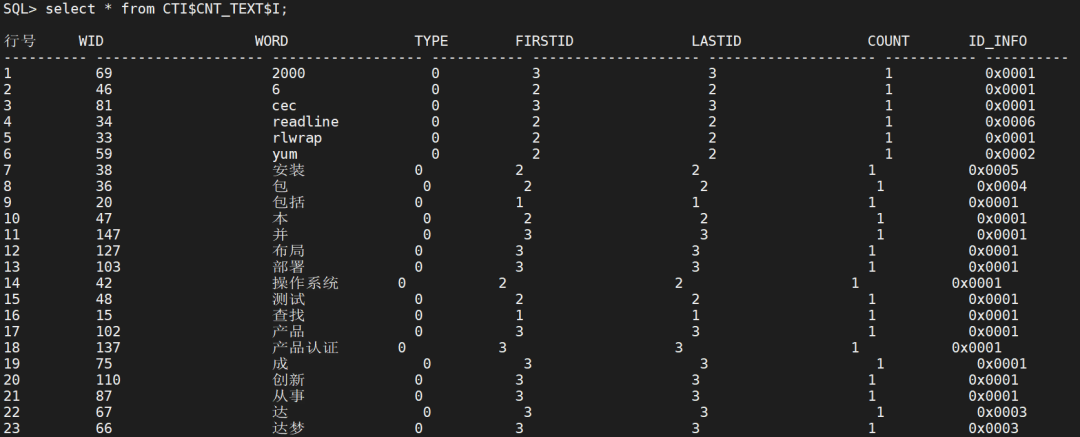
I表用于保存分词结果,记录词的基本信息,通过该信息就可以快速地定位到该词的基表记录;
P表用于保存基表发生的增量数据变化,用于修改全文索引时的增量填充。
N表用于保存原表记录rowid和新词条记录的docid的映射关系;
D表保存了所有将被删除的docid,被删除的docid即将不能通过全文索引查询到。
我们查询I表,可以看到里面保存了该表的分词信息:
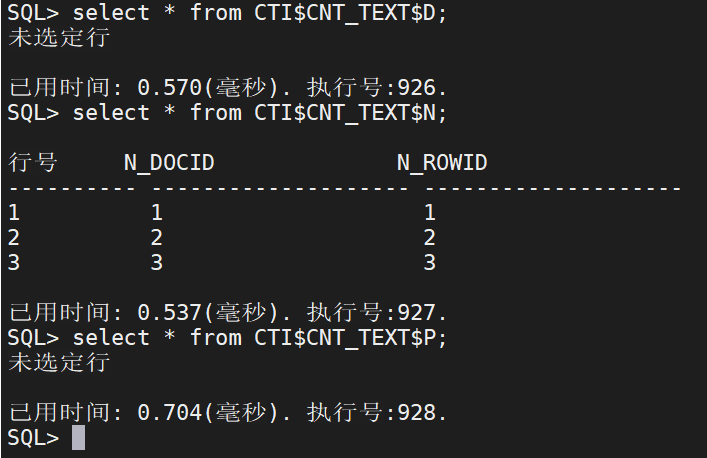
分别查询D表、N表、P表:
D表保存被删除的记录信息,所以D表没数据,
N表有记录,保存ROWID和DOCID的映射关系。
P表无记录,保存增量数据。
5、使用全文索引查询
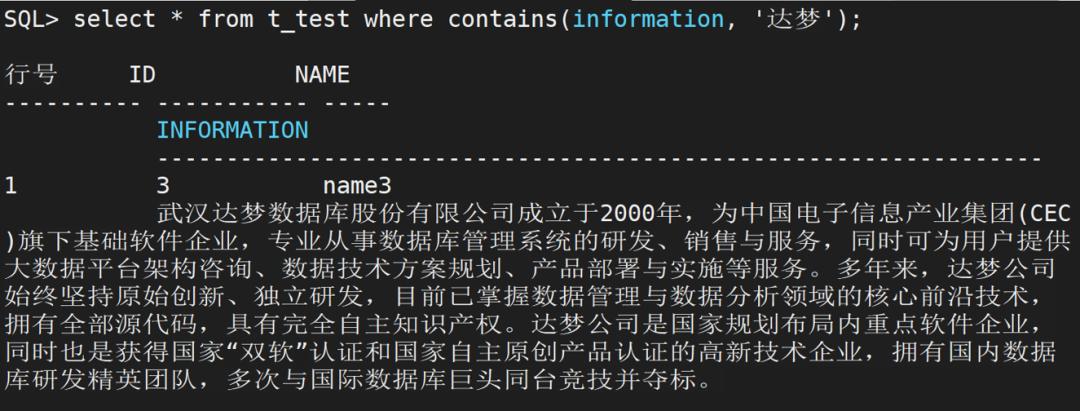
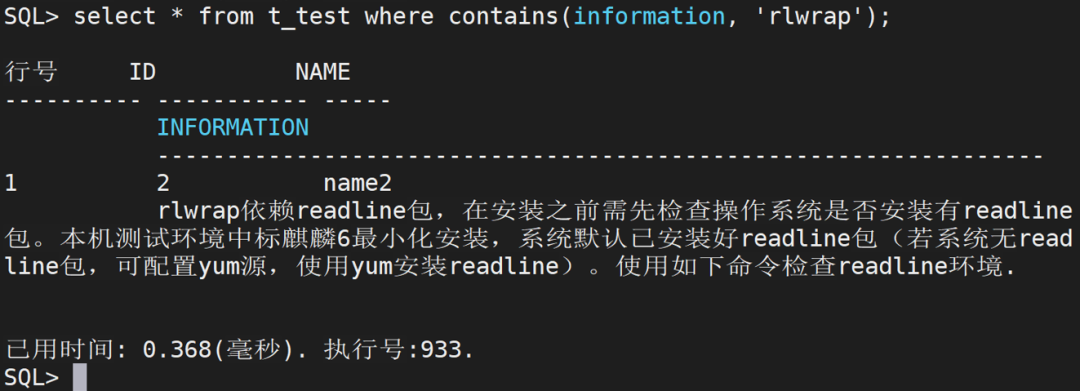
使用“达梦”和“rlwrap”关键字查询数据,可以分别查询到该记录:
select * from t_testwhere contains(information, '达梦');复制
select * from t_testwhere contains(information, 'rlwrap');复制
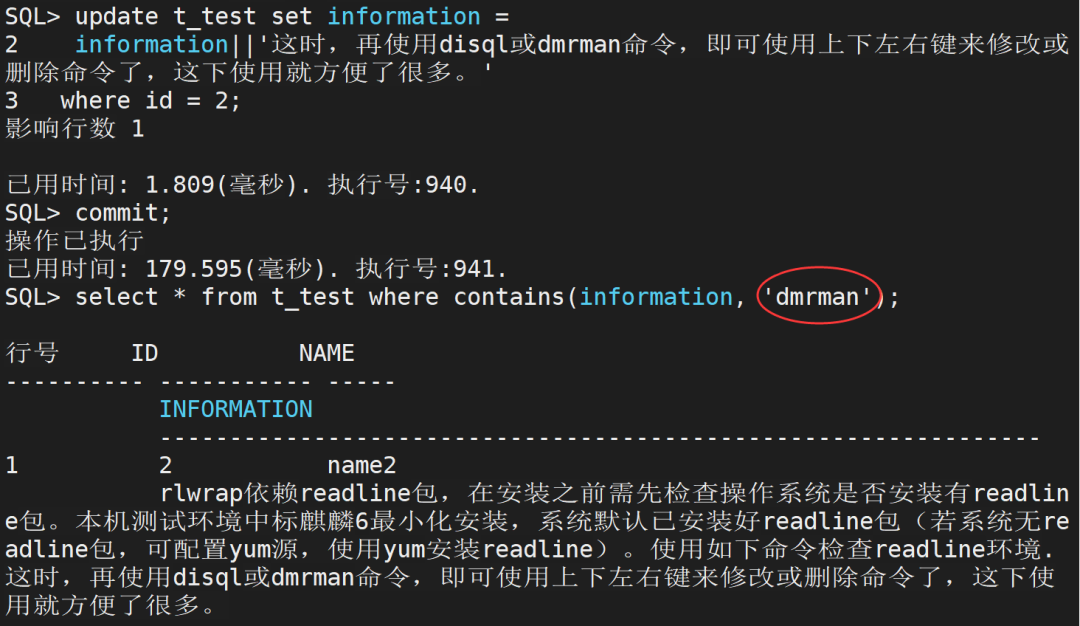
更新第二条记录,将INFORMATION字段增加一段文本,SQL参考如下:
update t_test02set information = information||'这时,再使用disql或dmrman命令,即可使用上下左右键来修改或删除命令了,这下使用就方便了很多。'where id = 2;复制
此时再来查询T_TEST表中记录,使用dmrman来查询:
select * from t_test where contains(information, 'dmrman');复制
可以看到已经查询到该记录。
查询CTI$CNT_TEXT$I、CTI$CNT_TEXT$P、CTI$CNT_TEXT$N、CTI$CNT_TEXT$D表可以看到里面的数据已刷新。
I表的分词数据更新,P表已有数据,D表无删除记录故无数据。
更新全文索引
上面例子在创建全文索引时指定了SYNC TRANSACTION子句,所以我们在插入和更新数据时全文索引信息会自动更新,但如果我们在创建全文索引时没有指定sync子句,也可以使用alter context index语法来更新全文索引信息。
比如我们使用如下语句新建一个T_TEST02表(表结构同T_TEST表,拥有T_TEST相同数据),并创建全文索引CNT_TEST02,不指定SYNC关键字:
create table t_test02 as select * from t_test;create context index cnt_test02 on t_test02(information);复制
此时,使用“达梦”或者“dmrman”作为查询条件,无法查询到数据:
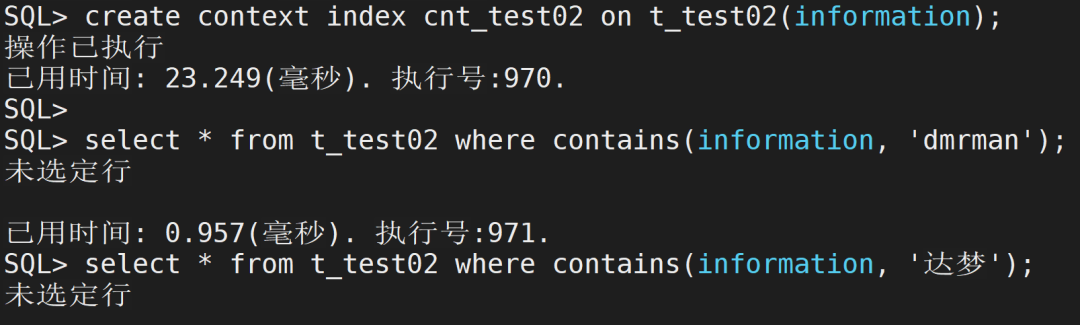
此时,查询I表可以看到分词表无数据。

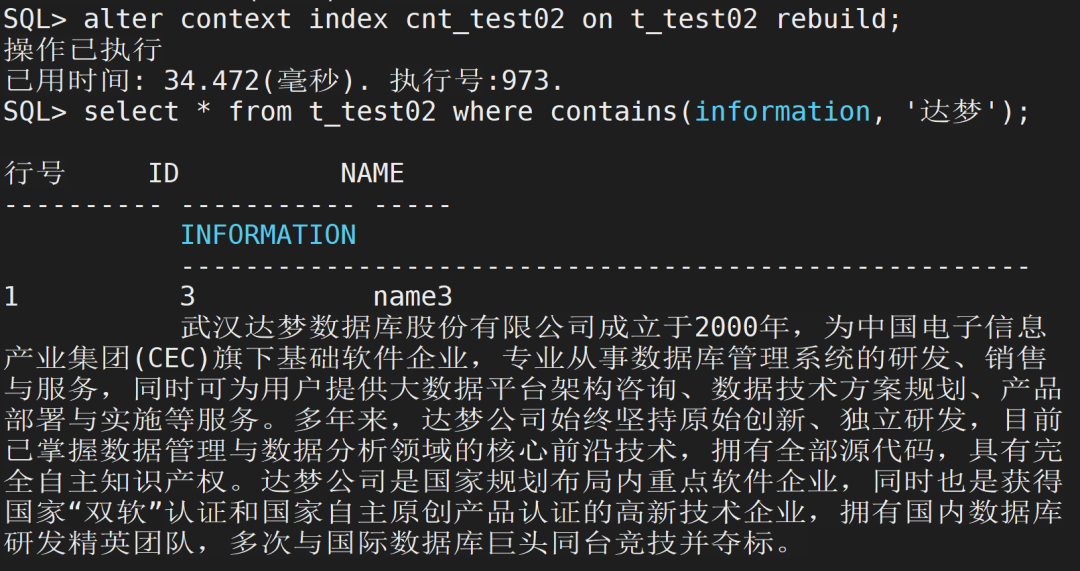
可以看出,全文索引信息未填充分词等信息,使用rebuild更新表中的所有全文索引信息,参考如下语句:
alter context index cnt_test02 on t_test02 rebuild;复制
此时查询I表可以看到分词表已有数据,使用“达梦”或者“dmrman”查询,即可查询到数据:
如果T_TEST02表新增了数据,也可以使用increment关键字更新增量的全文索引信息。参考如下:
alter context index cnt_test02 on t_test02 increment;复制
删除全文索引
如果不再使用某个全文索引,可以删除该全文索引;删除全文索引时,数据字典中相应的索引信息和全文索引内容都会被删除。
drop context index cnt_test02 on t_test02;复制
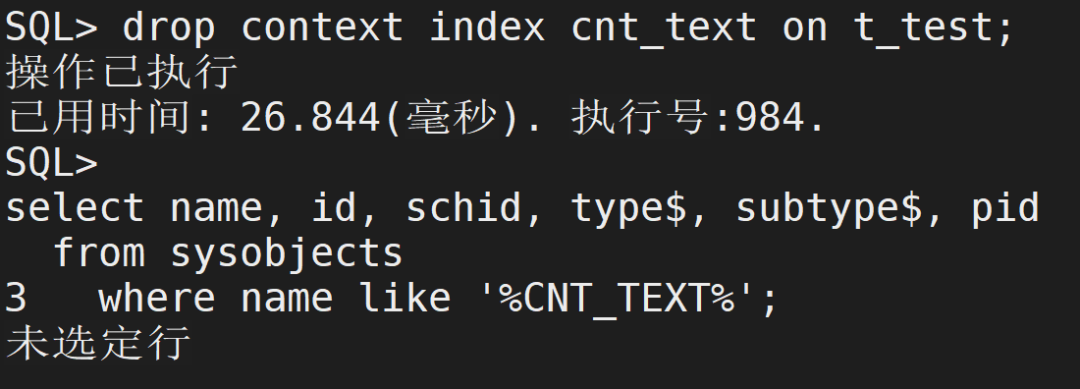
除了使用drop context index语句可删除全文索引外,当删除表或删除建立全文索引的列时,系统将自动删除全文索引。
好,以上是本次分享内容,希望能给大家带来帮助,感谢大家。
往期回顾
评论

 0
0 点赞
点赞