




数据库的SQL计算引擎负责处理和执行SQL请求。通常来说,查询优化器会输出物理执行计划,它通常由一系列Operator组成,为了确保执行效率的高效,需要将Operator组成流水线执行。
有两种流水线的构建方式:第一种是需求驱动的流水线,其中一个Operator不断从下级Operator重复拉取下一个数据Tuple;第二种是数据驱动的流水线,由Operator将每个数据Tuple推送给下一个Operator。那么,这两种流水线构建,哪种更好呢? 这可能并不是一个容易回答的问题,在Snowflake的论文中提到:基于Push的执行提高了缓存效率,因为它将控制流逻辑从数据循环中移除。它还使 Snowflake 能够有效地处理流水线的DAG 计划,为中间结果的共享和管道化创造了额外的机会。
下边这幅来自参考文献[1]的图最直接地说明Push和Pull的区别:
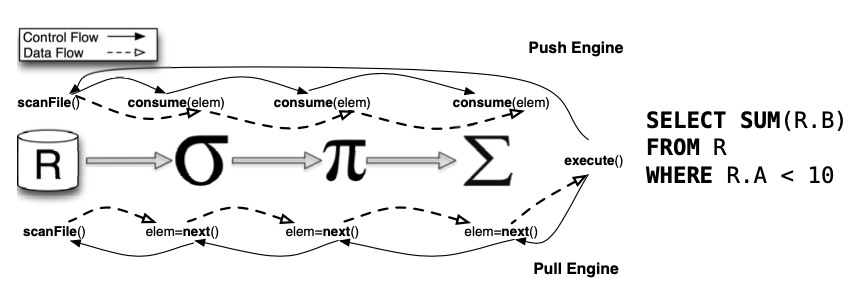
简单地说,Pull流水线基于迭代器模型,经典的火山模型正是基于Pull来构建。火山模型是数据库成熟的 SQL执行方案,该设计模式将关系型代数中的每一种操作抽象成一个Operator,整个 SQL 语句在这种情况下形成一个 Operator树(执行计划树);通过自顶向下的调用 next 接口,火山模型能够以数据库行为单位处理数据,就是图中所示的next()方法。这种请求是递归调用的,直到查询计划树的叶子结点可以访问数据本身。因此,对于Pull模型来说,这是非常容易理解和实现的:每个Operator都需要实现next()方法,只要将查询计划树构建好,就递归调用即可。火山模型有如下特点:
- 以数据行为单位处理数据,每一行数据的处理都会调用 next 接口。
- next 接口的调用,需要通过虚函数机制,相比于直接调用函数,虚函数需要的CPU 指令更多,因此更昂贵。
- 以行为单位的数据处理,会导致 CPU 缓存使用效率低下和一些不必要的复杂性:数据库必须记住处理到哪一行,以便处理跳到下一行;其次处理完一行后需要将下一行加载到 CPU 缓存中,而实际上 CPU 缓存所能存储的数据行数远不止一行。
- 火山模型最大的好处是接口看起来干净而且易懂。由于数据流和控制流在一起,每个Operator有良好的抽象,比如Filter只需要关心如何根据谓词过滤数据,Aggregates只需要关心如何聚合数据。
为了降低开销,Pull模型可以引入向量化加速,就是实现GetChunk()方法每次获取一批数据取代next()获取一行数据,以Projection算子为例说明:
void Projection::GetChunk(DataChunk &result) {
// get the next chunk from the child
child->GetChunk(child_chunk);
if (child_chunk.size() == 0) {
return;
}
// execute expressions
executor.Execute(child_chunk, result);
}
这里边,存在一些跟控制流有关的代码,它跟Operator的处理逻辑耦合在一起,且每个Operator实现都要包含这些代码,例如这里需要判断child_chunk为空的情况,因为child在GetChunk时进行了过滤处理。因此,Pull模型的接口内部实现比较冗余和易错。
与Pull流水线的迭代器模型不同,在Push模型中,数据流和控制流是相反的,具体来说,不是目的Operator向源Operator请求数据,而是从源Operator向目的Operator推送数据,这是通过源Operator将数据作为参数传递给目的Operator的消费方法(Consume)实现的,因此,Push流水线模型等价于访问者(Visitor)模型,每个Operator不再提供next,而换之以Produce/Consume。Push模型是Hyper提出的[3],称之为Pipeline Operator,它提出的初衷,是认为迭代器模型以Operator为中心,Operator的边界过于清晰,因此导致数据在Operator之间传递(从CPU寄存器转移到内存)产生额外的内存带宽开销,无法做到Data Locality最大化,所以执行需要从以Operator为中心切换到以数据为中心,尽量让数据在寄存器中保存更长时间,确保Data Locality最大化。进一步的,Hyper将操作系统的NUMA调度框架引入了数据库的查询执行调度[2],为Push模型实现了parallelism-aware(就是对并行更友好):
- 采用Pipeline来组合算子,自底而上Push调度。当一个任务执行结束时,它会通知调度器将后序任务加入到任务队列中,每个数据块的单位被称为 Morsel。一个Morsel 大约包含10000行数据。查询任务的执行单位是处理一个 Morsel。
- 优先将一个内核上的任务产生的后序任务调度在同一个内核上,避免了在内核间进行数据通信的开销。
- 当一个内核空闲时,它有能力从其他内核“偷取”一个任务来执行(Work Stealing),这虽然有时会增加一个数据传输的开销,但是却缓解了忙碌内核上任务的堆积,总体来说会加快任务的执行。
- 在内核空闲并可以偷取任务时,调度器并非立即满足空闲内核的要求,而是让它稍稍等待一段时间。在这段时间里,如果忙碌内核可以完成自己的任务,那么跨内核调度就可以被避免。
以多表Join为例:
SELECT ...
FROM S
JOIN R USING A
JOIN T USING B;
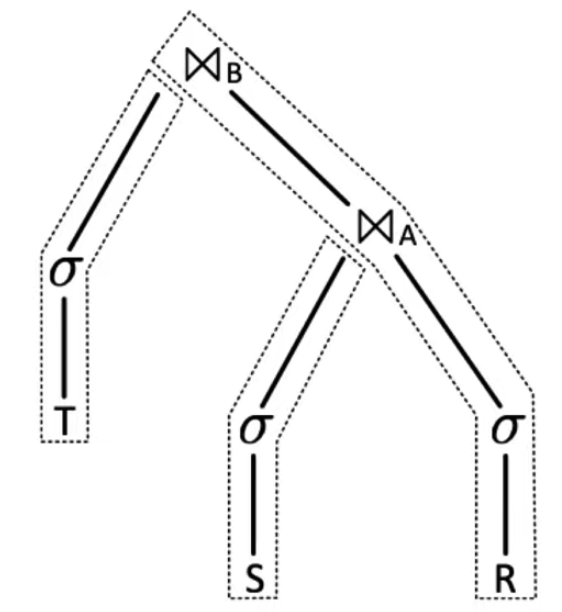

该查询由多个Pipeline组合而成,Pipeline之间需要并行,Pipeline内部也要并行。实际中并行的控制只需要在Pipeline的端点即可,例如上图中,中间的过滤等算子,本身无需考虑并行,因为源头的TableScan扫描会Push数据给它,而Pipeline的Sink是Hash Join,它的Hashtable Build阶段需要parallelism-aware,但Probe阶段无需这样。以Push为基础控制Pipeline的parallelism-aware,从技术上更加容易做到。
Push模型实现parallelism-aware相对容易,那么为什么Pull模型实现parallelism-aware就不太容易呢?由于是自顶而下来调度而非数据驱动,因此一个直接的想法是划定分区,然后由优化器根据分区制定物理计划,不同分区的物理计划并行执行。这样容易导致一个问题就是让查询计划更加复杂(引入更多分区),而且并不容易做到负载的自动均衡,具体来说:对输入数据进行分区时,经过一些Operator(如Filter)后,不同分区保留下来的数据量区别很大,因此后续的算子执行就会面临数据倾斜问题。此外,不同的CPU处理同样数据量所花费的时间也并不一定相同,它会受到环境干扰、任务调度、阻塞、错误等原因减慢甚至中止相应,因此也会拖慢整体执行的效率。
Hyper的Push模型是在2011年提出的,在这之前的SQL引擎,大都采用基于火山的Pull模型。已知基于Push构建的有Presto,Snowflake,Hyper,QuickStep,HANA,DuckDB(在2021年10月从Pull模型切换到了Push模型(详见参考文献[4]),Starrocks等。ClickHouse是个异类,在它自己的Meetup材料中,宣称自己是Pull和Push的组合,其中查询是采用了Pull模型。并且,在它的代码中,也一样是采用Pull字眼,作为查询调度核心驱动——PullingAsyncPipelineExecutor。在通过AST生成QueryPlan(逻辑计划)后,经过一些RBO优化,ClickHouse将QueryPlan按照后序遍历的方式将其转化为Pipeline,这种方式生成的Pipeline,跟Push模型是很像的,因为Pipeline的每个Operator(ClickHouse定义叫Processor),都有输入和输出,Operator从输入将数据Pull过来,完成处理后,再Push给Pipeline的下一级Operator。因此,ClickHouse并不是传统的火山Pull模型实现,而是从查询计划树生成Pipeline执行计划。从火山Pull模型的Plan Tree生成Pipeline的方法是后序遍历,从没有Children 的Node开始构建第一个Pipeline,这是Push模型中生成Pipeline Operator的标准做法:
QueryPipelinePtr QueryPlan::buildQueryPipeline(...)
{
struct Frame
{
Node * node = {};
QueryPipelines pipelines = {};
};
QueryPipelinePtr last_pipeline;
std::stack<Frame> stack;
stack.push(Frame{.node = root});
while (!stack.empty())
{
auto & frame = stack.top();
if (last_pipeline)
{
frame.pipelines.emplace_back(std::move(last_pipeline));
last_pipeline = nullptr;
}
size_t next_child = frame.pipelines.size();
if (next_child == frame.node->children.size())
{
last_pipeline = frame.node->step->updatePipeline(std::move(frame.pipelines), build_pipeline_settings);
stack.pop();
}
else
stack.push(Frame{.node = frame.node->children[next_child]});
}
return last_pipeline;
}
接下来是Pipeline调度,首先PullingAsyncPipelineExecutor::pull从Pipeline中拉取数据:
PullingAsyncPipelineExecutor executor(pipeline);
Block block;
while (executor.pull(block, ...))
{
if (isQueryCancelled())
{
executor.cancel();
break;
}
if (block)
{
if (!state.io.null_format)
sendData(block);
}
sendData({});
}
pull调用的时候从thread_group选择线程,然后data.executor->execute(num_threads)执行PipelineExecutor,num_threads表示并行线程数。接下来PipelineExecutor将Pipeline转化为执行图ExecutingGraph。Pipeline是逻辑结构,并不关心如何执行,ExecutingGraph则是物理调度执行的参照。ExecutingGraph通过Pipeline Operator的InputPort和OutputPort转换为Edge,用Edge把2个Operator连接起来,Operator就是图的Node。随后就是PipelineExecutor::execute通过ExecutingGraph对Pipeline调度,这个函数主要作用是通过task_queue中pop出执行计划的ExecutingGraph::Node来调度任务。调度时,线程会不停遍历ExecutingGraph,根据Operator的执行状态进行调度执行,直到所有的Operator都到达Finished状态。调度器初始化,是挑选ExecutingGraph中所有没有OutPort的Node启动的,因此,控制流是从Pipeline的Sink Node发出的,递归调用prepareProcessor,这区别于Push模型的控制流从Source Node开始逐级向上。除了控制流向的不同,这个Pipeline Operator跟Push完全一样,因此也有人将ClickHouse归入Push模型中,毕竟,在很多文献的上下文,Push等同于Pipeline Operator,Pull等同于火山。Pipeline和ExecutingGraph的对应如图所示(在ClickHouse中,Operator=Processor=Transformer):
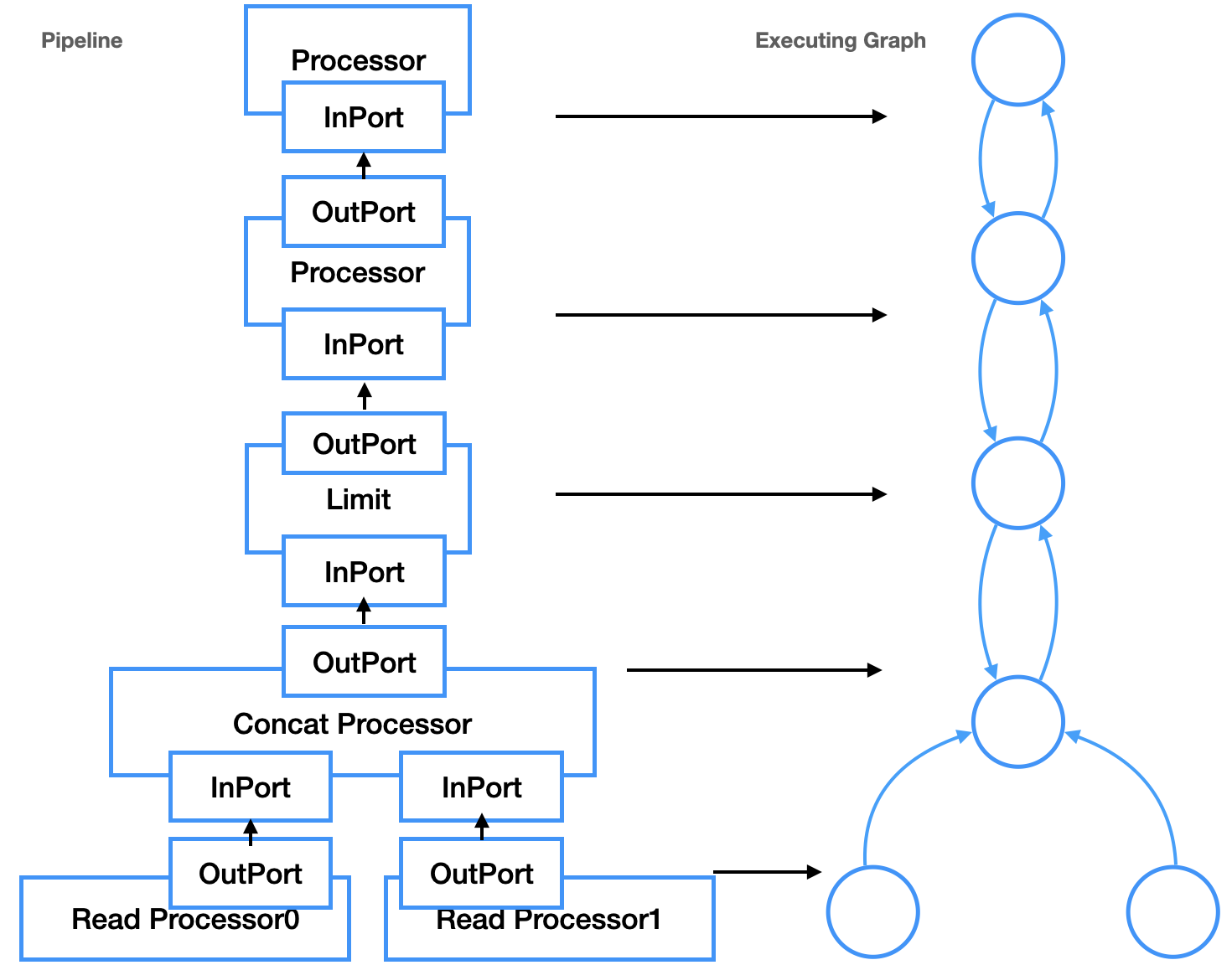

因此,Push模型是parallelism-aware的,本质上需要设计工作良好的调度器,来控制数据流和并行度。除了上述的优点,朴素的Push模型也存在一些缺点:处理Limit和Merge Join有一些困难(详见参考文献[1]),对于前者来说,Operator不容易控制数据何时不再由源Operator产生,这样就会产生一些永远不会被使用的元素。对于后者来说,由于Merge Join Operator无法当前由哪个源Operator产生下一个数据Tuple,所以Merge Join无法进行流水线处理,因此至少对其中一个源Operator要打破流水线(Pipeline Breaker),需要对其进行物化操作。这两个问题,其本质依然是Push模型下的Pipeline调度问题:消费者如何控制生产者,除了Limit和Merge Join之外,其他的操作,例如终止正在进行的查询,也是一样的情况。正如通过分离查询计划树和Pipeline使得Pull模型可以parallelism-aware之外,Push模型在工程实现上也并没有必要完全如同论文所描述,只能控制Pipeline的源头。通过引入ClickHouse task_queue类似的机制,Push模型同样可以做到对源Operator的逐级控制。
MatrixOne基于Golang开发,因此直接利用Go语言特性实现了Push模型:利用channel作为阻塞消息队列,通知生产者。查询计划由多个Operator构成,pipeline是包含多个Operator的执行序列。Operator代表一个具体的操作,比如典型的过滤,投影,hash build和hash probe都可以。对于一个查询计划来说,首先需要确定使用多少个pipeline,使用多少个cpu,每个cpu跑哪些pipeline。具体实现中,借助于Golang语言的特性:一个pipeline对应一个goroutine,pipeline之间通过channel(无Buffer)传递数据,pipeline的调度也是通过channel来驱动。举例如下:
Connector Operator
func Call(proc *process.Process, arg interface{}) (bool, error) {
...
if inputBatch == nil {
select {
case <-reg.Ctx.Done():
process.FreeRegisters(proc)
return true, nil
case reg.Ch <- inputBatch:
return false, nil
}
}
}
由于是Push模型,因此一个查询计划是通过Producer Pipeline触发整个流程的,非生产者的Pipeline,没有接收到数据,是不会运行。Producer Pipeline在启动后,就会尝试读取数据,然后通过channel将数据发送给另一个Pipeline,Producer Pipeline在启动后就会不停的读取数据,只存在两种情况会退出:
- 数据读取完
- 发生错误
当非生产者的pipeline没有从channel读取Producer Pipeline推送的数据时,Producer Pipeline会阻塞。非生产者的Pipeline在启动后并不会立刻执行,除非Producer Pipeline在channel中放置了数据。Pipeline在启动后会在以下两种情况退出:
- 从channel中接受到了退出信息
- 发生错误
MatrixOne会根据数据的分布将Producer Pipeline分配到具体的节点。在特定的节点接收到Producer Pipeline后会根据当前机器和查询计划的情况(目前是获取机器的核数)来派生多个Producer pipeline。其余Pipeline的并行度,则是在接受数据的时候确定其并行度。
下边先看一个简单查询:
select * from R where a > 1 limit 10
这个查询存在Limit Operator,意味着存在上文所述的Cancel,Limit,Merge Join等Pipeline的终止条件。该查询的Pipeline如下所示,它在2个Core上并行执行。
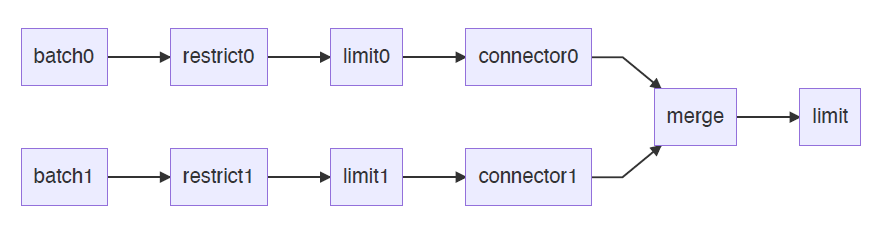
由于Limit的存在,Pipeline引入了Merge Operator,与此同时跟调度相关的问题是:
- Merge不能无限制地接受多个Pipeline的数据,Merge需要根据内存大小通过Connector向上游发送channel停止数据读取。
- Pipeline数目根据CPU数量动态决定,当Pipeline不再推送数据时,查询自然终止,因此Merge需要标志是否已经传输结束。
再看一个复杂一些的例子,tpch-q3:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'HOUSEHOLD'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-29'
and l_shipdate > date '1995-03-29'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit 10
假设查询计划如下:
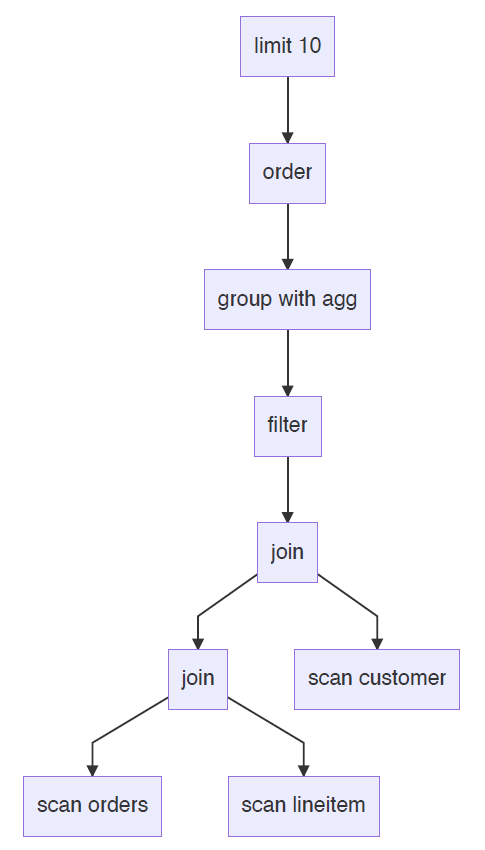
假设三张表的数据均匀分布在两个节点node0和node1上,那么对应的Pipeline如下:
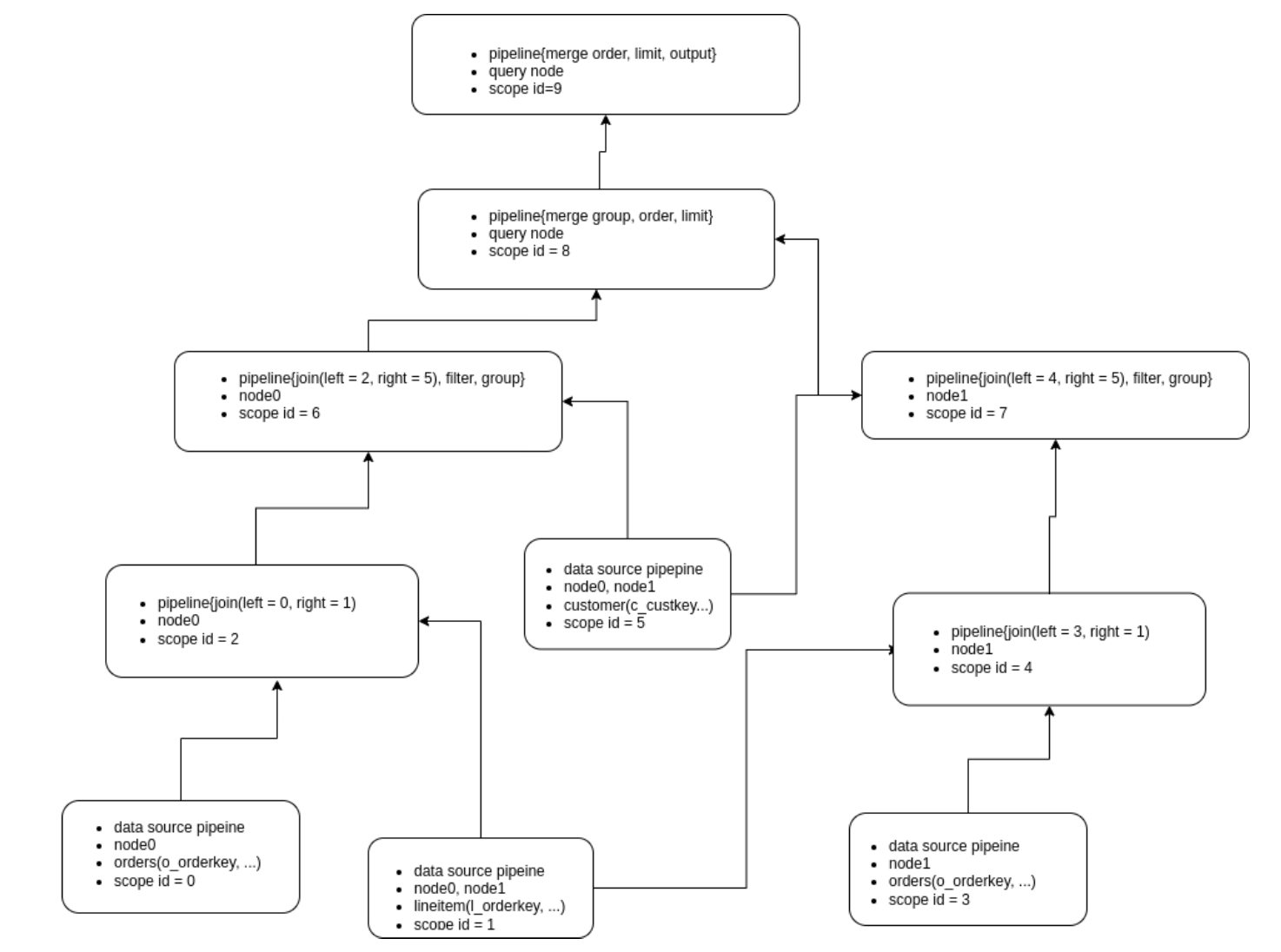

采用Push模型的还有一个潜在优点在于,它跟流计算的Data Flow范式(如Flink)容易保持一致。FlinkSQL会把查询计划的每个Operator转为流式Operator,流式Operator会将每个Operator的计算结果的更新传给下一个Operator,这从逻辑上跟Push模型是一致的。对于打算在数据库内部实现流引擎的MatrixOne来说,这是一个逻辑复用的地方,当然,流引擎远不是只依靠Push模型就可以解决的,这超出了本文讨论的范畴。采用Push模型最后一个潜在优点是,它和查询编译Codegen是天然组合,目前MatrixOne并没有实现Codegen,故而这也超出了本文讨论的范畴。
当前的MatrixOne,实现了基本的基于Push模型的计算并行调度,在未来,还会在多方面上进行改进,比如针对多查询的混合并发与并行的任务调度,比如当算子因为内存不足需要进行Spill处理时,也需要Pipeline的调度能够感知并有效处理,既能完成任务,还能最小化IO开销,这里边会有很多非常有意思的工作。也欢迎对这方面感兴趣的同学跟我们一起探讨这些层面上的创新。所以,Push还是Pull,这是个问题么?好像是,好像也不是,一切以实际效果为着眼点,并非简单地非黑既白,这代表了一种计算并行调度的思维方式。
参考文献
[1] Shaikhha, Amir and Dashti, Mohammad and Koch, Christoph, Push versus pull-based loop fusion in query engines, Journal of Functional Programming, Cambridge University Press, 2018
[2] Leis, Viktor and Boncz, Peter and Kemper, Alfons and Neumann, Thomas, Morsel-driven parallelism: A NUMA-aware query evaluation framework for the many-core age, SIGMOD 2014
[3] Thomas Neumann, Efficiently compiling efficient query plans for modern hardware, VLDB 2011
[4] https://github.com/duckdb/duckdb/pull/2393
[5] https://presentations.clickhouse.com/meetup24/5.%20Clickhouse%20query%20execution%20pipeline%20changes/#1
MatrixOne 社区
欢迎加入 MatrixOne 社群参与讨论
官网:matrixorigin.cn
源码:github.com/matrixorigin/matrixone
Slack:matrixoneworkspace.slack.com
知乎 | CSDN | 墨天轮 | InfoQ | SegmentFault:MatrixOrigin

