




导语
本文分析基于11.2.0.4版本,通过整个问题的分析和解决过程,希望能够大家对大结果集下标量子查询的存在的性能问题以及为如何、为什么改写有所帮助,而不是说标量子查询一定不好,有时候可能需要改写为标量子查询,小结果集标量子查询FILTER执行计划优先NL(外层表存在重复多的情况).
背景
群中小伙伴遇到生产环境SQL执行1小时都没有出来,是一个insert select,如下是查询语句部分,从语句写法来看应该是N:N关系,这个是标量子查询语句.类似NL,不能使用HASH JOIN(FILTER具有去重功能),外层表结果集越大,内层表被循环次数越多。适合外层表满足条件结果集少且内层表走高效执行计划的场景,这个例子外层表是50万,内层表是6万。结果集就是小于等于50万.最多循环50万次,如果循环1次是10msm,那么执行时间5000s(符合生产环境超过1小时无法执行出来),如果是1ms,那么执行时间是500s.如果0.5ms,50s.在循环传值情况下,单次执行时间*总次数=理论时间.所以外层表特别大的情况,此时改写来成外连接来提升效率,否则生产环境会遇到性能问题。
具体SQL
SELECT DISTINCT TO_CHAR(APPLY.ADD_TIME, 'yyyymmdd') CAL_NUMBER,APPLY.APPLY_ID,(SELECT XUB.EXPIRE_TIMEFROM (SELECT *FROM TMP_DM_RPT_MICCN_COM_UPG0 CORDER BY C.ADD_TIME DESC) XUBWHERE XUB.COM_ID = APPLY.COM_IDAND XUB.ADD_TIME <= APPLY.ADD_TIMEAND ROWNUM < 2) AS LAST_EXPIRE_TIME,DECODE(APPLY.APPLY_TYPE, 0, '组织', 1, '个体')APPLY_TYPE,APPLY.COM_ID,APPLY.ORDER_TIME,APPLY.UPDATE_TIME,APPLY.LAST_CHECK_TIMEFROM ODS_MEMBER_UPGRADE_APPLY_CN APPLY;
【原执行计划】
备注:本地模拟数据构造相同的执行计划,差别在于数据量而已(不影响执行计划)
ODS_MEMBER_UPGRADE_APPLY_CN:5万,TMP_DM_RPT_MICCN_COM_UPG0:6万与生产在一个数理级别.不过从执行计划来单次是2ms+300buffer gets成本.
存在问题:
1、内层表没有索引,全表扫描加上排序
2、被驱动次数为50万次数
如果尝试创建一个索引,验证下效果?
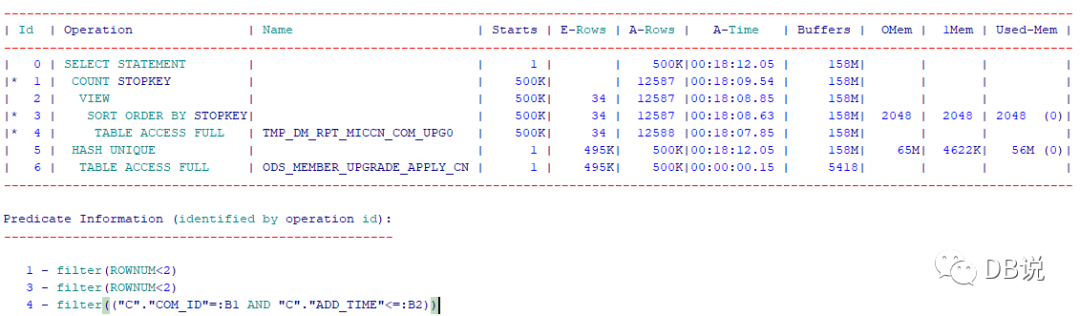
--------------------------------------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |--------------------------------------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 500K|00:18:12.05 | 158M| | | ||* 1 | COUNT STOPKEY | | 500K| | 12587 |00:18:09.54 | 158M| | | || 2 | VIEW | | 500K| 34 | 12587 |00:18:08.85 | 158M| | | ||* 3 | SORT ORDER BY STOPKEY| | 500K| 34 | 12587 |00:18:08.63 | 158M| 2048 | 2048 | 2048 (0)||* 4 | TABLE ACCESS FULL | TMP_DM_RPT_MICCN_COM_UPG0 | 500K| 34 | 12588 |00:18:07.85 | 158M| | | || 5 | HASH UNIQUE | | 1 | 495K| 500K|00:18:12.05 | 158M| 65M| 4622K| 56M (0)|| 6 | TABLE ACCESS FULL | ODS_MEMBER_UPGRADE_APPLY_CN | 1 | 495K| 500K|00:00:00.15 | 5418| | | |--------------------------------------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter(ROWNUM<2)3 - filter(ROWNUM<2)4 - filter(("C"."COM_ID"=:B1 AND "C"."ADD_TIME"<=:B2))
【新执行计划】
1、创建索引,在被驱动表上创建索引即可,驱动表无需创建索引
create index idx01_DM_RPT_MICCN_COM_UPG0 onTMP_DM_RPT_MICCN_COM_UPG0(COM_ID,ADD_TIME)
2、执行计划性能
1、创建索引后,被驱动表走索引降序扫描方式,无需进行排序
2、buffer gets从158M下降到528K,执行时间从18分钟下降2分钟.单次执行效率:0.2ms+1个buffer gets(相比之前单次执行是2ms+300buffer gets.)
疑问:如果数理级别提升,从50万变成5000万,理想执行时间为120s*100=12000/3600=3.3H(实际情况随着表大小变化以及系统负载情况等情况,执行时间应该更长)

------------------------------------------------------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |------------------------------------------------------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 500K|00:00:02.06 | 528K| 84 | | | ||* 1 | COUNT STOPKEY | | 500K| | 12587 |00:00:01.04 | 522K| 84 | | | || 2 | VIEW | | 500K| 34 | 12587 |00:00:00.79 | 522K| 84 | | | || 3 | TABLE ACCESS BY INDEX ROWID | TMP_DM_RPT_MICCN_COM_UPG0 | 500K| 34 | 12587 |00:00:00.63 | 522K| 84 | | | ||* 4 | INDEX RANGE SCAN DESCENDING| IDX01_DM_RPT_MICCN_COM_UPG0 | 500K| 2 | 12587 |00:00:00.46 | 510K| 84 | | | || 5 | HASH UNIQUE | | 1 | 495K| 500K|00:00:02.06 | 528K| 84 | 65M| 4622K| 56M (0)|| 6 | TABLE ACCESS FULL | ODS_MEMBER_UPGRADE_APPLY_CN | 1 | 495K| 500K|00:00:00.09 | 5418| 0 | | | |------------------------------------------------------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------1 - filter(ROWNUM<2)4 - access("C"."COM_ID"=:B1 AND "C"."ADD_TIME"<=:B2)
3、问题
数量级上升后,索引作用也弱化很多,因为filter类似嵌套循环,大表应该改成hash join,如何等价改成?需要了解标量子查询特征:
1、外层表传值到内层表,找到结果,则为NULL
2、如果匹配到则返回最多有且只有1行1列值,返回多行则会报错。
基于以上特征:必须改写成外连接且需要去重
【改写后SQL&执行计划】
1、left join
select distinct CAL_NUMBER,APPLY_ID,EXPIRE_TIME,XADD_TIME,APPLY_TYPE,COM_ID,ORDER_TIME,UPDATE_TIME,LAST_CHECK_TIMEfrom (select TO_CHAR(APPLY.ADD_TIME, 'yyyymmdd')CAL_NUMBER,APPLY.APPLY_ID,XUB.EXPIRE_TIME,XUB.ADD_TIME XADD_TIME,DECODE(APPLY.APPLY_TYPE, 0, '组织', 1, '个体') APPLY_TYPE,APPLY.COM_ID,APPLY.ORDER_TIME,APPLY.UPDATE_TIME,APPLY.LAST_CHECK_TIME,row_number() over(partition by APPLY.COM_ID,XUB.COM_ID order by XUB.ADD_TIME desc) RNFROM YTRPT.ODS_MEMBER_UPGRADE_APPLY_CN APPLYLEFT JOIN YTRPT.TMP_DM_RPT_MICCN_COM_UPG0 XUBON APPLY.COM_ID = XUB.COM_IDand XUB.ADD_TIME <= APPLY.ADD_TIME)where rn = 1
2、执行计划
1、执行时间从128s下降到2s(这个里面没有算网络返回时间),buffer gets从528K下降到5700.效率提升N倍。
2、效率是提升N倍,但是否等价这个如何验证?为了验证准备,我们沟通10条数据进行验证。
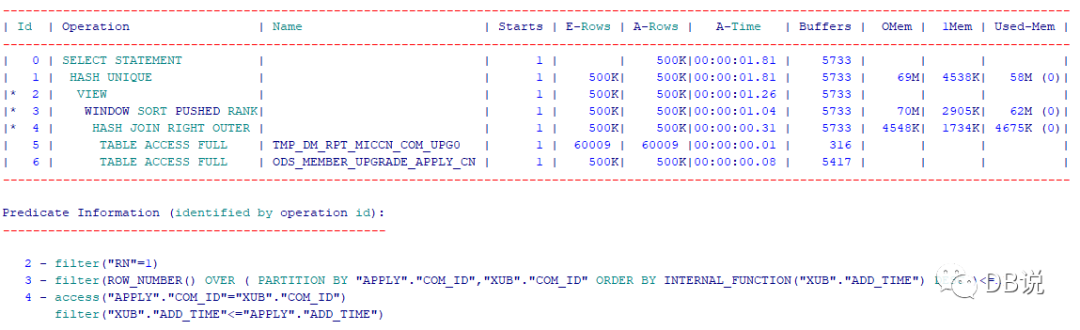
----------------------------------------------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |----------------------------------------------------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | | 500K|00:00:01.81 | 5733 | | | || 1 | HASH UNIQUE | | 1 | 500K| 500K|00:00:01.81 | 5733 | 69M| 4538K| 58M (0)||* 2 | VIEW | | 1 | 500K| 500K|00:00:01.26 | 5733 | | | ||* 3 | WINDOW SORT PUSHED RANK| | 1 | 500K| 500K|00:00:01.04 | 5733 | 70M| 2905K| 62M (0)||* 4 | HASH JOIN RIGHT OUTER | | 1 | 500K| 500K|00:00:00.31 | 5733 | 4548K| 1734K| 4675K (0)|| 5 | TABLE ACCESS FULL | TMP_DM_RPT_MICCN_COM_UPG0 | 1 | 60009 | 60009 |00:00:00.01 | 316 | | | || 6 | TABLE ACCESS FULL | ODS_MEMBER_UPGRADE_APPLY_CN | 1 | 500K| 500K|00:00:00.08 | 5417 | | | |----------------------------------------------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - filter("RN"=1)3 - filter(ROW_NUMBER() OVER ( PARTITION BY "APPLY"."COM_ID","XUB"."COM_ID" ORDER BY INTERNAL_FUNCTION("XUB"."ADD_TIME") DESC )<=1)4 - access("APPLY"."COM_ID"="XUB"."COM_ID")filter("XUB"."ADD_TIME"<="APPLY"."ADD_TIME")
等价验证
1、构造2个小表AA、BB(来自原表数据)
备注:2个表满足:N:1,1:1,1:N,N:N关系
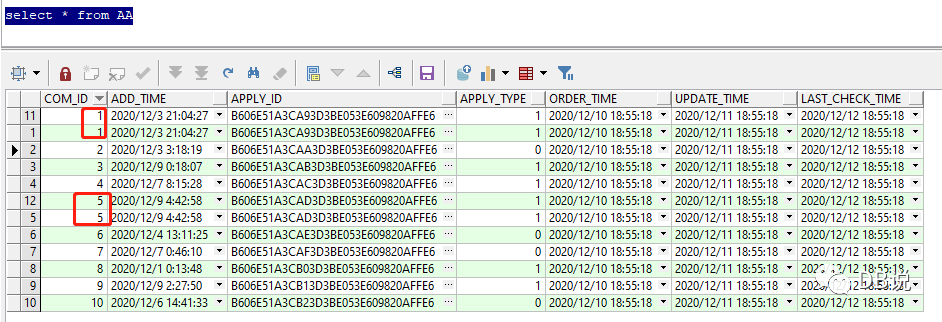

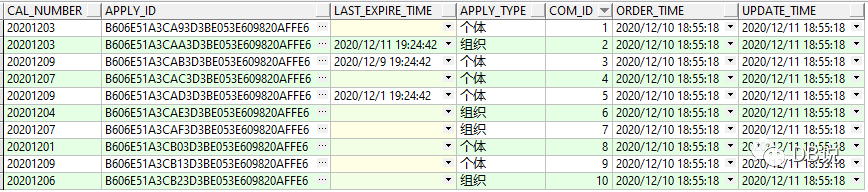
2、验证结果集--2者结果集相同,说明改写是正确的.
1、原始SQL结果集
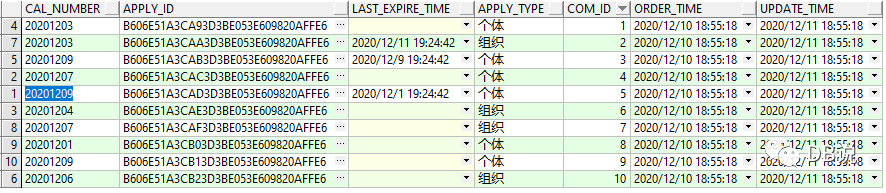
2、LEFT JOIN结果集
总结
通过了解标量子查询固有特征,在大结果集存在性能问题,索引在一定量结果集下能够改善性能,如呈现数据量增长后,单次执行时间*总执行次数得到时间是可能是一个恐怖的值,程序执行时间可能是小时或者天单位,那么程序的性能是不可结果,大结果集必须改成JOIN方式能够大大提升性能。
改写主要是等价的,需要关注表之间关系是1:1,还是1:N、N:N的,如是自己构造数据,需要考虑各种可能性,否则性能可能提升,但与原SQL不等价。
