





目录


背景介绍
1.1 何为“实用主义”
1.2 性能优化考量指标

几个非常好用的优化模式汇总
内存 | Redis (或类似缓存服务) | MySQL (或类似关系型数据库) | 内部接口 (同一集群) | |
读取速度 | 极快 相当于读取变量,基本不会成为瓶颈 | 快 | 比Redis慢 | 取决于接口性能和网络开销。大多数情况比MySQL慢 |
常见瓶颈 | 硬件资源 | 网络带宽,尤其是单个entry较大的情况 CPU(数据反序列化) | 网络带宽 MySQL 硬件资源 连接池数量 | 网络带宽 CPU (数据反序列化) 依赖接口的性能 |
2.1 最简单内存、Redis做缓存
内存无论是吞吐量还是对CPU、网络的负担都会更小
在使用多replica+内存的方案中,由于不同replica缓存过期时间不一致会有每次请求结果不一致的情况。
Redis更适合entry数量比较多的场景,内存更适合单个entry比较大的场景
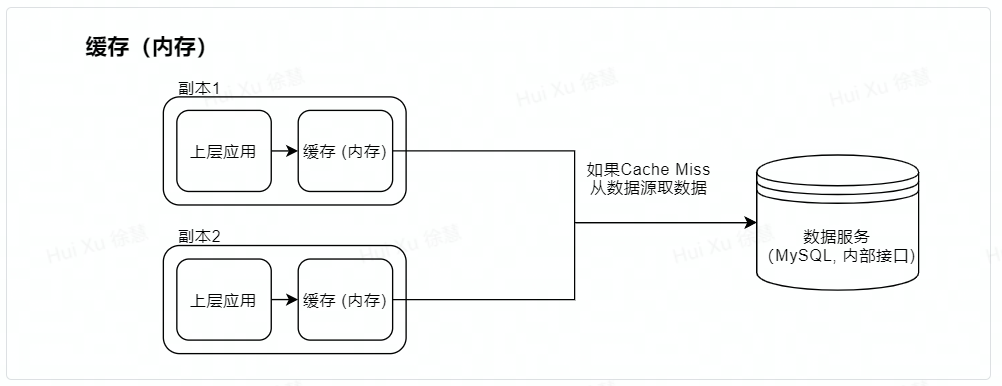
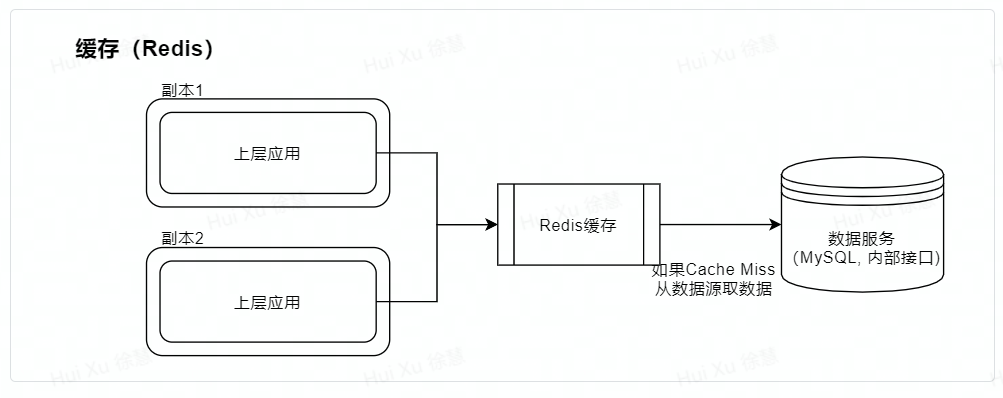
指标 | 评估(内存) | 评估(Redis) |
适用场景 | 对于数据的实时性要求不是很高的情况 | |
实时性 | 非实时,由于没有缓存的更新策略。 | |
由于不同副本缓存数据的时间不一致会有请求结果不确定的情况。 | 由于每次都访问redis,不会出现请求结果不确定的情况。 | |
可伸缩性 | 可伸缩 | 一定程度可伸缩,受制于Redis网络带宽 |
缓存命中率 | 和缓存的失效有关。通常情况下命中率高,只有在缓存失效的时候才会不命中。 | |
实现复杂度 | 很低 但一些工程师会写出容易“缓存雪崩”的代码 | |
可能存在的瓶颈 | 可能由于数据量 (条数)太大,造成缓存频繁进行淘汰,造成缓存命中率低的情况 | 使用Redis存储较大单条数据的缓存,在数据被频繁访问时可能会面临网络带宽不足的情况 |
2.2 内存+Redis混合缓存
此混合缓存方案为将内存和Redis的不同特性相结合,从而得到一个能同时发挥内存和Redis强项的缓存方案。核心思想,是将数据使用内存进行缓存,使用redis来校验数据的实时性。
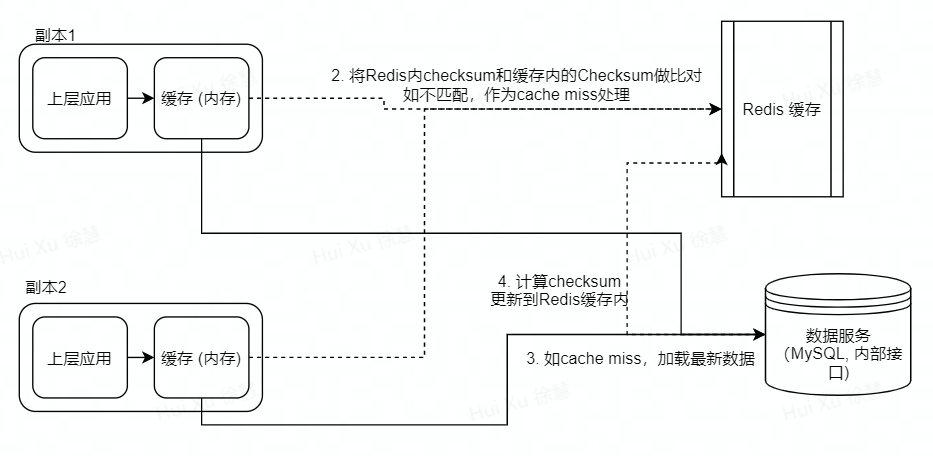
此方法有如下的优点:
不会出现前文提到的多replica+内存方案中“请求结果不一致”情况。
Redis只处理简单的checksum的存储和查询。避免了在处理单个entry较大的缓存时,可能出现网络瓶颈问题。
可做缓存的更新淘汰,只需要在数据更新时将Redis内的checksum删除。
指标 | 评估 |
适用场景 | 单个缓存entry数据较大 |
实时性 | 亚秒 |
可伸缩性 | 可伸缩 |
缓存命中率 | 和缓存的失效有关。通常情况下命中率高,只有在缓存失效的时候才会不命中。 |
实现复杂度 | 中等 ”数据更新时将Redis内的checksum删除“,如果实现的不合理可能会破坏系统层级结构 |
可能存在的瓶颈 | 数据写入频繁使得缓存过期频繁 每次访问数据时都需要计算Checksum,如果算法选用不好有可能造成CPU性能问题 |
2.3 内存+MQ混合缓存
此方法是一个基于内存作为主要介质的cache系统,MQ主要解决数据更新时候的实时性问题。和之前使用Redis Checksum解决实时性问题的方法相比,主要优点在于:
缓存(内存)的数据能保证是最新的
每次访问的时候,不需要进行访问网络
系统结构较为合理,能很好的解决“数据更新”和“缓存失效”可能存在的耦合,中间仅有消息队列通信,是典型的“高内聚低耦合”的设计理念。

指标 | 评估 |
适用场景 | 单个缓存entry数据较大 |
实时性 | 亚秒 |
可伸缩性 | 可伸缩 |
缓存命中率 | 和缓存的失效有关。通常情况下命中率高,只有在缓存失效的时候才会不命中。 |
实现复杂度 | 中等 “数据更新时将Redis内的checksum删除”,如果实现的不合理可能会破坏系统层级结构 |
可能存在的瓶颈 | 数据写入频繁使得缓存过期频繁 |

总结
对于不同系统的优化多种多样,除了从应用层切入之外,还可以从系统另外的层次切入,得到不同的优化方案,例如网络、数据库甚至机器硬件,每个方面都是一门大学问。伴随着业务的发展,需要优化的系统以及优化目标也会随时变化,但无论如何,系统优化的指导理论和设计思路都是万变不离其宗的,这些东西也是我们真正需要学习和掌握的核心能力。

