原文链接:https://dzone.com/articles/scalable-writes-to-postgres-with-spring
作者:Aditya Bansal
每个与客户产生共鸣的工程组织最终都会遇到扩展问题。扩展产品和组织对您的流程和基础架构提出了新的要求。在这篇文章中,我们将重点介绍我们公司如何应对众多基础设施扩展挑战之一:使用 Spring 和 Spring Data 对 (Postgres) 数据库的可扩展写入。
随着我们用户群的增长,我们开始遇到一些性能问题,主要是我们上游 Postgres 数据库的瓶颈。我们的 RPS 在短短几个月内就超过了 180(从 < 50),我们开始遇到 SQL 连接超时、连接断开和延迟显着增加等问题。这导致客户体验下降,这是不可接受的。
因此,我们着手研究如何解决这些 Postgres 瓶颈。我们很快意识到我们花费了太多的周期来进行数据库写入,这阻塞了系统。对 Postgres 的每次写入都是一次调用,这意味着如果我们想将 50 行保存到数据库中,而不是执行一次 SQL 调用来保存所有这 50 行,我们将每行调用 1 次!
根本原因:在 Hibernate 中使用 IDENTITY 生成 ID 值
为什么我们无法进行批量更新?事实证明,问题与我们如何使用 Hibernate 为数据库中的实体生成标识符值(AKA 主键)有关。
我们使用的方法涉及从 IDENTITY 列中检索值,当新实体插入数据库时,Hibernate 动态维护这些列。我们对新资源的数据库写入是在没有指定 id(主键)的情况下完成的,而是使用 GenerationType.IDENTITY。
这是我们的 Spring 实体的样子:
Kotlin
@Entity
@Table(name = "entity")
data class Entity(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null,
val metadata: String,
) : TenantEntity()
使用这种策略,使用 ORM 创建和更新现有资源非常简单:
- 如果没有传递 id,则会创建一个新行。
- 如果传递了 id,则会更新现有行。
听起来很简单,对吧?我们也是这么想的!而且它似乎运作良好——直到我们意识到使用 IDENTITY 引入了一个主要的性能问题。这种策略的缺点是批量更新不起作用。
这给我们带来了一个大问题,因为我们所有的实体都使用 IDENTITY 标识符值生成。对于我们现有的每个表及其对应的实体,我们必须将我们的策略从 IDENTITY 交换为支持批量插入语句的不同策略。
从 IDENTITY 迁移到基于序列的 ID 生成
在研究我们可以用于支持批处理的实体的其他生成类型时,我们遇到了 Hibernate 基于序列的标识符值生成。此策略由底层数据库序列支持。 Hibernate 将从序列中请求下一个可用的 id 以获取资源的新 id。
虽然此策略的基本机制超出了本文的范围,但底线是这种基于序列的策略将为我们启用批量插入。
现在我们需要弄清楚如何从现有的 IDENTITY 策略迁移到新的基于序列的方法。
在进一步调查后,我们意识到我们现有的表已经有一个 Postgres 序列。所以如果我们有一个这样定义的表:
CREATE TABLE IF NOT EXISTS entity (
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
...
…将创建一个名为 entity_id_seq 的序列!
您可以运行以下 SQL 命令来检查序列是否存在:
SELECT
*
FROM
pg_sequence
WHERE
seqrelid = 'entity_id_seq'::regclass;
由于我们能够轻松访问 Postgres 表的序列,因此我们可以进行本地化的更改以切换到使用基于序列的策略来生成 id。
对于每个实体,我们只需更改几行代码即可解决性能瓶颈。更新后的实体如下所示:
private const val TABLE = "entity"
private const val SEQUENCE = "${TABLE}_id_seq"
@Entity
@Table(name = TABLE)
data class Entity(
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = SEQUENCE)
@SequenceGenerator(name = SEQUENCE, sequenceName = SEQUENCE, allocationSize = 50)
@Column(name = "id")
val id: Long? = null,
val metadata: String,
) : TenantEntity()
AllocationSize 和序列增量大小
这里需要注意的一点是,Hibernate 中的 allocationSize 属性需要与 Postgres 中底层序列的增量大小相同。
这是为了让 Hibernate 和底层序列在他们持有的 id 方面不会“不同步”。这也可以防止多个服务器写入同一个表的分布式架构出现任何问题。
默认情况下,我们的 Postgres 序列的增量大小为 1。我们编写了一个非常快速的迁移来更改它以匹配我们的 allocationSize:
ALTER SEQUENCE entity_id_seq INCREMENT 50;
现在,Hibernate 只需要进行 1 次调用即可获取每 50 次插入的 id 列表。
它也只需要 1 次调用来插入这 50 行。
以下是我们从这个问题中学到的总结:
-
使用 Hibernate,请尽快开始使用基于数据库序列的身份值生成——尤其是在您预见到写入次数会增加的情况下。
-
保持 allocationSize 和底层 Postgres 序列增量大小参数相同,以避免 id 冲突并支持分布式系统。
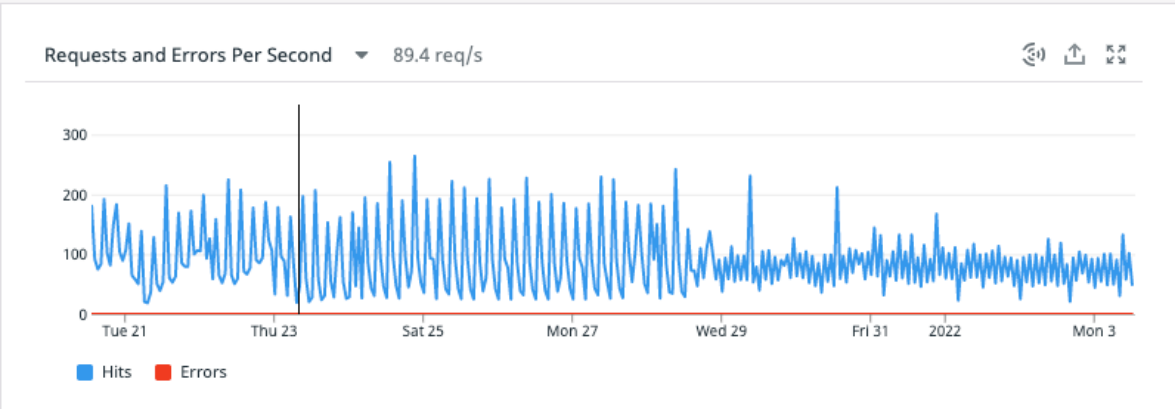
最后,这是我们执行此更改后 RPS 从接近 180 到大约 90 的屏幕截图。