




前言
本文总结如何只用SQL迁移关系型数据库中的表转化为Hudi表,这样的意义在于方便项目上对Spark、Hudi等不熟悉的人员运维。
Spark Thrift Server
首先将Orace的驱动拷贝至Spark jars目录下
启动Spark Thrift Server 扩展支持Hudi
/usr/hdp/3.1.0.0-78/spark2/bin/spark-submit --master yarn --deploy-mode client --executor-memory 2G --num-executors 6 --executor-cores 2 --driver-memory 4G --driver-cores 2 --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift-20003 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' --principal spark/indata-10-110-105-163.indata.com@INDATA.COM --keytab /etc/security/keytabs/spark.service.keytab --hiveconf hive.server2.thrift.http.port=20003 >~/server.log 2>&1 &
Beeline连接
/usr/hdp/3.1.0.0-78/spark2/bin/beeline -u "jdbc:hive2://10.110.105.163:20003/hudi;principal=HTTP/indata-10-110-105-163.indata.com@INDATA.COM?hive.server2.transport.mode=http;hive.server2.thrift.http.path=cliservice"
SQL 转化
首先建好Hive数据库
Oracle 表结构及数据
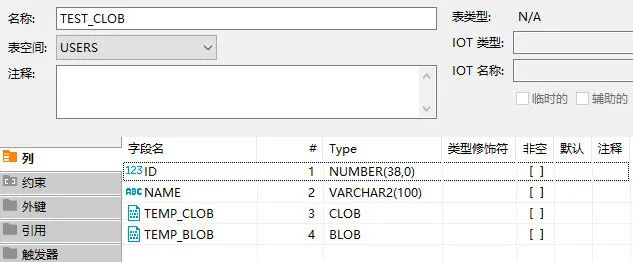
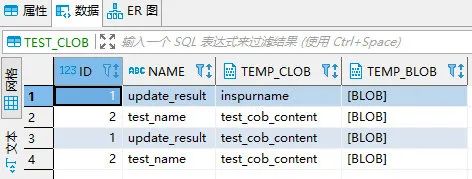
将Oracle表映射为临时表
CREATE TEMPORARY VIEW temp_test_clob
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:oracle:thin:@ip:1521:orcl",
dbtable "TEST_CLOB",
user 'userName',
password 'password'
);
字段类型字段匹配
Hudi Spark SQL 支持 CTAS语法
create table test_hudi.test_clob_oracle_sync using hudi options(primaryKey = 'ID',preCombineField = 'ID') as select * from temp_test_clob;
注意这里的ID为大写,是因为在Oracle表中的字段名为大写
show create table test_clob_oracle_sync;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE EXTERNAL TABLE `test_clob_oracle_sync`( |
| `_hoodie_commit_time` string COMMENT '', |
| `_hoodie_commit_seqno` string COMMENT '', |
| `_hoodie_record_key` string COMMENT '', |
| `_hoodie_partition_path` string COMMENT '', |
| `_hoodie_file_name` string COMMENT '', |
| `id` decimal(38,0) COMMENT '', |
| `name` string COMMENT '', |
| `temp_clob` string COMMENT '', |
| `temp_blob` binary COMMENT '') |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
| WITH SERDEPROPERTIES ( |
| 'hoodie.query.as.ro.table'='false', |
| 'path'='hdfs://cluster1/warehouse/tablespace/managed/hive/test_hudi.db/test_clob_oracle_sync') |
| STORED AS INPUTFORMAT |
| 'org.apache.hudi.hadoop.HoodieParquetInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
| LOCATION |
| 'hdfs://cluster1/warehouse/tablespace/managed/hive/test_hudi.db/test_clob_oracle_sync' |
| TBLPROPERTIES ( |
| 'last_commit_time_sync'='20220215112046', |
| 'spark.sql.sources.provider'='hudi', |
| 'spark.sql.sources.schema.numParts'='1', |
| 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"ID","type":"decimal(38,0)","nullable":true,"metadata":{}},{"name":"NAME","type":"string","nullable":true,"metadata":{}},{"name":"TEMP_CLOB","type":"string","nullable":true,"metadata":{}},{"name":"TEMP_BLOB","type":"binary","nullable":true,"metadata":{}}]}', |
| 'transient_lastDdlTime'='1644895263') |
+----------------------------------------------------+
select * from test_clob_oracle_sync;
+--------------------------------------------+---------------------------------------------+-------------------------------------------+-----------------------------------------------+----------------------------------------------------+---------------------------+-----------------------------+----------------------------------+----------------------------------+
| test_clob_oracle_sync._hoodie_commit_time | test_clob_oracle_sync._hoodie_commit_seqno | test_clob_oracle_sync._hoodie_record_key | test_clob_oracle_sync._hoodie_partition_path | test_clob_oracle_sync._hoodie_file_name | test_clob_oracle_sync.id | test_clob_oracle_sync.name | test_clob_oracle_sync.temp_clob | test_clob_oracle_sync.temp_blob |
+--------------------------------------------+---------------------------------------------+-------------------------------------------+-----------------------------------------------+----------------------------------------------------+---------------------------+-----------------------------+----------------------------------+----------------------------------+
| 20220215112046 | 20220215112046_0_1 | ID:1 | | 1a2d42c4-5d1e-404a-a09f-cf7705552634-0_0-2027-0_20220215112046.parquet | 1 | update_result | inspurname | |
| 20220215112046 | 20220215112046_1_1 | ID:2 | | b3e7ef23-01ee-4558-988b-a946f6947294-0_1-2028-0_20220215112046.parquet | 2 | test_name | test_cob_content | |
+--------------------------------------------+---------------------------------------------+-------------------------------------------+-----------------------------------------------+----------------------------------------------------+---------------------------+-----------------------------+----------------------------------+----------------------------------+
2 rows selected (0.531 seconds)
可以看到这里Spark为字段类型做了适配
提前建表
提前建表的好处是,字段类型可以自己掌握
create table test_hudi.test_clob_oracle_sync1(
id string,
name string,
temp_clob string,
temp_blob string
) using hudi
options (
primaryKey = 'id',
preCombineField = 'id',
type = 'cow'
);
insert into test_hudi.test_clob_oracle_sync1 select * from temp_test_clob;
show create table test_clob_oracle_sync1;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE TABLE `test_clob_oracle_sync1`( |
| `_hoodie_commit_time` string, |
| `_hoodie_commit_seqno` string, |
| `_hoodie_record_key` string, |
| `_hoodie_partition_path` string, |
| `_hoodie_file_name` string, |
| `id` string, |
| `name` string, |
| `temp_clob` string, |
| `temp_blob` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
| WITH SERDEPROPERTIES ( |
| 'path'='hdfs://cluster1/warehouse/tablespace/managed/hive/test_hudi.db/test_clob_oracle_sync1', |
| 'preCombineField'='id', |
| 'primaryKey'='id', |
| 'type'='cow') |
| STORED AS INPUTFORMAT |
| 'org.apache.hudi.hadoop.HoodieParquetInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
| LOCATION |
| 'hdfs://cluster1/warehouse/tablespace/managed/hive/test_hudi.db/test_clob_oracle_sync1' |
| TBLPROPERTIES ( |
| 'last_commit_time_sync'='20220215113952', |
| 'spark.sql.create.version'='2.4.5', |
| 'spark.sql.sources.provider'='hudi', |
| 'spark.sql.sources.schema.numParts'='1', |
| 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"id","type":"string","nullable":true,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"temp_clob","type":"string","nullable":true,"metadata":{}},{"name":"temp_blob","type":"string","nullable":true,"metadata":{}}]}', |
| 'transient_lastDdlTime'='1644896342') |
+----------------------------------------------------+
30 rows selected (0.178 seconds)
select * from test_clob_oracle_sync1;
+---------------------------------------------+----------------------------------------------+--------------------------------------------+------------------------------------------------+----------------------------------------------------+----------------------------+------------------------------+-----------------------------------+-----------------------------------+
| test_clob_oracle_sync1._hoodie_commit_time | test_clob_oracle_sync1._hoodie_commit_seqno | test_clob_oracle_sync1._hoodie_record_key | test_clob_oracle_sync1._hoodie_partition_path | test_clob_oracle_sync1._hoodie_file_name | test_clob_oracle_sync1.id | test_clob_oracle_sync1.name | test_clob_oracle_sync1.temp_clob | test_clob_oracle_sync1.temp_blob |
+---------------------------------------------+----------------------------------------------+--------------------------------------------+------------------------------------------------+----------------------------------------------------+----------------------------+------------------------------+-----------------------------------+-----------------------------------+
| 20220215113952 | 20220215113952_0_1 | id:1 | | a63e5288-7396-4303-8cd9-8a6ef6423932-0_0-73-3636_20220215113952.parquet | 1 | update_result | test_cob_content | |
| 20220215113952 | 20220215113952_0_2 | id:2 | | a63e5288-7396-4303-8cd9-8a6ef6423932-0_0-73-3636_20220215113952.parquet | 2 | test_name | test_cob_content | |
+---------------------------------------------+----------------------------------------------+--------------------------------------------+------------------------------------------------+----------------------------------------------------+----------------------------+------------------------------+-----------------------------------+-----------------------------------+
2 rows selected (0.385 seconds)
可以根据需求选择是否配置主键、分区字段等;另hudi0.9.0版本支持非主键表,当前0.10版本主键字段必填,未来的版本也许会有所变化
MySQL
CREATE TEMPORARY VIEW temp_mysql_table
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:mysql://ip:3306/default?useUnicode=true&characterEncoding=utf-8",
dbtable "taleName",
user 'userName',
password 'password'
)
文章转载自伦少的博客,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【MySQL 30周年庆】MySQL 8.0 OCP考试限时免费!教你免费领考券
墨天轮小教习
2913次阅读
2025-04-25 18:53:11
MySQL 30 周年庆!MySQL 8.4 认证免费考!这次是认真的。。。
严少安
845次阅读
2025-04-25 15:30:58
【纯干货】Oracle 19C RU 19.27 发布,如何快速升级和安装?
Lucifer三思而后行
676次阅读
2025-04-18 14:18:38
Oracle RAC 一键安装翻车?手把手教你如何排错!
Lucifer三思而后行
634次阅读
2025-04-15 17:24:06
Oracle数据库一键巡检并生成HTML结果,免费脚本速来下载!
陈举超
541次阅读
2025-04-20 10:07:02
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
491次阅读
2025-04-17 17:02:24
【ORACLE】记录一些ORACLE的merge into语句的BUG
DarkAthena
485次阅读
2025-04-22 00:20:37
【ORACLE】你以为的真的是你以为的么?--ORA-38104: Columns referenced in the ON Clause cannot be updated
DarkAthena
469次阅读
2025-04-22 00:13:51
一页概览:Oracle GoldenGate
甲骨文云技术
466次阅读
2025-04-30 12:17:56
MySQL 9.3 正式 GA,我却大失所望,新特性亮点与隐忧并存?
JiekeXu
429次阅读
2025-04-15 23:49:58




