




Oracle基础
Oracle数据类型
1.字符类型
字符串数据类型可以根据存储空间分为固定长度类型(CHAR)和
可变长度类型(VARCHAR2/NVARCHAR2)两种。
1.1.CHAR类型
CHAR类型,定长字符串,定长的原因是Oracle会使用空格将CHAR类型的字符串填充至最大容量。举个例子:
CHAR(10)
/*表示最大容量为10个字节,
但实际上如果只键入1个英文字符整个数据长度还是10字节,
后面会有9个空格
*/
复制
因此,一般会依据实际数据情况决定CHAR的容量。感觉很容易出问题
除此之外,如果在创表时不指定容量,则默认为CHAR(1)。这应该是正确用法,可以代表布尔值
CHAR最大容量为2000字节。
1.2.VARCHAR类型
和CHAR有所不同,他不会使用空格补齐,因此键入的数据长度是多少长度就是多少,当然还是可以设置容量的。
VARCHAR可以存储最多4000字节的数据。
1.3.NVARCHAR
使用了统一的unicode编码来存储字符串,不管是中文和英文都只占用一个字节。
2.数字类型
2.1.NUMBER类型
NUMBER(P,S)最为常见。
P是指precision,精度,表示有效数字的位数,最多不超过38位。
S是指scale,表示小数部分的精确度。
NUMBER既可以表示整数,也可以表示小数,强烈推荐。
2.2.INTEGER类型
顾名思义,只能存放整数,而且当插入小数时会做四舍五入。
2.3.浮点数
- 2.3.1. BINARY_FLOAT 类型
32位单精度。 - 2.3.2. BINARY_DOUBLE 类型
64位双精度。
3.日期
3.1.DATE类型
包含世纪、年、月、日、小时、分钟、秒。
一般占用7个字节。
日期值之间具有关联属性。
是最常用的数据类型之一
3.2.TIMESTAMP类型
会精确到毫秒级。
3.3.TIMESTAMP WITH LOCAL TIMEZONE类型
精确到毫秒级的同时还可以将时间数据根据数据库时区进行规范化。
4.LOB(large object)类型
4.1.CLOB(character large object)类型
二进制数据,存储单字节和多字节字符数据,最大容量4GB。???
4.2.BLOB(binary large object)类型
顾名思义,可以存储比特流,一般用来放图像、音视频等文件。最大容量4GB。
4.3.NCLOB类型
存储unicode类型数据,最大容量4GB。
5.LONG & RAW & LONG RAW类型
5.1.LONG类型
存储超长字符串。最大容量2GB。
5.2.LONG RAW类型
用来存储2GB的二进制数据。多用来存储多媒体文件。
5.3.RAW类型
相比于LONG RAW类型,他必须指定长度。
1.字符类型
字符串数据类型可以根据存储空间分为固定长度类型(CHAR)和
可变长度类型(VARCHAR2/NVARCHAR2)两种。
1.1.CHAR类型
CHAR类型,定长字符串,定长的原因是Oracle会使用空格将CHAR类型的字符串填充至最大容量。举个例子:CHAR(10) /*表示最大容量为10个字节, 但实际上如果只键入1个英文字符整个数据长度还是10字节, 后面会有9个空格 */复制因此,一般会依据实际数据情况决定CHAR的容量。
感觉很容易出问题
除此之外,如果在创表时不指定容量,则默认为CHAR(1)。这应该是正确用法,可以代表布尔值
CHAR最大容量为2000字节。1.2.VARCHAR类型
和CHAR有所不同,他不会使用空格补齐,因此键入的数据长度是多少长度就是多少,当然还是可以设置容量的。
VARCHAR可以存储最多4000字节的数据。1.3.NVARCHAR
使用了统一的unicode编码来存储字符串,不管是中文和英文都只占用一个字节。
2.数字类型
2.1.NUMBER类型
NUMBER(P,S)最为常见。
P是指precision,精度,表示有效数字的位数,最多不超过38位。
S是指scale,表示小数部分的精确度。
NUMBER既可以表示整数,也可以表示小数,强烈推荐。2.2.INTEGER类型
顾名思义,只能存放整数,而且当插入小数时会做四舍五入。2.3.浮点数
- 2.3.1. BINARY_FLOAT 类型
32位单精度。 - 2.3.2. BINARY_DOUBLE 类型
64位双精度。
- 2.3.1. BINARY_FLOAT 类型
3.日期
3.1.DATE类型
包含世纪、年、月、日、小时、分钟、秒。
一般占用7个字节。
日期值之间具有关联属性。
是最常用的数据类型之一3.2.TIMESTAMP类型
会精确到毫秒级。3.3.TIMESTAMP WITH LOCAL TIMEZONE类型
精确到毫秒级的同时还可以将时间数据根据数据库时区进行规范化。
4.LOB(large object)类型
4.1.CLOB(character large object)类型
二进制数据,存储单字节和多字节字符数据,最大容量4GB。???4.2.BLOB(binary large object)类型
顾名思义,可以存储比特流,一般用来放图像、音视频等文件。最大容量4GB。4.3.NCLOB类型
存储unicode类型数据,最大容量4GB。
5.LONG & RAW & LONG RAW类型
5.1.LONG类型
存储超长字符串。最大容量2GB。5.2.LONG RAW类型
用来存储2GB的二进制数据。多用来存储多媒体文件。5.3.RAW类型
相比于LONG RAW类型,他必须指定长度。
SQL(structured query language)基础
基本分类
- 1.DQL(data query language)数据查询语言:SELECT FROM WHERE 注意,SELECT后面跟的表头列表我们一般称为“投影列”
- 2.DML(data manipulation language)数据操作语言
- 3.TCL(transaction control language)事务处理语言
- 4.DCL(data control language)数据控制语言
- 5.DDL(data definition language)数据定义语言
DQL基本语法细节
1.文字字符串
是包含在SELECT列表中的字符串、数字或日期。
- 由日期或者字符构成的文字字符串必须使用''括起来,数字字符串则不需要
- 每个文字字符串在每行只输出一次
2.distinct的一些细节
- 1.DISTINCT只能出现在SELECT关键字的后面
- 2.当DISTINCT同时修饰两列数据时,两列数据构成的整体是去重的,但不能保证单列数据去重
3.如何显示表结构?
DESC table_name /*describe*/
复制
4.表达式优先级
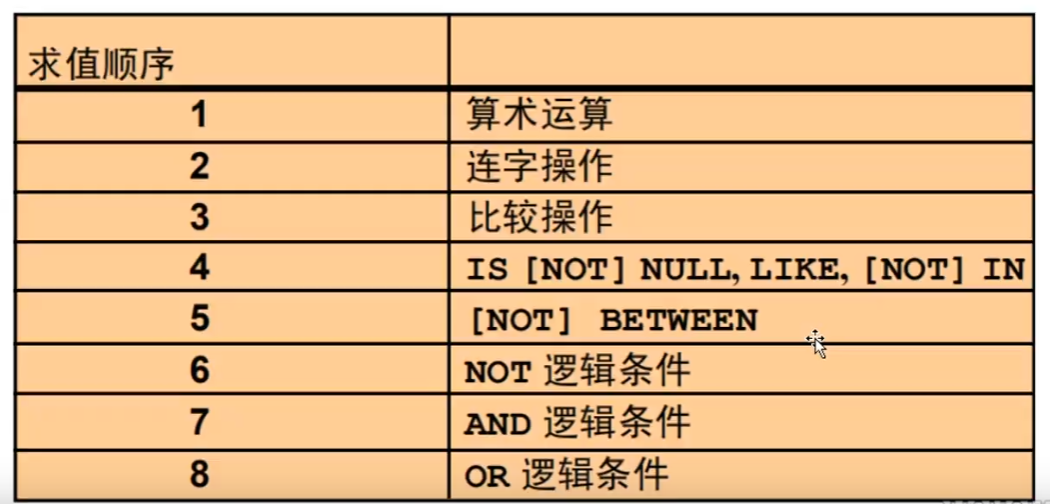
5.ORDER BY相关
- 记住一定只能跟在SELECT语句的最后位置
- 升序:ASC,降序:DESC
6.SELECT语句底层执行顺序
- 1.FROM
- 2.WHERE
- 3.SELECT
- 4.ORDER BY
1.文字字符串
是包含在SELECT列表中的字符串、数字或日期。
- 由日期或者字符构成的文字字符串必须使用''括起来,数字字符串则不需要
- 每个文字字符串在每行只输出一次
2.distinct的一些细节
- 1.DISTINCT只能出现在SELECT关键字的后面
- 2.当DISTINCT同时修饰两列数据时,两列数据构成的整体是去重的,但不能保证单列数据去重
3.如何显示表结构?
DESC table_name /*describe*/
4.表达式优先级
5.ORDER BY相关
- 记住一定只能跟在SELECT语句的最后位置
- 升序:ASC,降序:DESC
6.SELECT语句底层执行顺序
- 1.FROM
- 2.WHERE
- 3.SELECT
- 4.ORDER BY
DQL的function函数
- 1.函数语法
function_name(argument_1,argumenet_2,......)
2.分类
- 单行函数
仅对单个行进行运算,并且每行返回一个结果
1.字符函数
大小写处理函数
- LOWER('sql string')
- UPPER('sql string')
- INITCAP('sql string') 将每个单词的首个字母转为大写,其他字母转为小写
字符处理函数
首先要理解一下什么是dual表以及它的作用。什么是dual表
dual表是指只含有一个字段且只有一行记录的表,亦称为“伪表”,而确实也不构成我们所熟知的表结构。作用
当数据库引擎发现用户在SELET语句处理dual表时,数据库引擎会跳过查询过程,以此节约开销。
这个特性用来做单纯处理数据,而不进行查询的操作时格外合适。
即字符处理函数的语法格式需要借助dual表实现。CONCAT('hello','world') --> 'helloworld'
SUBSTR('helloWorld',1,5) --> 'hello' 注意与传统编程语言的区别!下标从1开始;参数为-1则从末尾进行截取
LENGTH('helloWorld') --> 10
INSTR('helloWorld','W',2,1) --> 6 返回字符串从第2个字符开始查,'W'的第一次出现起始位置,后面两个参数可省略
LPAD(salary,10,'*') --> *****24000 起左侧填充作用,10指的是填充后的总长度
RPAD(salary,10,'*') --> 24000*****
TRIM(both|leading|trailing 'H' FROM 'HelloWorld') --> elloWorld 类似于Java中的trim,将H从字符串中截取删除
REPLACE(arg1,arg2,arg3) --> ar1 原字符串,arg2 原字符串中要替换的内容,arg3 替换后的内容
举例:
select replace('12345678910',substr('12345678910',4,4),'****') from dual /*将11位手机号中间4位替换为**/复制
2.数字函数
- ROUND:四舍五入指定小数
round(45.926,2) /*45.93*/复制- TRUNC:截断指定小数的值
trunc(45.926,2) /*45.92*/复制- MOD: 取余
mod(1600,300) /*100*/复制3.日期函数
SYSDATE 直接返回当前服务器的日期和时间
运算 结果 说明 date+number date 一个日期+一个天数 date-number date 一个日期-一个天数 date-date number 一个日期-一个日期 date+number/24 date 一个日期+天数/24 MONTHS_BETWEEN(date1,date2) 计算两个日期之间的月数,存在正负性 注意:oracle在处理日期类型时是精度运算,所以结果全是浮点数
ADD_MONTHS(date,n)
NEXT_DAY(date,'char')返回距离当前date最近的下一周的星期几的日期,如果使用数字表示第二个参数,则数字1代表星期日,范围是1~7
LAST_DAY(date)**返回包含date的月中的最后一天的日期 **
ROUND(date,'fmt')这个有点难理解,举个例子
当sysdate为2022/3/21=,且'fmt'为'year',则返回值为2022/1/1
当sysdate为2022/12/22时,且'fmt'为'year',则返回值为2023/1/1
换句话说,当前的date会根据fmt进行四舍五入。
若fmt参数被忽略,则date会被四舍五入至最近的天。fmt可以为''year','month','day'TRUNC(date,'fmt') 类似于ROUND,不过仅仅会对date根据fmt进行截断
4.转换函数
- 隐式转换:字符串<->NUMBER/DATE,注意!隐式转换会导致索引失效,导致性能问题
- 显式转换:
- TO_CHAR(arg1,'fmt') 其中fmt在处理不同数据类型时有不同的模板
- TO_NUMBER(arg1,'fmt')
- TO_DATE(arg1,'fmt')
5.通用函数
NVL(expr1,expr2) 若expr1为null,则给expr1赋予expr2的值
NVL2(expr1,expr2,expr3) 若expr1不为null,则返回expr2;若expr1为null,则返回expr3
NULLIF(expr1,expr2) 比较两个参数,若相等,则返回null;若不想等,则返回expr1
COALSECE(expr1,expr2,....) 返回表达式列表中第一个非空的值
CASE 类似于if then else 结构,具体语法如下:

DECODE

其实就是简化版的CASE
多行函数(聚合函数)
AVG(arg)
SUM(arg)
COUNT(arg)
MIN(arg)
MAX(arg)
能够操纵成组的行,每个行组计算出结果,因此亦称为组函数。
单行函数会对查询到的每一个结果集做处理,而组函数只对分组数据做处理。
单行函数对每个结果集返回一个结果,而组函数对与每个结果集只返回一个结果。
有点复杂,但其实画个图就理解了。上图: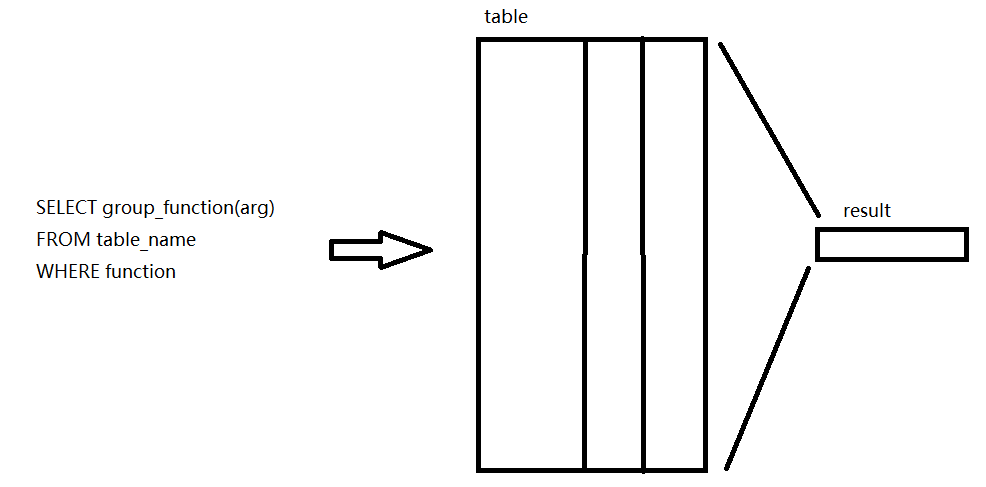
这种是不带GROUP BY进行分组操作的多行函数的处理过程。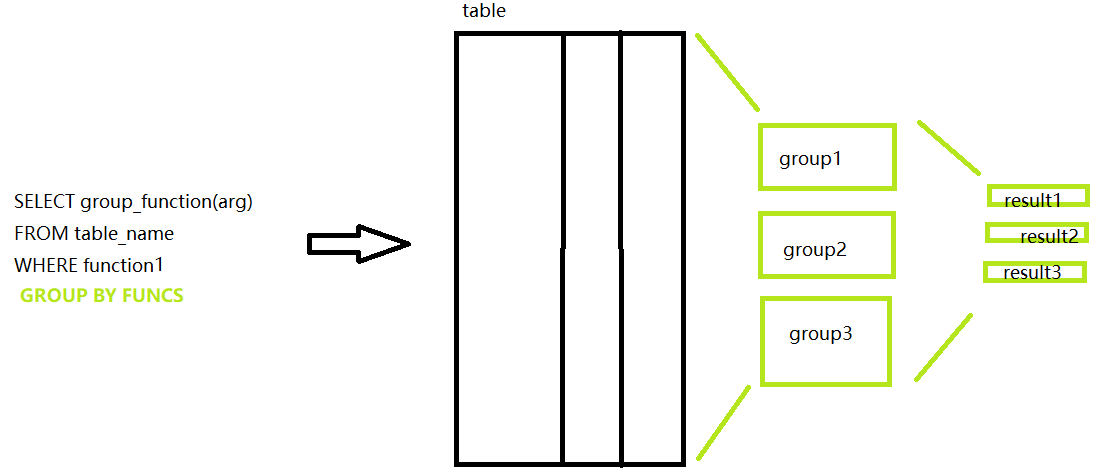
这种时聚合函数搭配GROUP BY使用的处理过程这也是为什么GROUP BY的对象一定是聚合函数中的参数的根本原因
注意,sql中所有聚合函数都只能位于投影列、having或者compute语句中中HAVING的作用
HAVING弥补了WHERE关键字无法与聚合函数同时使用的不足。
HAVING 约束条件过滤的是GROUP BY语句返回的最后的结果,相当于是最后一个约束条件
当然,绝对不能也无法在聚合函数中使用WHERE关键字
DML一定与事务绑定
- INSERT语法
INSERT INTO table_name (col1,col2,...)
VALUES (val1,val2,...);
复制
INSERT INTO table_name (col1,col2,...)
VALUES (val1,val2,...);
注意,当插入日期时,最好使用to_date('date_str','fmt')来插入正确的sql日期
- UPDATE语法
UPDATE table_name SET column1 = value1,column2 = value2,... WHERE condition;复制
- DELETE语法
DELETE FROM table_name WHERE condition;复制
- 什么是事务
事务中的一系列操作,要么都执行,要么都不执行。- 原子性
要么全做,要么都不做。 - 一致性
是原子性的延伸,我往银行冲了500块,我老婆马上取出了这500块,那账户上数据应该不变,这种“数据守恒”就叫做一致性,
本质就是原子性存在的意义.原子性就是为了一致性 - 隔离性
一个事务的执行不被另一个事务的执行干扰。 - 持续性(永久性)
持续性也称为永久性,指一个事务一旦提交,它对数据库中数据的改变是永久性的。
- 原子性
TCL语法
1.COMMIT
2.ROLLBACK
3.设置回滚点
- SAVEPOINT point_name;
- ROLLBACK TO point_name;
1.COMMIT
2.ROLLBACK
3.设置回滚点
- SAVEPOINT point_name;
- ROLLBACK TO point_name;
PROCEDURE存储过程
- 什么是存储过程
首先存储过程是存储在数据库中,为了玩成特定功能的的sql语句集。特点是编译一次后再次调用是无需再次编译。
通俗点说就是专门干一个sql流程的“语句”。 - 优点
首先存储过程是存储在数据库中,为了玩成特定功能的的sql语句集。特点是编译一次后再次调用是无需再次编译。
通俗点说就是专门干一个sql流程的“语句”。
1.效率高
存储过程编译一次后,就会存到数据库,每次调用时都直接执行。而普通的sql语句我们要保存到其他地方(例如:记事本 上),都要先分析编译才会执行。所以想对而言存储过程效率更高。
2.降低占用
存储过程编译好会放在数据库,我们在远程调用时,不会传输大量的字符串类型的sql语句。
3.复用性高
存储过程往往是针对一个特定的功能编写的,当再需要完成这个特定的功能时,可以再次调用该存储过程。
4.可维护性高
当功能要求发生小的变化时,修改之前的存储过程比较容易,花费精力少。
5.安全性高
完成某个特定功能的存储过程一般只有特定的用户可以使用,具有使用身份限制,更安全。
- 具体语法
--无参 CREATE OR REPLACE PROCEDURE demo AS variable1 DATE; variable2 NUMBER; BEGIN --这里写业务逻辑 EXCEPTION --抛出异常 END --有参 CREATE OR REPLACE PROCEDURE demo2(param1 IN student.id%TYPE) AS /* IN指的是这个参数是输入参数,参数默认都是输入参数; 如果有OUT修饰,则为输出参数。 */ variable1 DATE;--注意语法很特殊,变量类型放在后面 variable2 NUMBER :=20;--:=就是赋值 BEGIN --这里写业务逻辑 EXCEPTION --抛出异常 END复制
/*增加表空间大小的方式*/ ALTER DATABASE DATAFILE 'databaseFileName.DBF' RESIZE 100M; /*查询表空间的位置*/ SELECT * FROM Dba_Data_Files WHERE Dba_Data_Files.tablespace_name = 'tablespaceName';复制
数据泵
各种参数
太多了用到再整理
数据泵表的备份恢复
1.在使用数据泵进行导入导出之前,需要先建立备份恢复的目录。
具体步骤如下:
- 1.mkdir dmpbak
- 2.进入oracle数据库命令行,输入指令:
--指定备份恢复的文件夹路径
create or replace directory dmbak as '/***/**/*/dmpbak';
--授予权限
grant all on directory dmpbak to public;
复制
2.EXPDP:导出
--注意,不要在末尾加;
expdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=expdp_emp_dept.log tables=table1,table2
复制
job结束后会在备份恢复文件中产生.dump文件和.log文件。
3.IMPDP:导入
假如我在数据库中不小心删除了table1和table2两个表,现在我有备份就很安心。
恢复的操作如下:
--注意,导入要匹配之前导出的dump文件,日志文件则要重新命名,末尾也不要加;
impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log TABLE_EXISTS_ACTION=
复制
1.在使用数据泵进行导入导出之前,需要先建立备份恢复的目录。
具体步骤如下:
- 1.mkdir dmpbak
- 2.进入oracle数据库命令行,输入指令:
--指定备份恢复的文件夹路径 create or replace directory dmbak as '/***/**/*/dmpbak'; --授予权限 grant all on directory dmpbak to public;复制
2.EXPDP:导出
--注意,不要在末尾加; expdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=expdp_emp_dept.log tables=table1,table2复制
job结束后会在备份恢复文件中产生.dump文件和.log文件。
3.IMPDP:导入
假如我在数据库中不小心删除了table1和table2两个表,现在我有备份就很安心。
恢复的操作如下:
--注意,导入要匹配之前导出的dump文件,日志文件则要重新命名,末尾也不要加; impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log TABLE_EXISTS_ACTION=复制
{SKIP|APPEND|TRUNCATE|REPLACE}
```
数据泵用户的备份恢复
- 1.EXPDP:
expdp username/passwd directory=dmpbak dumpfile=scott.dump logfile=scott.log schema=username
复制
- 2.IMPDP:
--第一种
impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log remap_schema=username:newname
--第二种
impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log schemas=username
复制
expdp username/passwd directory=dmpbak dumpfile=scott.dump logfile=scott.log schema=username复制
--第一种 impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log remap_schema=username:newname --第二种 impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=expdp_emp_dept.dmp logfile=impdp_emp_dept.log schemas=username复制
数据泵全库的备份恢复(迁移)
```sql
expdp username/passwd ip:port@dbname directory=dmpbak dumpfile=full.dmp full=y logfile=expdp_full.log
impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=full.dmp full=y logfile=impdp_full.log
```复制
```sql
expdp username/passwd ip:port@dbname directory=dmpbak dumpfile=full.dmp full=y logfile=expdp_full.log
impdp username/passwd ip:port@dbname directory=dmpbak dumpfile=full.dmp full=y logfile=impdp_full.log
```


