




译者简介
李鑫&崔鹏&海能达DBA团队,任职于海能达通信股份有限公司哈尔滨平台中心,数据库开发高级工程师,致力于postgresql数据库在专网通信领域、公共安全领域的应用与推广,个人兴趣主要集中在:分布式数据库系统设计、高并发高可用数据库架构设计与开源数据库的源码研究。
校对者简介
赵全明 任职于华为技术有限公司,数据库内核开发工程师,参与RDS for PostgreSQL管控及GaussDB多个版本的研发,致力于PostgreSQL在全行业的应用与推广。
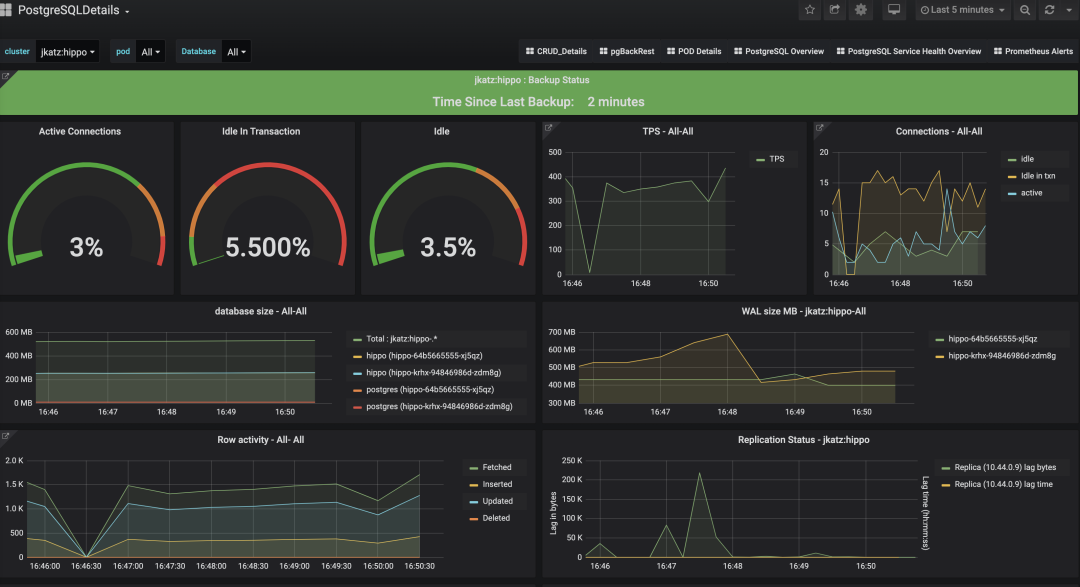
连接统计
总连接数
闲置事务
事务率
行活动
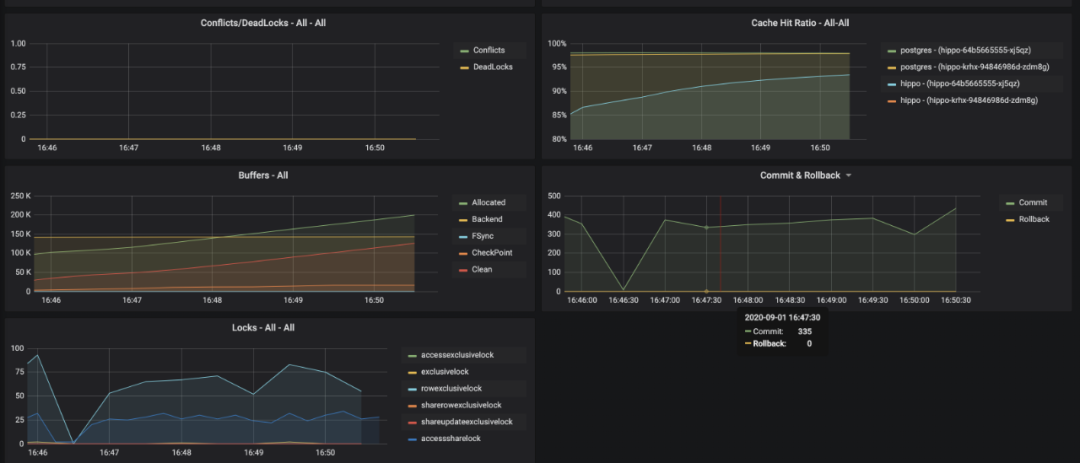
缓存命中率
锁
复制滞后
备份
结论

文章转载自PostgreSQL中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
